
«`html
Технология распознавания речи
Технология распознавания речи фокусируется на преобразовании устной речи в текст. Она включает в себя процессы, такие как акустическое моделирование, языковое моделирование и декодирование, нацеленные на достижение высокой точности в транскрипции. Значительные прогрессивные достижения в этой области были сделаны благодаря алгоритмам машинного обучения и большим наборам данных. Эти достижения позволяют создавать более точные и эффективные системы распознавания речи, которые являются критически важными для различных приложений, таких как виртуальные помощники, транскрипционные сервисы и инструменты доступности.
Исправление ошибок в системах автоматического распознавания речи
Одной из основных проблем в распознавании речи является исправление ошибок, генерируемых системами автоматического распознавания речи (ASR). Традиционные языковые модели (LMs), интегрированные с ASR системами, часто требуют учета конкретных ошибок, что приводит к субоптимальной производительности. Эффективные модели исправления ошибок, способные точно исправлять эти ошибки без обширных данных для обучения под наблюдением, остаются критической проблемой.
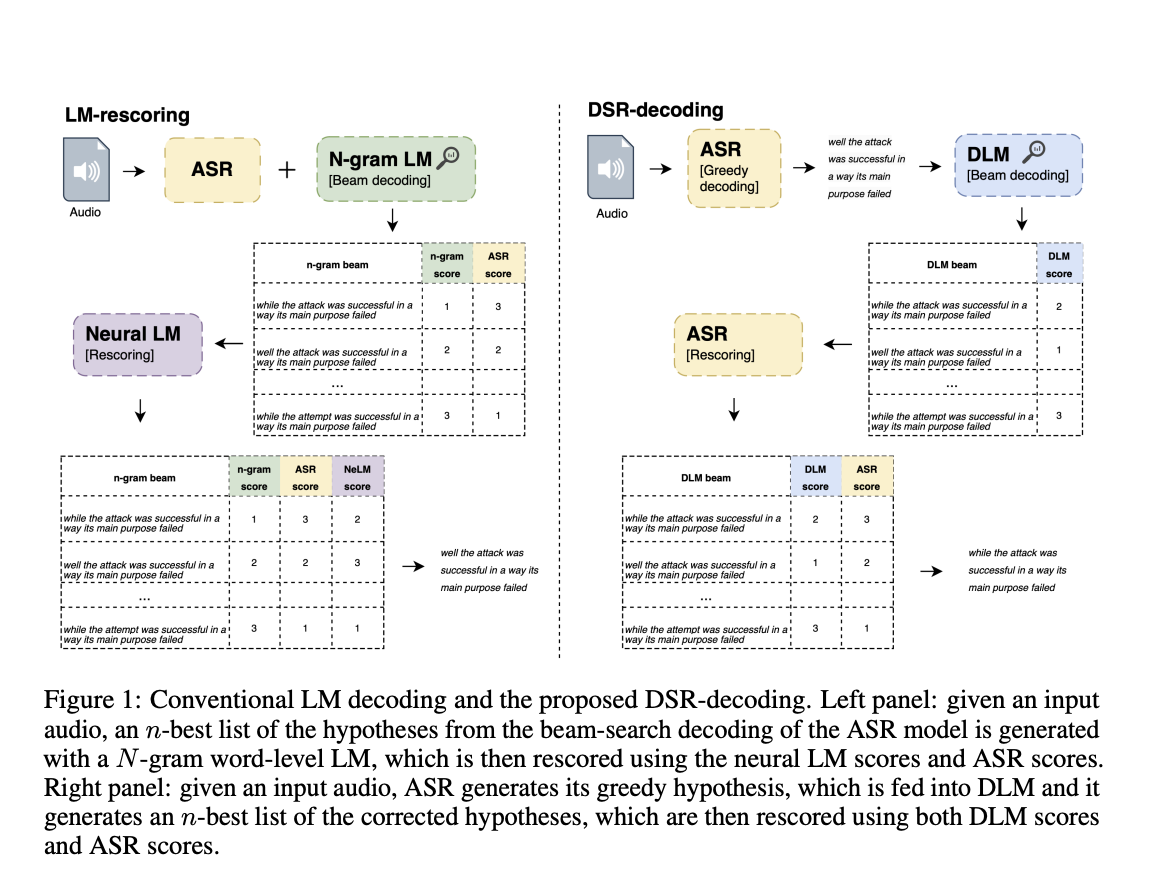
Модель исправления ошибок Denoising LM (DLM)
Исследователи из Apple представили Denoising LM (DLM), передовую модель исправления ошибок, разработанную исследовательской группой в Apple. DLM использует огромные объемы синтетических данных, сгенерированных системами TTS, для эффективного обучения модели. Этот подход значительно превосходит предыдущие попытки и достигает современной производительности в системах ASR.
Результаты и потенциал DLM
DLM продемонстрировала впечатляющую производительность, достигнув 1,5% коэффициента ошибок слов (WER) на тестовом наборе данных Librispeech и 3,3% на другом тестовом наборе данных. Эти результаты значительны, поскольку они соответствуют или превосходят производительность традиционных LMs и даже некоторых методов самообучения, использующих внешние аудиоданные. Способность DLM значительно улучшить точность ASR подчеркивает ее потенциал заменить традиционные LMs в системах ASR.
Заключение
Исследование подчеркивает эффективность DLM в устранении ошибок ASR путем использования синтетических данных для обучения. Предложенный метод не только повышает точность, но также демонстрирует масштабируемость и универсальность в различных системах ASR. Этот инновационный подход является значительным прогрессом в распознавании речи и обещает более точные и надежные системы ASR в будущем.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпишитесь на наш ML SubReddit. Также ознакомьтесь с нашей платформой AI Events AI Events Platform.
Статья опубликована на портале MarkTechPost.
«`





















