
«`html
Графовые нейронные сети (GNN), также известные как нейронные алгоритмические рассудители (NAR), продемонстрировали свою эффективность в решении алгоритмических задач различного размера входных данных как внутри, так и вне распределения. Однако NAR все еще являются относительно узкими формами искусственного интеллекта, так как требуют жесткой структурированной форматированной входной информации и не могут непосредственно применяться к проблемам, поставленным в шумной форме, например, естественным языком, даже когда основная проблема является алгоритмической. Напротив, модели языка на основе трансформера отлично моделируют шумные текстовые данные, но испытывают трудности с алгоритмическими задачами, особенно теми, которые требуют обобщения вне распределения. Основной вызов заключается в разработке методов, способных обрабатывать алгоритмическое рассуждение на естественном языке, сохраняя при этом сильные обобщающие способности.
TransNAR: гибридная архитектура для решения алгоритмических задач
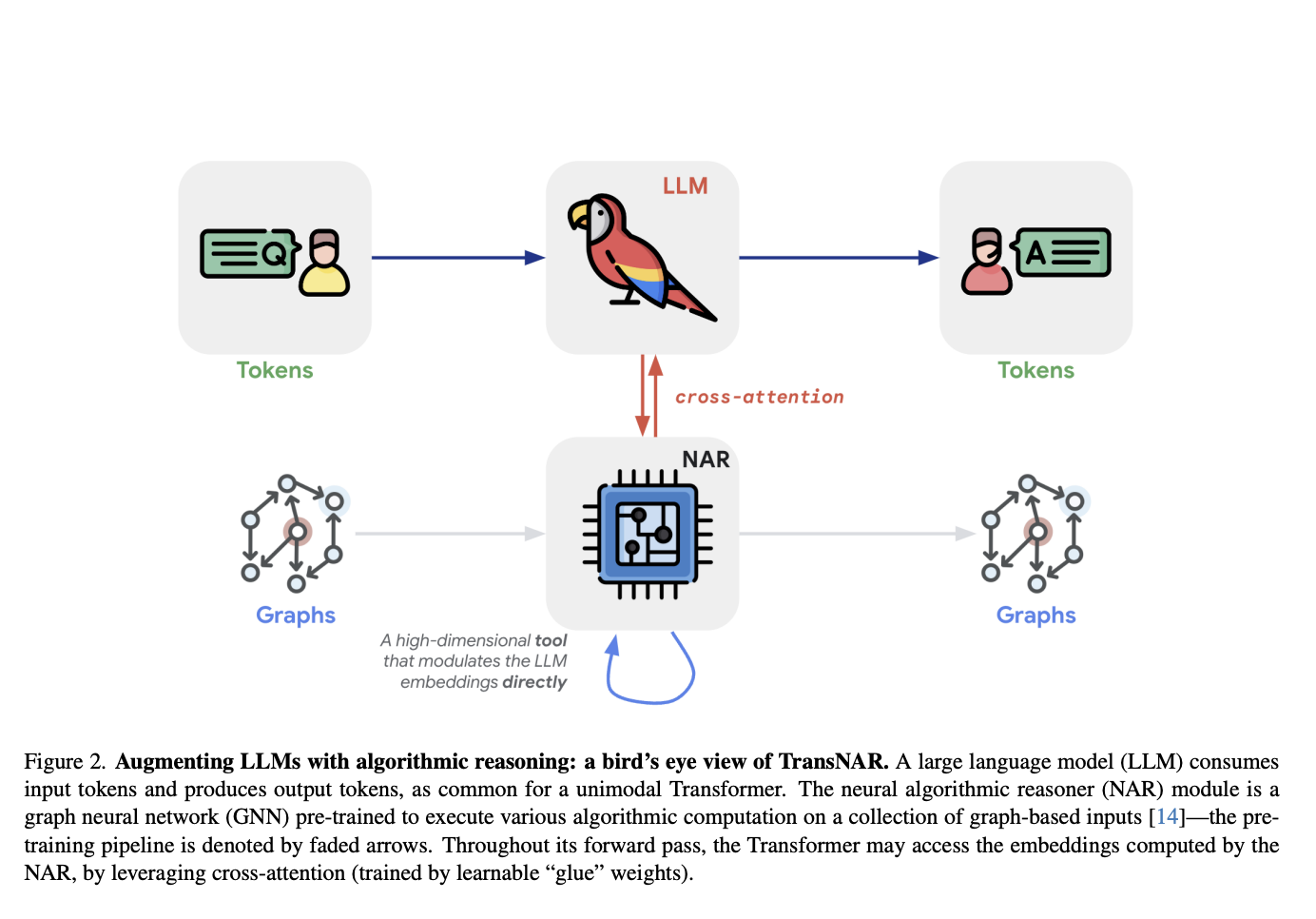
Исследователи DeepMind предложили TransNAR, который представляет собой гибридную архитектуру, объединяющую возможности понимания языка трансформеров с надежными алгоритмическими способностями предварительно обученных NAR на основе GNN. Трансформер использует NAR в качестве высокоразмерного инструмента для модуляции своих токенных вложений. Конкретно, модуль NAR представляет собой предварительно обученную GNN для выполнения различных алгоритмических вычислений на входных данных, представленных в виде графа. Во время своего прохода вперед, трансформер может получить доступ к вложениям, вычисленным NAR, используя кросс-внимание с обучаемыми весами «клея». Эта синергия между трансформерами и NAR направлена на улучшение способностей рассуждения языковых моделей, особенно для алгоритмических задач вне распределения.
Преимущества TransNAR
Метод TransNAR основан на нескольких областях исследований: нейронное алгоритмическое рассуждение, обобщение длины в языковых моделях, использование инструментов и мультимодальность. Он вдохновлен работами, демонстрирующими, что NAR могут выполнять несколько алгоритмов одновременно и обобщаться далеко за пределы своего обучающего распределения. TransNAR использует предварительно обученный многозадачный модуль NAR и масштабирует его, интегрируя его с языковой моделью. Решая ограниченные способности обобщения длины языковых моделей, TransNAR объединяет понимание языка трансформеров с надежным алгоритмическим рассуждением NAR. Этот гибридный подход, использующий кросс-внимание между двумя модулями, направлен на улучшение способностей рассуждения, особенно для алгоритмических задач вне распределения, поставленных на естественном языке.
