
«`html
Преобразование языка белков: как большие языковые модели революционизируют понимание последовательностей белков
Исследователи обнаружили параллели между последовательностями белков и естественным языком из-за их последовательной структуры, что привело к развитию моделей глубокого обучения для обеих областей. Большие языковые модели (LLM) проявили себя в задачах обработки естественного языка (NLP), и этот успех вдохновил попытки адаптировать их для понимания белков. Однако адаптация сталкивается с проблемой: существующим наборам данных не хватает прямых корреляций между последовательностями белков и текстовыми описаниями, что затрудняет эффективное обучение и оценку LLM для понимания белков. Несмотря на прогресс в многослойных моделях (MMLM), отсутствие комплексных наборов данных, интегрирующих последовательности белков с текстовым контентом, ограничивает полное использование этих моделей в белковой науке.
Набор данных ProteinLMDataset и бенчмарк ProteinLMBench
Исследователи из нескольких учреждений, включая Johns Hopkins и UNSW Sydney, создали набор данных ProteinLMDataset для улучшения понимания LLM последовательностей белков. Этот набор данных содержит 17,46 миллиарда токенов для предварительного самообучения и 893 тысячи инструкций для контролируемой настройки. Они также разработали ProteinLMBench, первый бенчмарк с 944 вручную проверенными вопросами с множественным выбором для оценки понимания белков в LLM. Набор данных и бенчмарк направлены на устранение разрыва в интеграции белково-текстовых данных, позволяя LLM понимать последовательности белков без дополнительных кодировщиков и генерировать точные знания о белках с использованием нового подхода Enzyme Chain of Thought (ECoT).
Проблемы существующих наборов данных и бенчмарков
Обзор литературы выявляет ключевые ограничения существующих наборов данных и бенчмарков для NLP и последовательностей белков. Существует необходимость в более комплексной, многофункциональной и мультидоменной оценке китайско-английских наборов данных, поскольку существующие бенчмарки часто ограничены географически и требуют большей интерпретируемости. В наборах данных по последовательностям белков основные ресурсы, такие как UniProtKB и RefSeq, сталкиваются с проблемами в полном представлении разнообразия белков и точной аннотации данных, с учетом предвзятостей и ошибок от сообщественных вкладов и автоматизированных систем. В то время как комплексные базы данных по дизайну белков, такие как KEGG и STRING, ограничены предвзятостями, ресурсоемкой кураторской работой и сложностями интеграции разнообразных источников данных.
Диверсификация ProteinLMDataset и ProteinLMBench
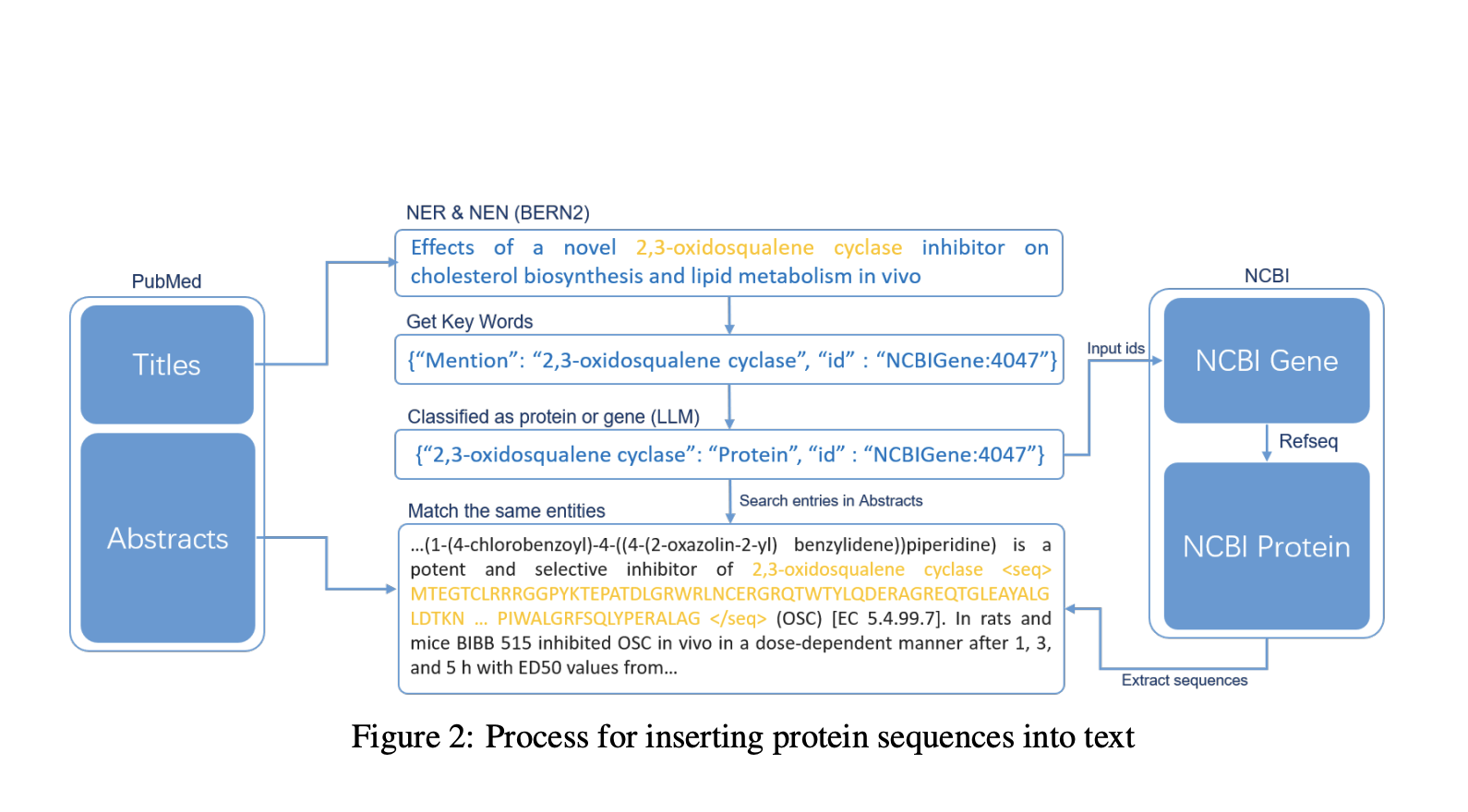
