
«`html
Долгие контекстные языковые модели (LCLMs)
Долгие контекстные языковые модели (LCLMs) представляют собой многообещающую технологию с потенциалом революционизировать искусственный интеллект. Они направлены на решение сложных задач и приложений, устраняя необходимость в сложных конвейерах, которые ранее были необходимы из-за ограничений на длину контекста. Однако разработка и оценка LCLMs сталкиваются с существенными проблемами. Текущие методы оценки полагаются на синтетические задачи или наборы данных фиксированной длины, которые не способны должным образом оценить реальные возможности этих моделей в реальных сценариях. Отсутствие строгих бенчмарков для действительно долгих контекстных задач затрудняет возможность проведения стресс-тестирования LCLMs на приложениях, меняющих парадигму. Преодоление этих ограничений критически важно для реализации полного потенциала LCLMs и их влияния на развитие искусственного интеллекта.
LOFT: Комплексный бенчмарк для оценки долгих контекстных языковых моделей
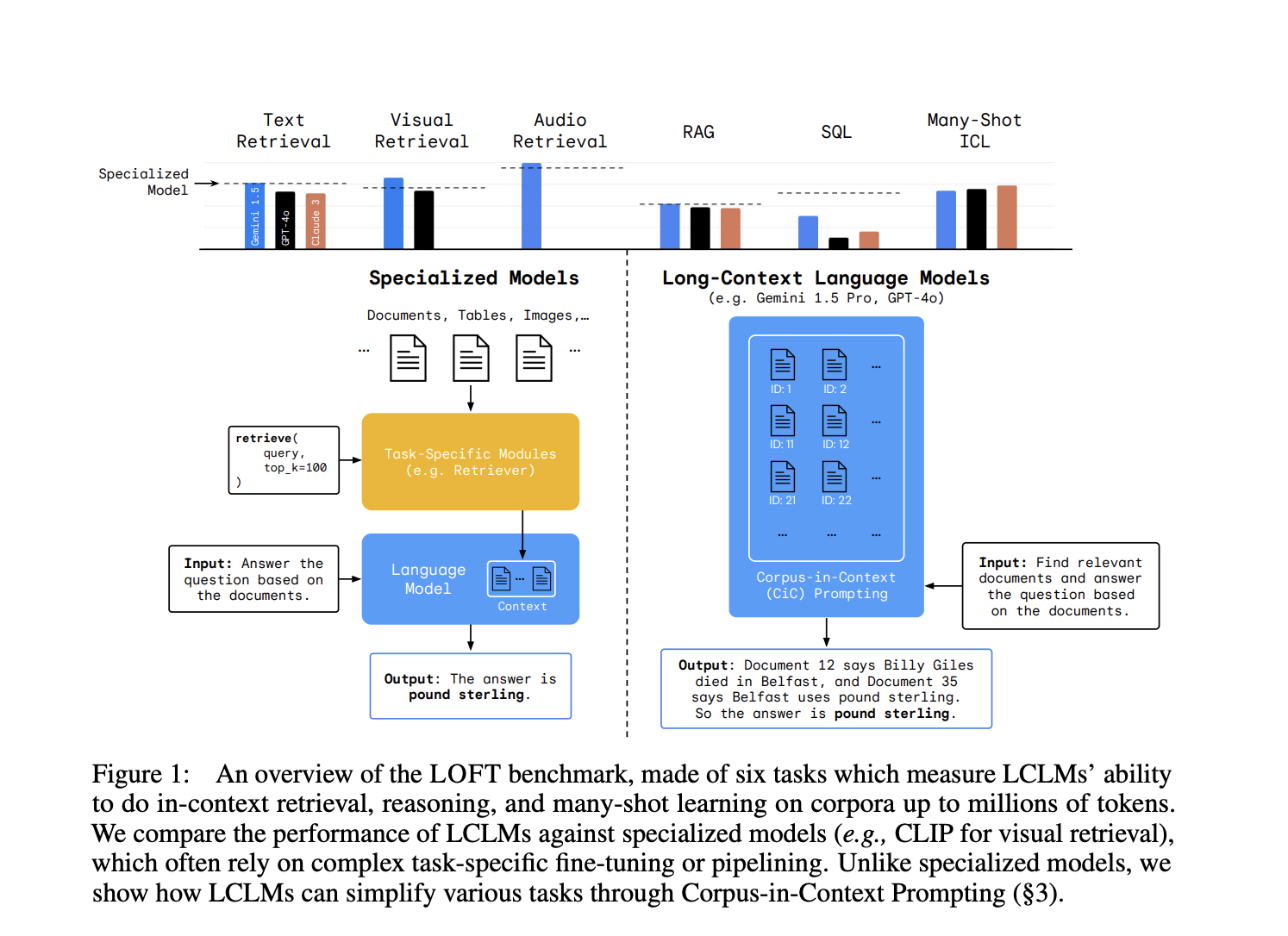
Исследователи DeepMind представляют Long-Context Frontiers (LOFT) для преодоления ограничений существующих методов оценки LCLMs. LOFT включает в себя шесть задач на 35 наборах данных, охватывающих текстовые, визуальные и аудио модальности. Этот комплексный бенчмарк разработан для выведения LCLMs на пределы и оценки их реального влияния. В отличие от предыдущих оценок, LOFT позволяет автоматически создавать контексты увеличивающейся длины, в настоящее время расширяющиеся до одного миллиона токенов с потенциалом для дальнейшего расширения. Бенчмарк фокусируется на четырех ключевых областях, где LCLMs имеют потенциал для изменения парадигмы: поиск по нескольким модальностям, генерация с использованием поиска (RAG), запросы к базам данных без SQL и обучение в контексте с множеством примеров. Направляясь на эти области, LOFT стремится предоставить строгую и масштабируемую систему оценки, способную держать шаг с развивающимися возможностями LCLMs.
Оценка LCLMs на основе LOFT
Бенчмарк LOFT оценивает Gemini 1.5 Pro, GPT-4 и Claude 3 Opus на различных задачах и длинах контекста. Gemini 1.5 Pro успешно справляется с поиском текста, визуальным поиском и аудио поиском, часто соответствуя или превосходя специализированные модели. Он отлично справляется с многопрыжковыми задачами RAG, но испытывает трудности с множественными целевыми наборами данных на больших масштабах. Задачи анализа, аналогичные SQL, показывают потенциал, но требуют улучшения. Результаты многопримерного обучения в контексте различаются, причем Gemini 1.5 Pro и Claude 3 Opus успешно проявляют себя в различных областях. Бенчмарк подчеркивает растущие возможности LCLMs в различных задачах и модальностях, а также выявляет области для улучшения, особенно в масштабировании до больших контекстов и сложном рассуждении.
Применение ИИ в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте LOFT: A Comprehensive AI Benchmark for Evaluating Long-Context Language Models. Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ. Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`


















