
«`html
Применение Demonstration ITerated Task Optimization (DITTO) в вашем бизнесе
Language models (LMs) предназначены для отражения широкого спектра голосов, в результате чего их выводы не идеально соответствуют ни одной конкретной перспективе. Для избежания общих ответов можно использовать LLMs через отслеживаемую донастройку (SFT) или обучение с подкреплением с помощью обратной связи от человека (RLHF). Однако эти методы требуют огромных наборов данных, что делает их непрактичными для новых и конкретных задач. Кроме того, часто имеется несоответствие между универсальным стилем, обученным в LLM, и настройкой предпочтений, необходимой для конкретных приложений. Это несоответствие приводит к тому, что выводы LLM кажутся общими и лишены выразительного голоса.
Решения и практические применения
Для решения этих проблем было разработано несколько методов. Один из подходов включает LLM и донастройку предпочтений, при которой LLM обучают на огромных наборах данных для успешной работы с аккуратными подсказками. Однако конструирование подсказок может быть сложным и чувствительным к изменениям, поэтому часто необходимо донастраивать эти модели на больших наборах данных и использовать RLHF. Еще одной стратегией является самосовершенствование, где для улучшения LLM используется итерационная выборка. Например, методы, такие как STaR, контролируются путем проверки правильности их выводов. Наконец, метод онлайн имитационного обучения может улучшить политику вне производительности демонстратора. Однако эти подходы требуют изучения функции вознаграждения и не применимы к LLM.
Применение в различных областях
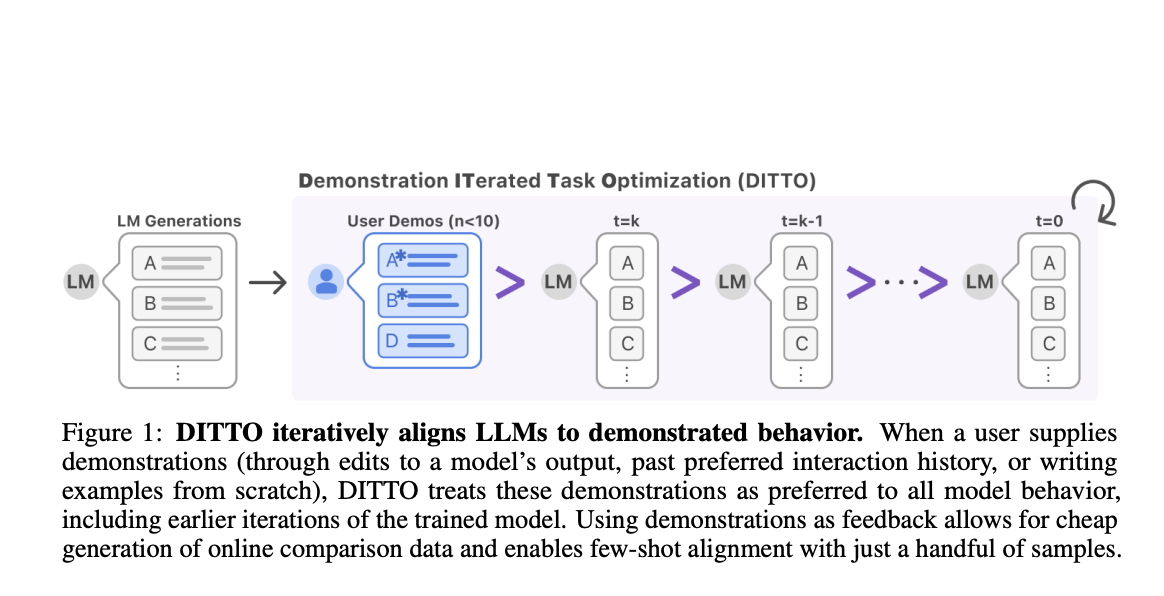
Исследователи из Стэнфордского университета представили метод Demonstration ITerated Task Optimization (DITTO), который призван направлять выводы языковых моделей непосредственно с поведением пользователя. DITTO способен учиться тонкой настройке стиля и выравниванию задач в различных областях, таких как новостные статьи, электронные письма и блоги. Это итеративный процесс, включающий выполнение донастройки под контролем экспертных демонстраций, конструирование нового набора данных в процессе обучения и использование обновления политики с использованием RLHF. Результаты DITTO превосходят все базовые методы средним показателем победы в 77,09%, что обеспечивает средний прирост в 11,7% по сравнению с SFT. Кроме того, в исследованиях пользователей DITTO превосходит методы базовой линии, а также показывает преимущество над самоподдерживающими действиями и недостатками DITTO.
Вывод
Исследователи из Стэнфордского университета представили метод Demonstration ITerated Task Optimization (DITTO), который выравнивает выводы языковых моделей непосредственно с поведением пользователя. Для будущей работы в этой области требуется дополнительный анализ типов предпочтений, а также проверка других размеров моделей.
Подробнее ознакомиться с публикацией и лабораторией.
Все авторские права на это исследование принадлежат его создателям.
Если вам нужны советы по внедрению ИИ, пишите нам на нашем канале.
«`


















