
«`html
Генеративный искусственный интеллект (Generative AI) в революционировании областей изображений и видео
Генеративный искусственный интеллект (Generative AI) достиг значительного прогресса в революционизации областей, таких как генерация изображений и видео, благодаря инновационным алгоритмам, архитектурам и данным. Однако быстрое распространение генеративных моделей выявило критическую проблему: отсутствие надежных метрик оценки. Текущие автоматические оценки, такие как FID, CLIP и FVD, часто не удается уловить тонкие качества и удовлетворение пользователей, связанные с генеративными результатами. В то время как технологии генерации и манипуляции изображений развиваются быстро, обеспечивая применение в различных областях, таких как искусство, визуальное улучшение и медицинское изображение, оценка множества доступных моделей и их производительности остается сложной задачей. Традиционные метрики, такие как PSNR, SSIM, LPIPS и FID, предоставляют ценные, но специфические инсайты в определенные аспекты генерации визуального контента, часто неспособные полноценно оценить общую производительность модели, особенно в отношении субъективных качеств, таких как эстетика и удовлетворение пользователей.
Оценка производительности мультимодальных генеративных моделей
Для оценки производительности мультимодальных генеративных моделей в области генерации изображений были предложены различные методы. Методы, такие как CLIPScore, измеряют соответствие текста, в то время как IS, FID, PSNR, SSIM и LPIPS оценивают верность и восприятие изображения. Недавние исследования используют мультимодальные большие языковые модели (MLLM) в качестве судей, такие как T2I-CompBench с использованием miniGPT4, TIFA, адаптирующая визуальный ответ на вопрос, и VIEScore, отражающая потенциал MLLM для замены человеческих судей. Для оценки генерации видео метрики, такие как FVD, измеряют согласованность кадров и качество, в то время как CLIPSIM использует модели сходства изображения и текста. Однако эти автоматические метрики все еще отстают от предпочтений людей, с низкой корреляцией, вызывающей сомнения в их надежности.
Платформа оценки генеративного ИИ
Исследователи из Университета Ватерлоо представили GenAI-Arena, мощную платформу, разработанную для справедливой оценки генеративных моделей искусственного интеллекта. Вдохновленная успешными реализациями в других областях, GenAI-Arena предлагает динамичную и интерактивную платформу, где пользователи могут генерировать изображения, сравнивать их бок о бок и голосовать за предпочитаемые модели. Эта платформа упрощает процесс сравнения различных моделей и предоставляет систему ранжирования, отражающую предпочтения людей, предлагая более комплексную оценку возможностей модели. GenAI-Arena — первая платформа оценки с обширными возможностями оценки по нескольким параметрам, поддерживающая широкий спектр задач, включая генерацию изображений по тексту, редактирование изображений по тексту и генерацию видео по тексту, а также публичный процесс голосования для обеспечения прозрачности маркировки.
GenAI-Arena поддерживает задачи генерации изображений по тексту, редактирования изображений и генерации видео по тексту с функциями анонимного бок о бок голосования, площадкой для сражений, прямой вкладкой генерации и рейтингами. Платформа стандартизирует вывод моделей с фиксированными гиперпараметрами и предлагает справедливое сравнение. Она обеспечивает беспристрастное голосование через анонимность, где пользователи голосуют за свои предпочтения между анонимно сгенерированными результатами, вычисляя рейтинги Эло. Такая архитектура позволяет демократично и точно оценить производительность модели в различных задачах.
