
«`html
Увеличение эффективности моделей языковых моделей с помощью новых методов
Языковые модели (LLM) с большим количеством параметров демонстрируют высокую производительность в задачах обработки естественного языка (NLP), таких как генерация кода и ответы на вопросы. Однако их плотная структура требует большого объема вычислительных ресурсов, что затрудняет их широкое распространение.
Увеличение эффективности через условные вычисления
Для повышения эффективности и снижения нагрузки на вычисления используется метод условных вычислений. Он позволяет активировать только часть нейронов модели в ответ на входные данные, что сокращает ненужные вычисления.
Для реализации условных вычислений используются два основных метода: стратегия Mixture-of-Experts (MoE) и активационные функции, такие как ReLU.
Новые методы для увеличения разреженности и эффективности
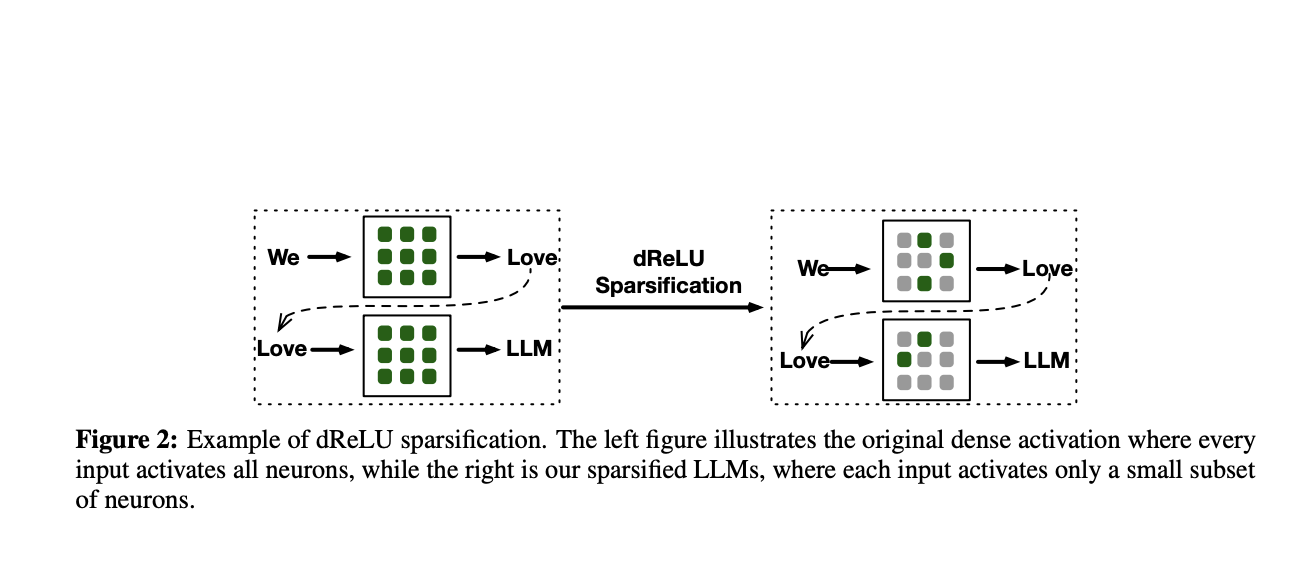
Исследователи из Китая предложили новую функцию активации dReLU, которая повышает разреженность активаций модели и улучшает ее производительность. Тесты на небольших LLM, предобученных с использованием dReLU, показали, что модели с этой функцией демонстрируют производительность на уровне моделей с другими активационными функциями, при этом достигается разреженность активаций до 90%.
Команда исследователей также провела анализ разреженности в MoE-моделях и обнаружила, что их сети экспертов демонстрируют разреженность активаций, сравнимую с плотными LLM. Это наблюдение позволяет предположить, что комбинация подходов MoE и разреженности, обусловленной ReLU, может привести к дополнительным преимуществам в эффективности.
Практические результаты и применение
Применение предложенных методов к моделям Mistral-7B и Mixtral-47B показало, что улучшенные модели не только не уступают по производительности оригинальным версиям, но часто превосходят их. Это позволяет достичь ускорения в задачах генерации на уровне 2,83 раза, что подтверждает эффективность предложенного подхода.
Команда исследователей также поделилась своими основными достижениями:
- Введена функция dReLU, повышающая разреженность активаций
- Анонсированы модели TurboSparse-Mistral7B и TurboSparse-Mixtral-47B, демонстрирующие превосходную производительность по сравнению с плотными версиями
- Проведена оценка, показавшая ускорение в 2-5 раз при практическом использовании улучшенных моделей
Подробнее ознакомиться с исследованием и моделями можно в данной статье. Вся заслуга за это исследование принадлежит команде исследователей проекта.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам интересна наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit.
«`



















