
«`html
LLM-QFA Framework: Уменьшение затрат на обучение для развертывания больших языковых моделей (LLMs) в различных сценариях
Большие языковые модели (LLMs) демонстрируют значительные прорывы в обработке естественного языка, но сталкиваются с проблемами из-за требований к памяти и вычислительным ресурсам. Традиционные методы квантизации уменьшают размер модели за счет уменьшения битовой глубины весов, что помогает смягчить эти проблемы, но часто приводит к потере производительности. Проблема усугубляется, когда LLM используется в различных ситуациях с ограниченными ресурсами. Это означает, что квантизационное обучение (QAT) должно быть проведено многократно для каждого применения, что требует больших ресурсов.
Решение:
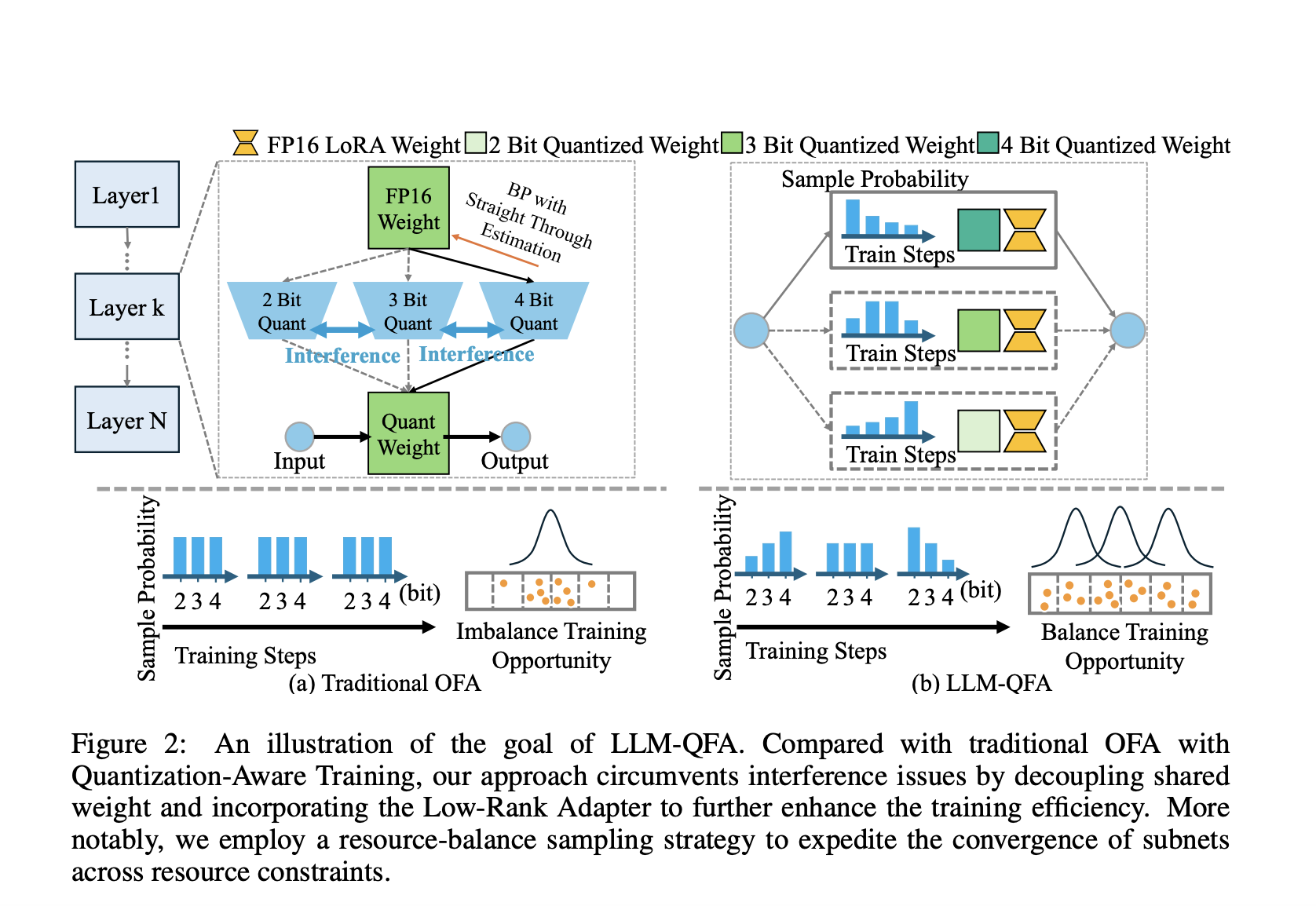
Исследователи из South China University of Technology, Hong Kong University of Science and Technology, Tsinghua University и Salesforce AI Research предлагают LLM-QFA (Quantization-Aware Fine-tuning once-for-all for LLMs) для решения этих неэффективностей. Данный подход обучает один «раз и навсегда» суперсет способный генерировать различные оптимальные подсети, настроенные для различных сценариев развертывания без повторного обучения.
Практические решения и ценность:
LLM-QFA справляется с проблемами, вызванными весовым совместным использованием в традиционном QAT, разделяя веса различных конфигураций квантизации с помощью lightweight Low-Rank адаптеров. Этот подход позволяет избежать вмешательства между конфигурациями и вовлечения незначительных дополнительных вычислительных затрат. Также LLM-QFA применяет стратегию сбалансированного распределения ресурсов, что способствует оптимизации всех подсетей и обеспечивает устойчивую производительность в различных условиях ограниченных ресурсов.
Результаты показали, что LLM-QFA способен поддерживать высокую производительность, существенно сокращая время развертывания по сравнению с традиционными методами QAT. В частности, на MMLU-бенчмарке LLM-QFA превзошел методы GPTQ и QA-LoRA, особенно при средних ограничениях битовой глубины, достигая хорошего баланса между производительностью и эффективностью ресурсов. Также LLM-QFA показал последовательные улучшения на бенчмарке Common Sense QA, подтверждая его эффективность в различных сценариях развертывания.
В заключение, исследование решает критический вопрос эффективного развертывания больших языковых моделей в различных условиях ограниченных ресурсов. Предложенный подход значительно снижает вычислительные затраты, связанные с традиционными методами QAT, при этом поддерживая и улучшая производительность. Этот подход делает LLM более адаптивными и эффективными для реальных приложений, даже на ресурсоограниченных устройствах.
Подробнее ознакомьтесь с исследованием. Все заслуги за это исследование принадлежат его авторам.
Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с ML сообществом. Также обратите внимание на нашу платформу AI Events.
Оптимизируйте работу своей компании с помощью ИИ, следуя советам и решениям от AI Lab itinai.ru. Будущее уже здесь!
«`



