Результаты и исследование
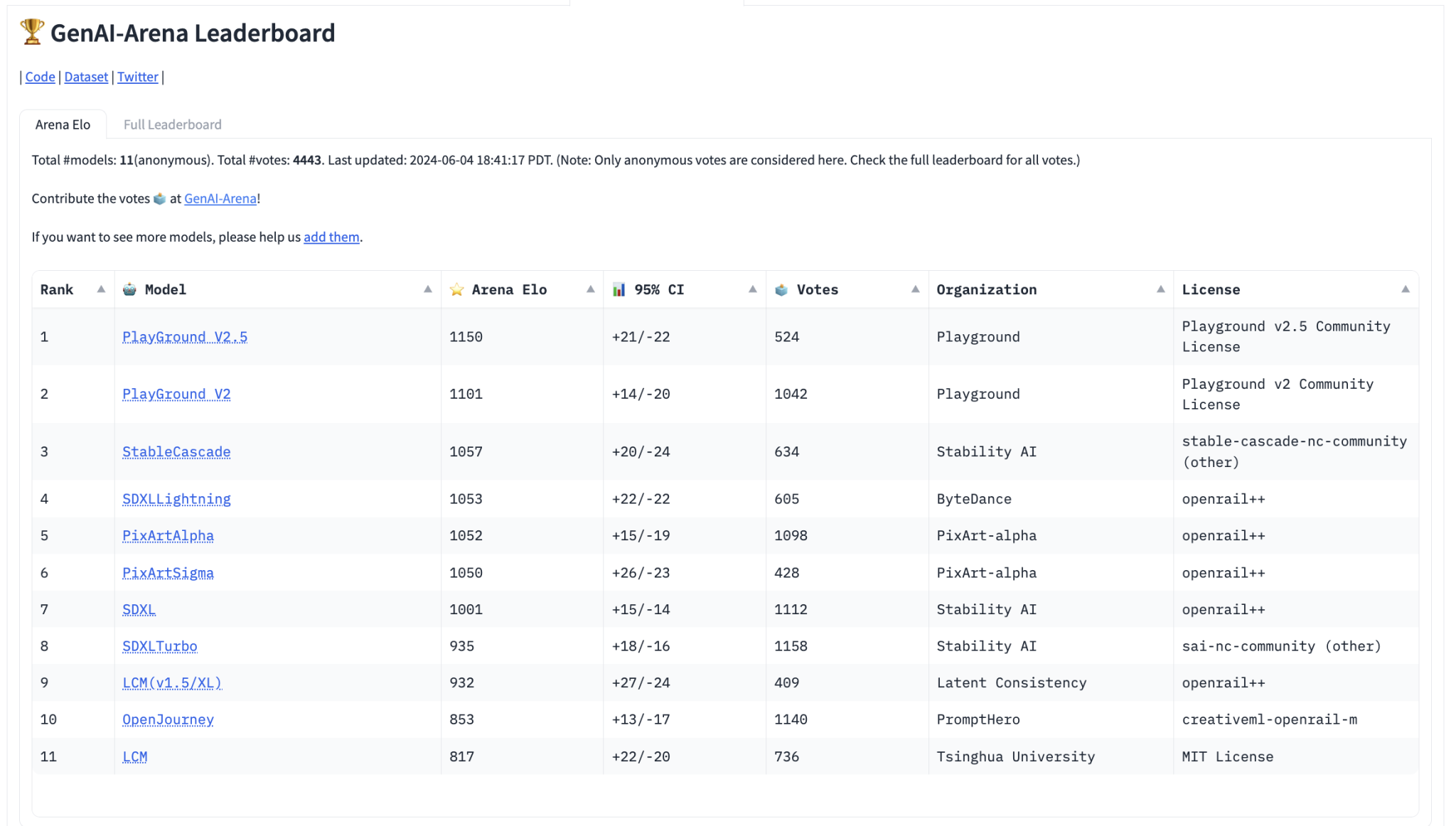
Исследователи представляют свои рейтинги на момент написания. Для генерации изображений собрано 4443 голоса, модели Playground V2.5 и Playground V2 от Playground.ai лидируют, следуя той же архитектуре SDXL, но обученные на частном наборе данных, значительно превосходя 7-е место SDXL, что подчеркивает важность тренировочных данных. StableCascade, использующий эффективную каскадную архитектуру, занимает следующее место, побеждая SDXL, несмотря на то, что его тренировочная стоимость составляет всего 10% от SD-2.1, подчеркивая важность архитектуры диффузии. Для редактирования изображений с 1083 голосами выше ранжируются MagicBrush, InFEdit, CosXLEdit и InstructPix2Pix, позволяющие локализованное редактирование, в то время как более старые методы, такие как Prompt-to-Prompt, производящие совершенно разные изображения, ранжируются ниже, несмотря на высококачественные результаты. Для текста к видео с 1568 голосами лидирует T2VTurbo с самым высоким рейтингом Эло как наиболее эффективная модель, следом идут StableVideoDiffusion, VideoCrafter2, AnimateDiff и другие, такие как LaVie, OpenSora, ModelScope с уменьшающейся производительностью.
В этом исследовании представлена платформа GenAI-Arena, открытая платформа, основанная на голосовании сообщества, для ранжирования генеративных моделей в области генерации изображений, редактирования изображений и генерации текста к видео на основе пользовательских предпочтений. Более 6000 голосов, собранных с февраля по июнь 2024 года, использовались для составления рейтингов Эло, выявляя передовые модели, а анализ выявил потенциальные предвзятости. Высококачественные данные о предпочтениях людей были выпущены в качестве GenAI-Bench, раскрывая плохую корреляцию существующих мультимодальных языковых моделей с человеческими суждениями о качестве созданного контента и других аспектах.
Проверьте Paper и HF Page. Вся честь за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему Telegram-каналу, Discord-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш newsletter.
Не забудьте присоединиться к нашему 44k+ ML SubReddit
«`




















