
«`html
BigCodeBench: Новый стандарт для оценки больших языковых моделей на практических задачах программирования
BigCode, ведущая компания в разработке больших языковых моделей (LLM), объявила о выпуске BigCodeBench, нового бенчмарка, предназначенного для тщательной оценки программных возможностей LLM на практических и сложных задачах.
Преодоление ограничений существующих бенчмарков
Существующие бенчмарки, такие как HumanEval, имели решающее значение при оценке LLM по задачам генерации кода, но они критикуются за свою простоту и недостаток применимости к реальным ситуациям. BigCodeBench разработан для заполнения этой ниши.
Компоненты и возможности
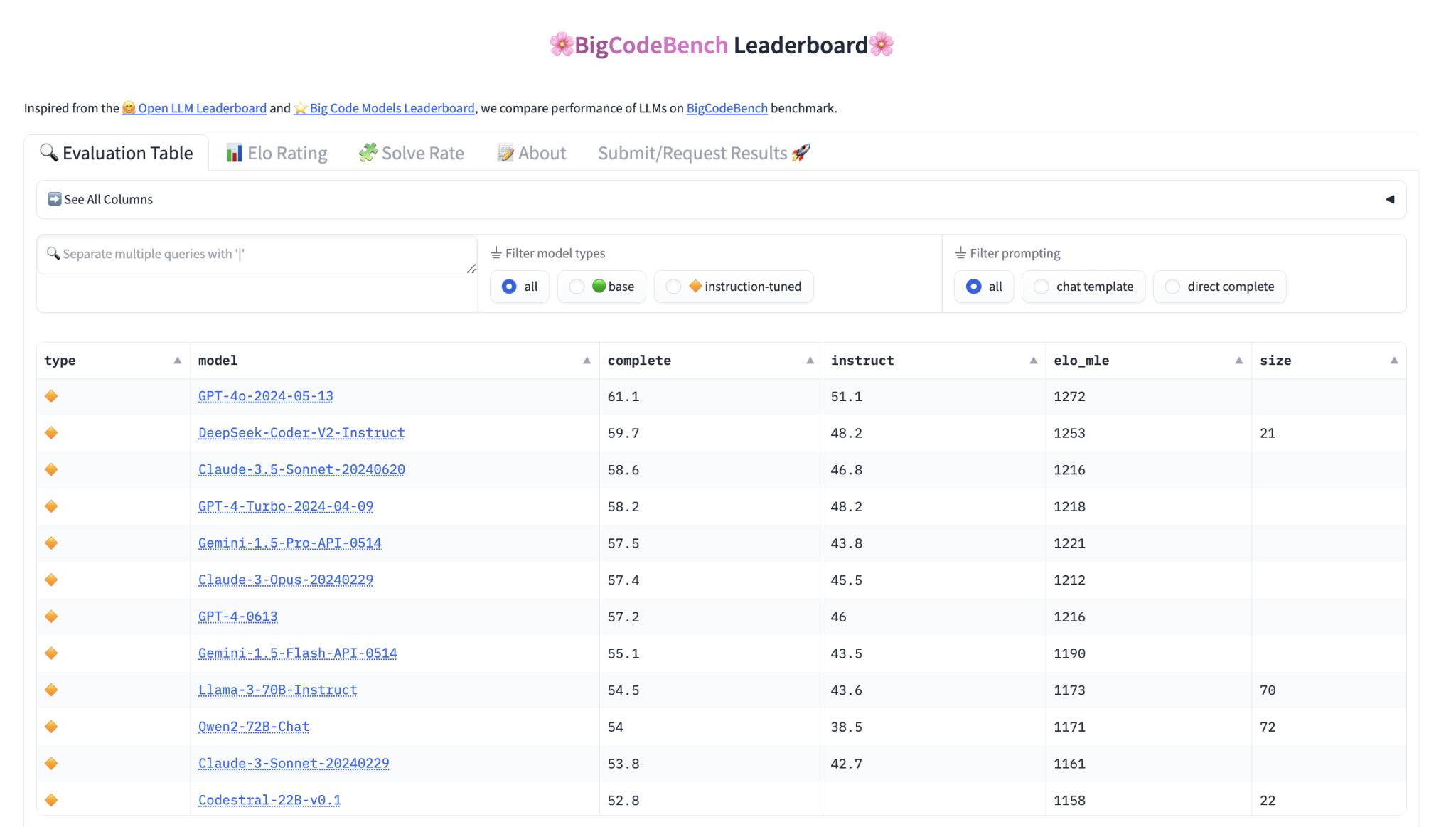
BigCodeBench разделен на две основные части: BigCodeBench-Complete и BigCodeBench-Instruct. BigCodeBench-Complete фокусируется на завершении кода, где LLM должны завершить реализацию функции на основе подробных инструкций docstring. BigCodeBench-Instruct, напротив, предназначен для оценки LLM, настроенных на инструкции, которые следуют естественно-языковым инструкциям.
Фреймворк оценки и таблица лидеров
Для упрощения процесса оценки BigCode предоставила удобный фреймворк, доступный через PyPI, с подробными инструкциями по настройке и предварительно собранными образами Docker для генерации и выполнения кода. Производительность моделей на BigCodeBench измеряется с использованием калиброванной метрики Pass@1, рейтинговая система Elo используется для ранжирования моделей.
Вовлечение сообщества и будущие разработки
BigCode призывает сообщество искусственного интеллекта взаимодействовать с BigCodeBench, предоставляя обратную связь и внося свой вклад в его развитие. Все артефакты, связанные с BigCodeBench, включая задачи, тестовые случаи и фреймворк оценки, являются открытыми и доступны на платформах, таких как GitHub и Hugging Face.
Заключение
Выпуск BigCodeBench является значительным событием в оценке LLM для программных задач, позволяя продвигать границы того, что могут достичь эти модели, и тем самым стимулируя развитие области искусственного интеллекта в разработке программного обеспечения.
Оцените нашу работу, ознакомьтесь с нашими новостями и применяйте ИИ-решения от AI Lab itinai.ru, потому что будущее уже здесь!
«`





















