
«`html
Исследование в области Offline Reinforcement Learning RL: Практические советы для специалистов в области искусственного интеллекта и разработчиков алгоритмов будущего
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте исследование в области Offline Reinforcement Learning RL: Практические советы для специалистов в области искусственного интеллекта и разработчиков алгоритмов будущего.
Практические решения и ценность
Применение методов, основанных на данных, которые преобразуют офлайн наборы данных предыдущего опыта в политики, является ключевым способом решения проблем управления в различных областях. Существуют два основных подхода для обучения политик на основе офлайн данных: имитационное обучение и офлайн обучение с подкреплением (RL). Имитационное обучение требует высококачественных демонстрационных данных, в то время как офлайн обучение с подкреплением RL может обучать эффективные политики даже на основе субоптимальных данных, что теоретически делает офлайн RL более интересным. Однако недавние исследования показывают, что просто собирая больше экспертных данных и тонко настраивая имитационное обучение, оно часто превосходит офлайн обучение с подкреплением RL, даже когда у офлайн RL есть много данных. Это вызывает вопросы о том, что является основной причиной, влияющей на производительность офлайн RL.
Офлайн RL фокусируется на обучении политики с использованием только ранее собранных данных, и основной вызов в офлайн RL заключается в работе с различием в распределениях состояний-действий между набором данных и обученной политикой. Это различие может привести к значительному переоцениванию значений, что может быть опасно, поэтому для предотвращения этого ранее проведенные исследования в области офлайн RL предложили различные методы для оценки более точных функций ценности на основе офлайн данных. Эти методы обучают политики для максимизации функции ценности после ее оценки с использованием таких техник, как поведенческий регуляризованный градиент политики, такие как DDPG+BC, взвешенное клонирование поведения, такие как AWR, или выбор действий на основе выборки, такие как SfBC. Однако лишь немногие исследования направлены на анализ и понимание практических вызовов в офлайн RL.
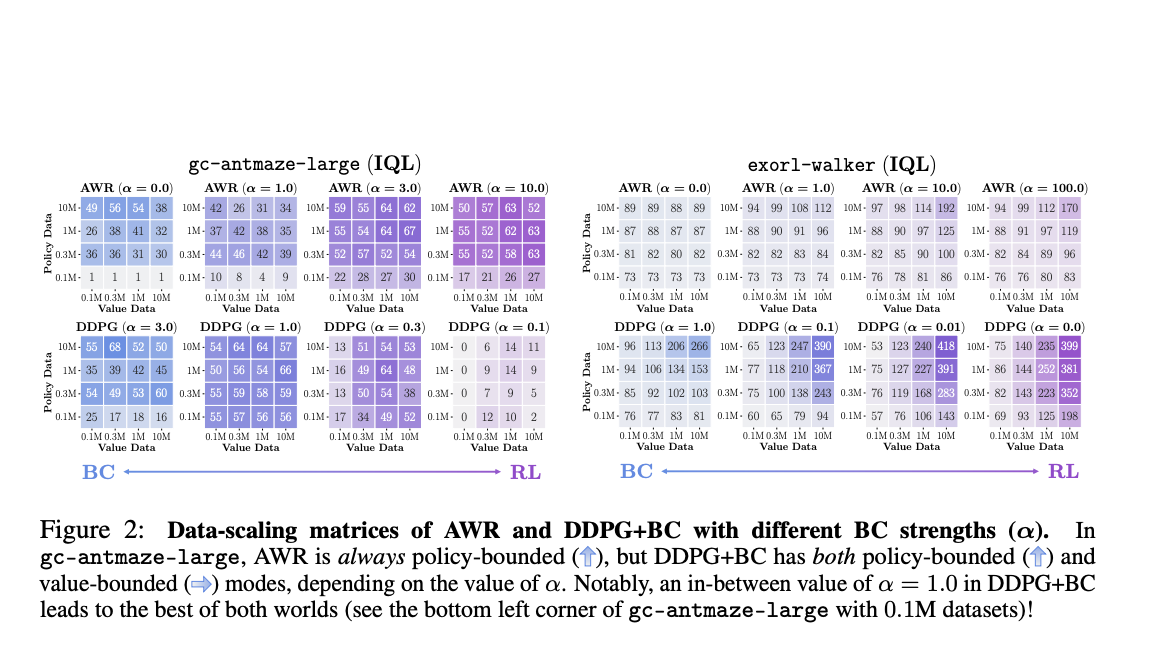
Исследователи из Университета Калифорнии в Беркли и Google DeepMind сделали два удивительных наблюдения в офлайн RL, предлагая практические советы для специалистов в области искусственного интеллекта и разработчиков алгоритмов будущего. Первое наблюдение заключается в том, что выбор алгоритма извлечения политики оказывает большее влияние на производительность по сравнению с алгоритмами обучения ценности. Однако алгоритм извлечения политики часто упускается при разработке алгоритмов офлайн RL, и среди различных алгоритмов извлечения политики методы поведенчески регуляризованного градиента политики, такие как DDPG+BC, последовательно демонстрируют лучшую производительность и масштабируются более эффективно с данными, чем широко используемые методы, такие как взвешенная регрессия ценности, например AWR.
Во втором наблюдении исследователи отметили, что офлайн обучение с подкреплением RL часто сталкивается с проблемами, потому что политика плохо работает на состояниях тестирования вместо состояний обучения. Реальная проблема заключается в точности политики на новых состояниях, с которыми агент сталкивается во время тестирования. Это смещает фокус с предыдущих проблем, таких как пессимизм и поведенческая регуляризация, на новую перспективу обобщения в офлайн RL. Для решения этой проблемы исследователи предложили два практических решения: (a) использование наборов данных с высоким покрытием и (b) использование техник извлечения политики на этапе тестирования.
Исследователи разработали новые техники для улучшения политик «на лету», которые улучшают информацию из функции ценности в политику во время процесса оценки, что приводит к лучшей производительности. Среди алгоритмов извлечения политики DDPG+BC достигает лучшей производительности и хорошо масштабируется в различных сценариях, за которым следует SfBC. Однако производительность AWR плоха по сравнению с двумя алгоритмами извлечения в нескольких случаях. Кроме того, матрицы масштабирования данных AWR всегда имеют вертикальные или диагональные цветовые градиенты, которые частично используют функцию ценности. Просто выбор алгоритма извлечения политики, такого как взвешенное клонирование поведения, может повлиять на использование изученных функций ценности, ограничивая производительность офлайн RL.
В заключение, исследователи обнаружили, что основной вызов в офлайн RL заключается не только в улучшении качества функции ценности, как ранее считалось. Вместо этого текущие методы офлайн RL часто сталкиваются с тем, насколько точно политика извлекается из функции ценности и насколько хорошо эта политика работает на новых, невидимых состояниях во время тестирования. Для эффективного офлайн RL функция ценности обучается на разнообразных данных, и политика может полностью использовать функцию ценности. Для будущих исследований данная статья ставит два вопроса в офлайн обучении с подкреплением RL: (a) Какой лучший способ извлечения политики из изученной функции ценности? (b) Как можно обучить политику таким образом, чтобы она хорошо обобщалась на состояния во время тестирования?
Проверьте Статью и Проект. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Телеграм-каналу и Группе LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
Пост Исследование в области Offline Reinforcement Learning RL: Практические советы для специалистов в области искусственного интеллекта и разработчиков алгоритмов будущего впервые появился на MarkTechPost.
«`



















