
«`html
Новый прорыв в области языковых моделей: представляем SAMBA 3.8B
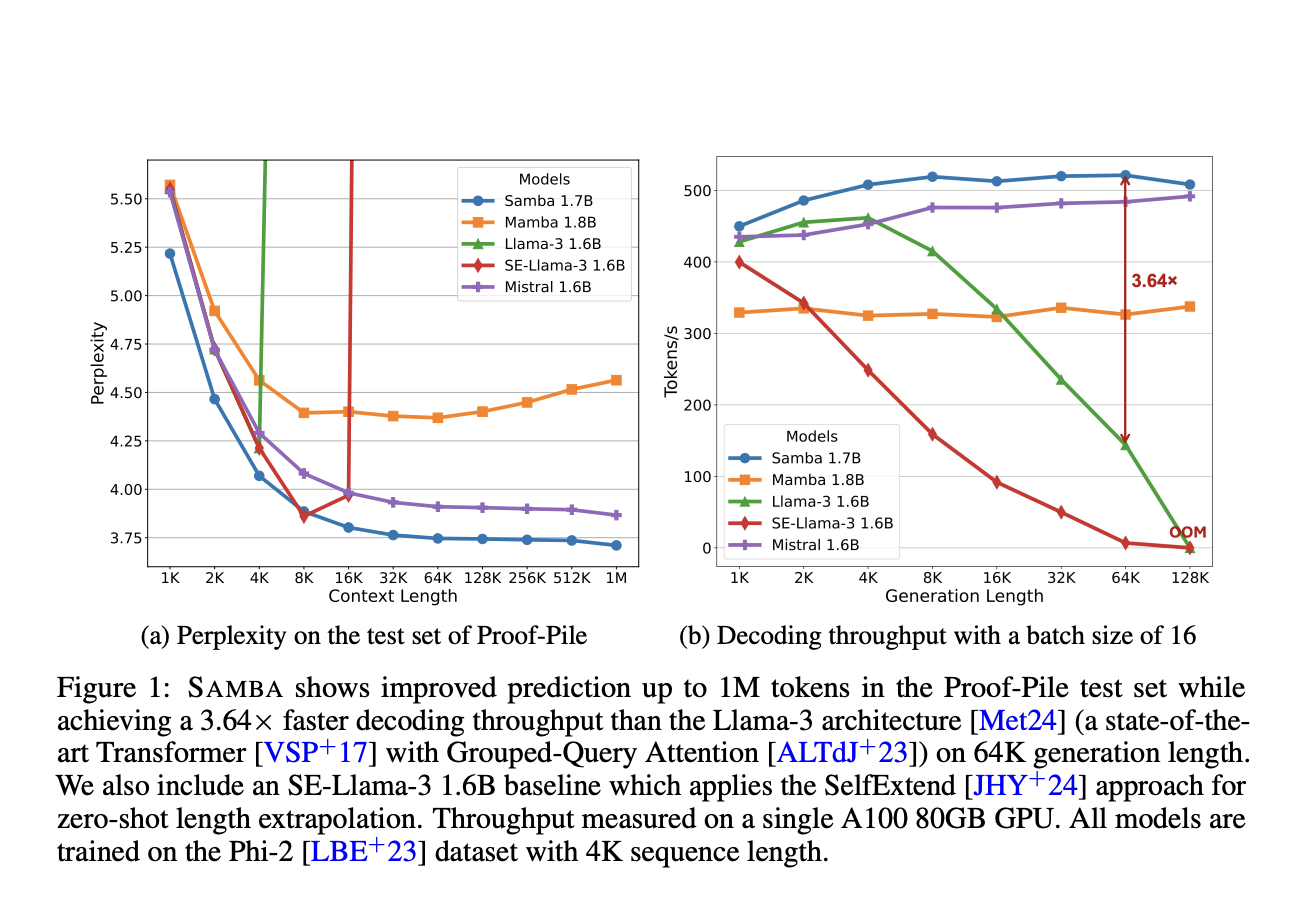
Большие языковые модели (LLM) сталкиваются с проблемами в захвате сложных долгосрочных зависимостей и достижении эффективной параллелизации для масштабного обучения. Модели на основе внимания доминируют в архитектуре LLM из-за их способности решать эти проблемы. Однако они сталкиваются с вычислительной сложностью и экстраполяцией к более длинным последовательностям. Модели пространства состояний (SSM) возникли как многообещающая альтернатива, предлагая линейную вычислительную сложность и потенциал для лучшей экстраполяции. Несмотря на эти преимущества, SSM сталкиваются с проблемами воспроизведения памяти из-за их марковской природы и менее конкурентоспособны в задачах связанных с информационным поиском по сравнению с моделями на основе внимания.
Преимущества SAMBA
Исследователи из Microsoft и Университета Иллинойса в Урбане-Шампейне представляют SAMBA, простую нейронную архитектуру, которая гармонизирует преимущества SSM и моделей на основе внимания, достигая экстраполяции последовательностей неограниченной длины с линейной сложностью времени. Архитектура SAMBA включает слои Mamba, SwiGLU и Sliding Window Attention (SWA). Слои Mamba захватывают зависимости от времени и обеспечивают эффективное декодирование, в то время как SWA моделирует сложные, не-марковские зависимости. Исследователи масштабировали SAMBA до различных размеров, с наибольшей моделью на 3,8 миллиарда параметров, предварительно обученной на 3,2 триллиона токенов. Эта модель продемонстрировала впечатляющую производительность на бенчмарках, превосходя другие открытые языковые модели до 8 миллиардов параметров.
Применение в реальном мире
Архитектура SAMBA представляет собой значительный прорыв в языковом моделировании, объединяя преимущества механизмов внимания и моделей пространства состояний. Ее гибридная архитектура демонстрирует превосходную производительность на различных бенчмарках, превосходя чисто на основе внимания и SSM модели. Способность SAMBA эффективно обрабатывать контекст произвольной длины, в сочетании с его удивительными возможностями экстраполяции памяти, делает его особенно подходящим для прикладных задач, требующих понимания обширного контекста. Оптимальный баланс между вниманием и рекуррентными структурами приводит к мощной, эффективной модели, расширяющей границы языкового моделирования и предлагающей многообещающие решения для сложных задач обработки естественного языка.
Для получения более подробной информации ознакомьтесь с нашей статьей и посетите наш репозиторий на GitHub.
Следите за обновлениями в нашем Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Попробуйте нашего AI Sales Bot здесь.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab здесь.
«`


















