
Решение проблемы контроля уровня владения языком в текстах, созданных большими моделями языка (LLM)
Разработчики ИИ представили метод, объединяющий тонкую настройку и применение PPO для выравнивания уровней владения языком согласно стандартам Общеевропейской шкалы оценки владения иностранным языком (CEFR). Новый подход позволяет создавать контент высокого качества, контролируя уровни владения языком, при этом снижая затраты по сравнению с использованием закрытых моделей.
Практические решения для получения контента определенного уровня владения языком
Новый метод включает тонкую настройку открытых моделей, таких как LLama-2-7B и Mistral-7B, с использованием набора данных, созданного эффективными стратегиями создания GPT-4. Набор данных TinyTolkien состоит из коротких историй с разными уровнями CEFR. Дальнейшее обучение с помощью PPO выравнивает выходные данные модели с желаемыми уровнями владения языком.
Оценка результатов
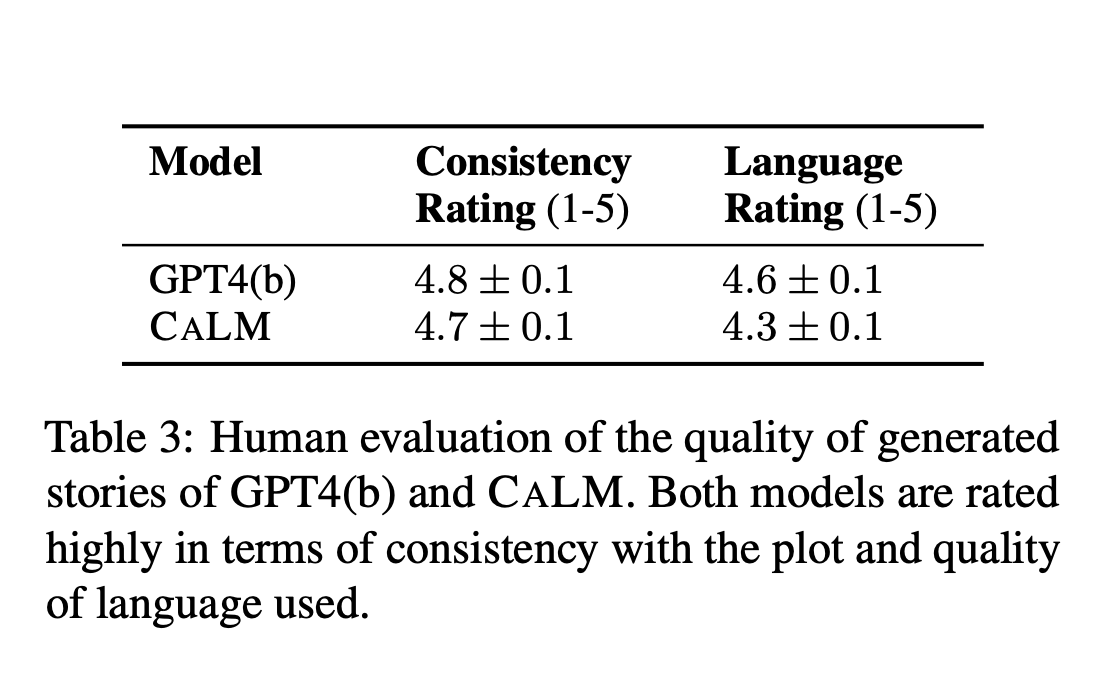
Предложенная модель CALM показывает контрольную ошибку, сопоставимую с GPT-4, при этом значительно снижая затраты. Метрики оценки включают контрольную ошибку, оценку качества и вычислительные затраты. Результаты были проверены как автоматическим скорингом, так и масштабным исследованием, демонстрирующим высокие оценки качества и выравнивания уровней владения языком.
Заключение
Предложенный метод значительно продвигает область, предоставляя эффективное, экономичное решение для генерации текста, контролирующего уровни владения языком. Эта работа имеет потенциал улучшить приложения в области образования и изучения языков, делая передовые инструменты ИИ более доступными для широкой аудитории.





