Набор данных ProteinLMDataset разделен на самообучающиеся и контролируемые компоненты. Самообучающийся набор данных включает китайско-английские научные тексты, пары последовательностей белков и английских текстов из PubMed и UniProtKB, а также обширные записи из базы данных PMC, предоставляя более 10 миллиардов токенов. Контролируемый компонент для настройки содержит 893 тысячи инструкций по семи сегментам, таким как функциональность ферментов и участие в заболеваниях, в основном извлеченных из UniProtKB. ProteinLMBench, бенчмарк для оценки, содержит 944 тщательно отобранных вопроса с множественным выбором о свойствах и последовательностях белков. Этот метод сбора набора данных обеспечивает комплексное представление, фильтрацию и токенизацию для эффективного обучения и оценки LLM в белковой науке.
Преимущества ProteinLMDataset и ProteinLMBench
Набор данных ProteinLMDataset и бенчмарк ProteinLMBench разработаны для комплексного понимания последовательностей белков. Набор данных разнообразен, с токенами от 21 до более 2 миллионов символов, собранных из множества источников, включая китайско-английские текстовые пары, аннотации PubMed и UniProtKB. Самообучающиеся данные в основном состоят из последовательностей белков и научных текстов, в то время как контролируемый компонент для настройки охватывает семь сегментов, такие как функциональность ферментов и участие в заболеваниях, с длиной токенов от 65 до 70 500. ProteinLMBench включает 944 сбалансированных вопроса с множественным выбором для оценки производительности модели. Тщательные проверки безопасности и фильтрация обеспечивают качество и целостность данных. Результаты экспериментов показывают, что комбинирование самообучения с настройкой улучшает точность модели, подчеркивая эффективность набора данных.
Заключение
Набор данных ProteinLMDataset и бенчмарк ProteinLMBench предоставляют надежную основу для обучения и оценки языковых моделей на последовательностях белков и двуязычных текстах. Включая разнообразные источники и китайско-английские текстовые пары, набор данных улучшает мультиязычное и кросс-языковое понимание характеристик белков. Эксперименты демонстрируют значительное улучшение точности модели при настройке, особенно при использовании как самообучающихся, так и контролируемых наборов данных. Эта работа устраняет разрыв в адаптации LLM для белковой науки, демонстрируя потенциал для трансформации биологических исследований и приложений. Модель InternLM2-7B, обученная на этом наборе данных, превосходит GPT-4 в задачах понимания белков.
Проверьте статью и набор данных. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
Статья опубликована на портале MarkTechPost.
«`




