Архитектура TransNAR и ее результаты
Архитектура TransNAR принимает двойной вход: текстовую спецификацию алгоритмической задачи и соответствующее графовое представление из бенчмарка CLRS-30. Проход модели чередует слои трансформера, обрабатывающие текстовый вход, с слоями NAR, работающими с графовым входом. Критически важно, что слои трансформера используют кросс-внимание, чтобы условить свои токенные вложения на вложения узлов, вычисленные NAR. Эта синергия позволяет языковой модели дополнить свое понимание надежными алгоритмическими способностями предварительно обученного модуля NAR. Модель обучается end-to-end с целью предсказания следующего токена в текстовом выводе.
Результаты демонстрируют значительные улучшения, достигнутые моделью TransNAR по сравнению с базовым трансформером. TransNAR превосходит базовую модель в целом и по большинству отдельных алгоритмов как внутри, так и вне распределения. Важно отметить, что TransNAR не только улучшает существующие способности обобщения вне распределения, но также обеспечивает такие способности, когда они полностью отсутствуют у базовой модели. Анализ оценки формы показывает, что привязка выходов трансформера к вложениям NAR увеличивает долю входов, для которых модель производит правильные выходы, уменьшая конкретный тип сбоя. Однако TransNAR все еще испытывает трудности с алгоритмами, включающими поиск конкретного индекса во входном списке, указывая на единый тип сбоя, связанный с обобщением к надежным границам индексов, невидимым во время обучения.
Заключение
Эта работа представляет TransNAR, гибридную архитектуру, объединяющую языковую модель трансформера с предварительно обученной алгоритмической нейронной сетью на основе графов NAR. Путем привязки возможностей понимания языка трансформера к надежным алгоритмическим рассуждениям NAR, TransNAR может эффективно решать алгоритмические задачи, поставленные на естественном языке. Оценки на бенчмарке CLRS-Text продемонстрировали превосходство TransNAR над моделями только на основе трансформера как внутри, так и, что критично, вне распределения с более крупными входными данными.
Посмотрите статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
Этот пост был опубликован на MarkTechPost.
«`



















