
«`html
Улучшение производительности и эффективности моделей языковых моделей с помощью обрезки данных на основе недоумения
В машинном обучении часто фокусируются на улучшении производительности больших языковых моделей (LLM) при снижении затрат на обучение. Одним из способов достижения этой цели является обрезка данных, которая позволяет выбирать высококачественные подмножества из больших наборов данных для более эффективного обучения моделей. Этот процесс гарантирует, что модели обучаются на чистых и актуальных данных, что улучшает их производительность.
Проблема и решение
Одной из проблем обучения LLM является наличие обширных и часто зашумленных наборов данных. Низкое качество данных может существенно снизить производительность этих моделей, поэтому важно разрабатывать методы фильтрации низкокачественных данных. Эффективная обрезка данных необходима для оптимизации обучения этих моделей, что позволяет использовать только лучшие данные и улучшает точность и эффективность модели.
Традиционные методы обрезки данных включают простые правила фильтрации и базовые классификаторы для выявления высококачественных образцов. Однако эти методы часто ограничены в обработке масштабных и разнообразных наборов данных. Появились более продвинутые техники, использующие эвристику на основе нейронных сетей для оценки качества данных на основе различных метрик, таких как сходство признаков или сложность образца.
Исследователи из Databricks, MIT и DatologyAI предложили инновационный подход к обрезке данных с использованием небольших эталонных моделей для вычисления недоумения текстовых образцов. Этот подход начинается с обучения небольшой модели на случайном подмножестве данных, которая затем оценивает недоумение каждого образца. Низкие оценки недоумения указывают на высококачественные данные. Фокус на образцах с наименьшими оценками недоумения позволяет обрезать набор данных, оставляя только наиболее актуальные данные и улучшая производительность более крупных моделей, обученных на этих обрезанных данных.
Практическое применение
Методика включает разделение набора данных на обучающие и проверочные наборы для небольшой эталонной модели. Эта модель обучается на стандартной цели предсказания следующего токена, вычисляя оценки недоумения для каждого образца в наборе данных. Набор данных затем обрезается на основе этих оценок, выбирая образцы в определенном диапазоне недоумения. Например, образцы с наименьшим недоумением выбираются с использованием низкого критерия выбора. Этот обрезанный набор данных затем используется для обучения окончательной, более крупной модели, которая получает преимущества от высококачественных данных.
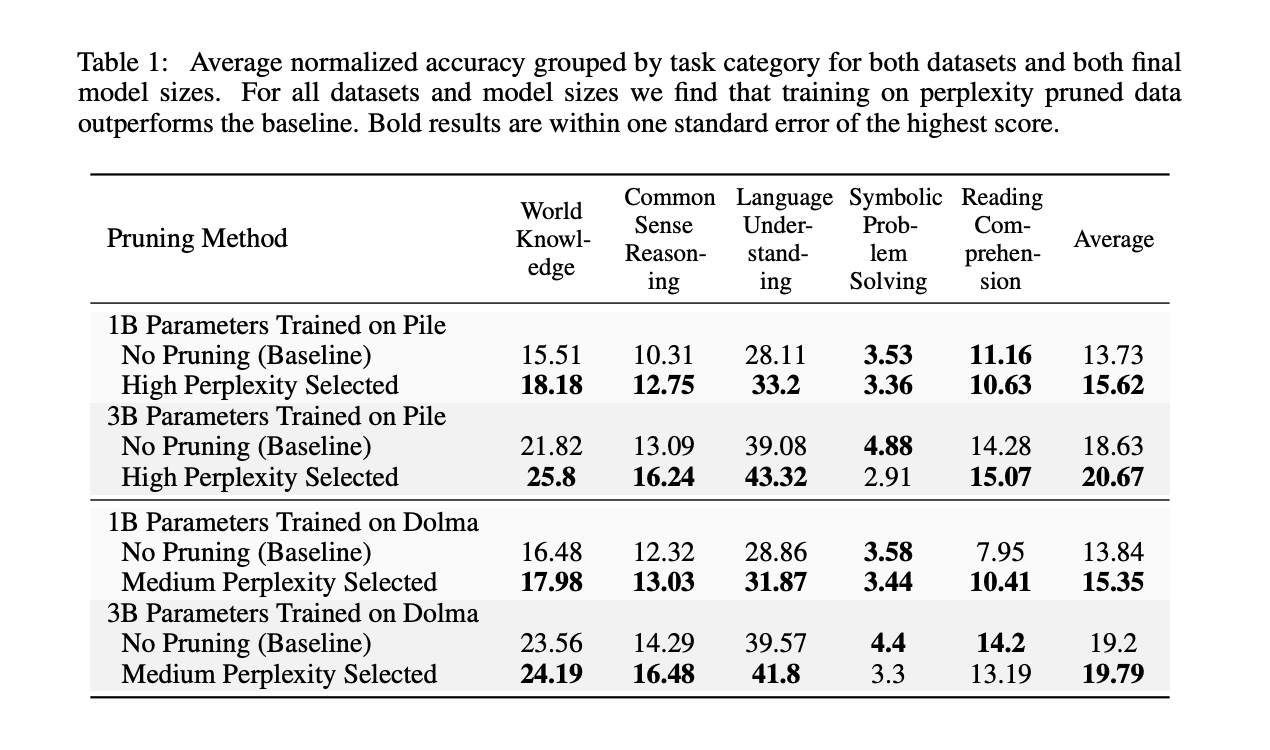
Обрезка данных на основе недоумения значительно улучшает производительность LLM на последующих задачах. Например, обрезка на основе оценок недоумения, вычисленных с помощью модели с 125 миллионами параметров, улучшила среднюю производительность на последующих функциях модели с 3 миллиардами параметров на 2,04%. Кроме того, она позволила сократить количество шагов предварительного обучения до сопоставимой базовой производительности в 1,45 раза. Метод также доказал свою эффективность в различных сценариях, включая переобученные и ограниченные режимы.
Это исследование подчеркивает полезность небольших эталонных моделей в обрезке данных на основе недоумения, предлагая значительный шаг вперед в оптимизации обучения LLM. Исследователи могут улучшить производительность модели и эффективность обучения, используя более маленькие модели для фильтрации низкокачественных данных. Этот метод представляет собой многообещающий инструмент для исследователей данных, показавший улучшение производительности на 1,89 для Pile и 1,51 для Dolma при обучении в оптимальное время. Он улучшает производительность крупномасштабных языковых моделей и снижает требуемые вычислительные ресурсы, что делает его ценным дополнением к современному инструментарию исследователя данных.
Заключение
Исследование представляет новый и эффективный метод обрезки данных с использованием небольших эталонных моделей для вычисления недоумения. Этот подход улучшает производительность и эффективность больших языковых моделей, обеспечивая использование высококачественных предварительных данных. Устойчивость метода в различных составах данных и режимах обучения подчеркивает его потенциал как основной техники для современных исследований данных. Оптимизируя качество данных, исследователи могут достичь лучшей производительности модели с меньшими ресурсами, что делает обрезку данных на основе недоумения ценным методом для будущих достижений в области машинного обучения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, группе в Discord и LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с более чем 43 тыс. подписчиков. Также ознакомьтесь с нашей платформой AI Events.
Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию. Попробуйте AI Sales Bot.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. itinai.ru будущее уже здесь!
«`



















