
Zyda Dataset: A 1.3 Trillion Token Dataset for Open Language Modeling
Zyphra представила Zyda, инновационный набор данных для языкового моделирования, состоящий из 1,3 триллиона токенов. Этот набор данных призван переопределить стандарты обучения и исследований языковых моделей благодаря своему размеру, качеству и доступности.
Основные особенности Zyda:
- Беспрецедентное количество токенов: 1,3 триллиона токенов, отфильтрованных и дедуплицированных для достижения высочайшей точности и надежности моделей.
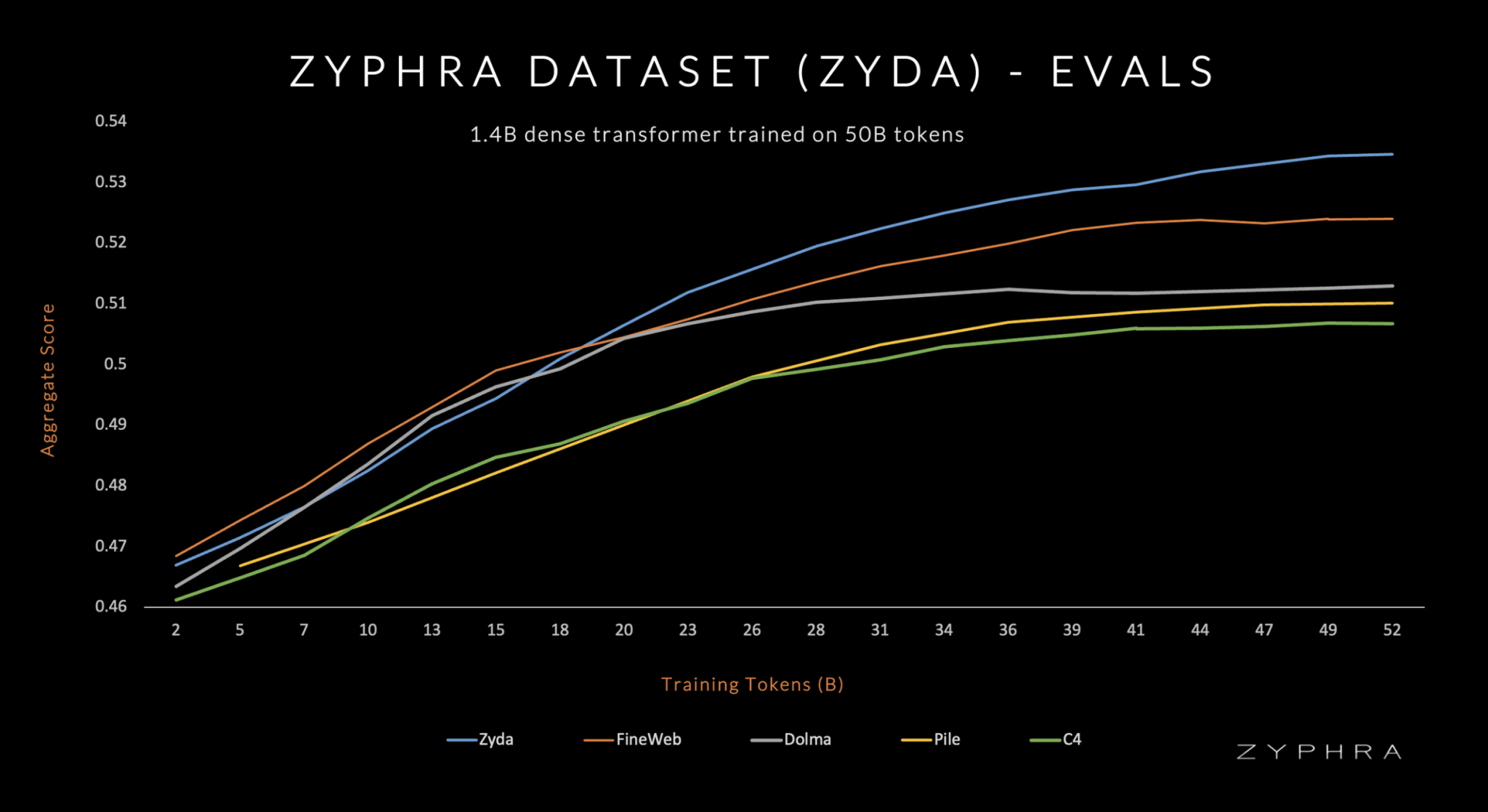
- Превосходная производительность: Zyda опережает все основные наборы данных для языкового моделирования, демонстрируя эффективность в сравнительных оценках.
- Дедупликация между наборами данных: Реализация кросс-дедупликации обеспечивает устранение дубликатов внутри и между отдельными наборами данных.
- Открытая и лицензируемая модель: Zyda выпущен под открытой и лицензируемой лицензией, делая его свободно доступным для сообщества.
Zyda был тщательно создан путем объединения семи уважаемых открытых наборов данных для языкового моделирования и последующей обработки, направленной на повышение качества и связности.
Эффективность Zyda проявляется в производительности Zamba, языковой модели, обученной на Zyda, что свидетельствует о высочайшем качестве Zyda и его потенциале для продвижения языкового моделирования.
В итоге Zyda представляет собой революционный шаг в языковом моделировании, устанавливая новый стандарт для возможностей открытых наборов данных и подчеркивая лидерство Zyphra в этой области.
Практические решения и ценность
Если вы хотите использовать искусственный интеллект для развития вашей компании, рассмотрите возможности внедрения AI-решений, начиная с малых проектов и анализируя их результаты, чтобы постепенно расширять автоматизацию. Используйте AI Sales Bot (https://itinai.ru/aisales), который поможет вам в области продаж, а также обращайтесь к нам для советов по внедрению ИИ на https://t.me/itinai.
Изучите, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru – будущее уже здесь!

















