
«`html
Преимущества использования DigiRL: Новый автономный метод обучения агентов управления устройствами
Прогресс в моделях видео-языка (VLM) продемонстрировал впечатляющие способности к здравому смыслу, рассуждению и обобщению. Это означает, что разработка полностью автономного цифрового помощника на основе ИИ, способного выполнять повседневные задачи на компьютере естественным языком, становится возможной. Однако лучшие способности рассуждения и здравого смысла не автоматически приводят к интеллектуальному поведению помощника. ИИ-помощники используются для выполнения задач, рационального поведения и исправления ошибок, а не только для предоставления правдоподобных ответов на основе предварительных данных обучения. Поэтому требуется метод преобразования предварительных способностей в практических агентов ИИ.
Практические решения и ценность
Эта статья обсуждает три существующих метода. Первый метод — обучение мультимодальных цифровых агентов, которые сталкиваются с вызовами, такими как управление устройствами, выполняемое непосредственно на уровне пикселей в пространстве координатных действий, и стохастический и непредсказуемый характер экосистем устройств и интернета. Второй метод — среды для агентов управления устройствами. Эти среды предназначены для оценки и предлагают ограниченный набор задач в полностью детерминированных и стационарных условиях. Последний метод — обучение с подкреплением (RL) для LLM/VLM, где исследования с RL для основных моделей фокусируются на одношаговых задачах, таких как оптимизация предпочтений, но оптимизация одношагового взаимодействия на основе экспертных демонстраций может привести к субоптимальным стратегиям для многошаговых проблем.
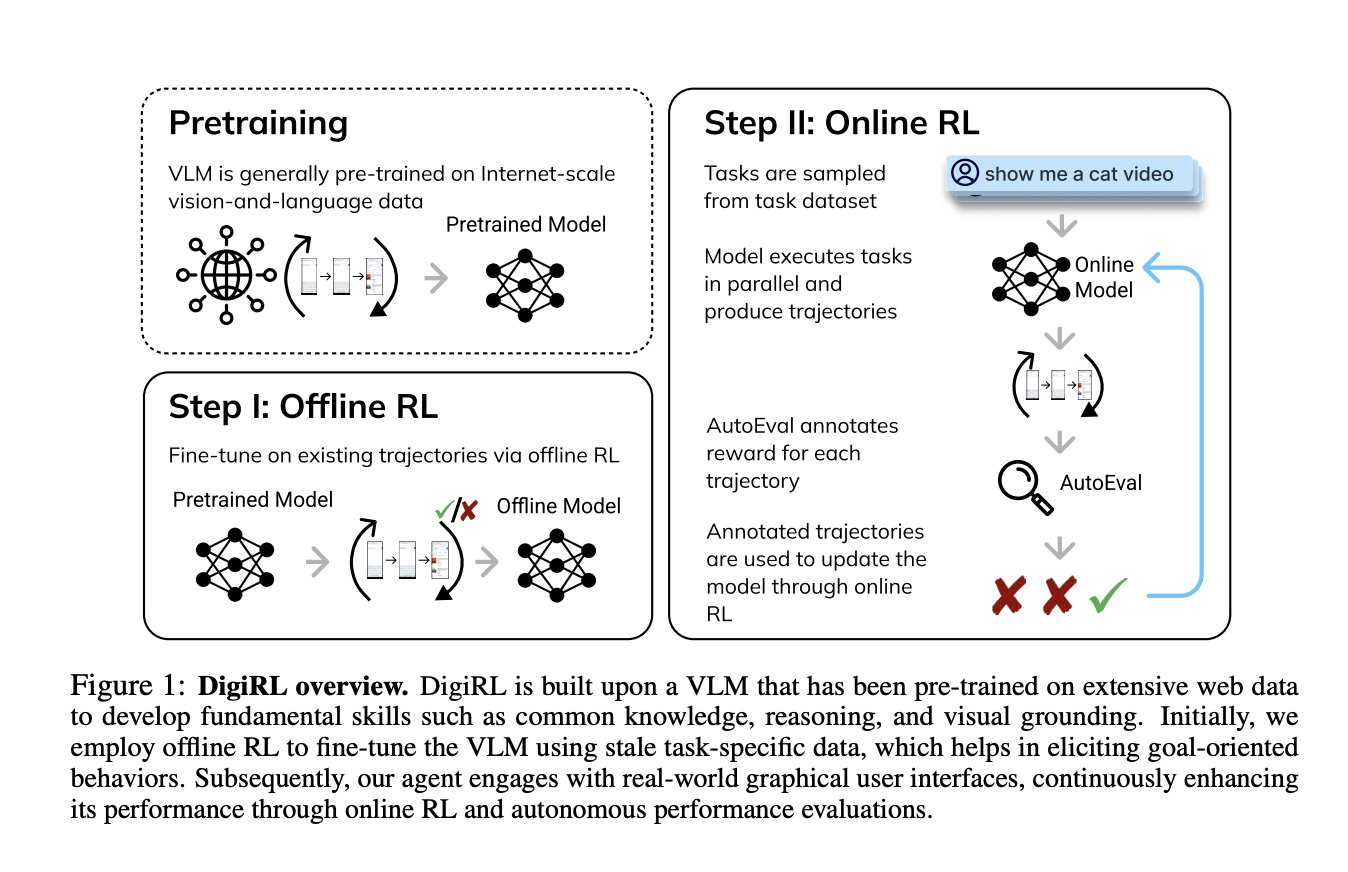
Исследователи из UC Berkeley, UIUC и Google DeepMind представили DigiRL (RL для цифровых агентов) — новый автономный метод RL для обучения агентов управления устройствами. Результирующий агент достигает передовой производительности на нескольких задачах управления устройствами Android. Процесс обучения включает две фазы: сначала начальная фаза оффлайн RL для инициализации агента с использованием существующих данных, затем фаза оффлайн-онлайн RL, используемая для настройки модели, полученной из оффлайн RL, на онлайн данных. Для обучения онлайн RL была разработана масштабируемая и параллельная среда обучения для Android, которая включает надежный универсальный оценщик (средняя ошибка 2,8% по сравнению с человеческим суждением) на основе VLM.
Исследователи провели эксперименты для оценки производительности DigiRL на сложных задачах управления устройствами Android. Важно понять, может ли DigiRL производить агентов, которые могут эффективно учиться через автономное взаимодействие, сохраняя возможность использовать оффлайн данные для обучения. Поэтому был проведен сравнительный анализ DigiRL по сравнению с:
- Агентами передовых моделей, построенными вокруг собственных VLM с использованием нескольких техник подачи и извлечения стиля.
- Запуск имитационного обучения на статических человеческих демонстрациях с тем же распределением инструкций.
- Подход к фильтрованному клонированию поведения.
Агент, обученный с использованием DigiRL, был протестирован на различных задачах из набора данных Android in the Wild (AitW) с реальными эмуляторами устройств Android. Агент достиг улучшения на 28,7% по сравнению с существующими передовыми агентами (увеличение успешности с 38,5% до 67,2%) 18B CogAgent. Он также превзошел предыдущий лучший метод автономного обучения на основе фильтрованного клонирования поведения более чем на 9%. Более того, несмотря на всего 1,3 миллиарда параметров, агент показал более высокую производительность, чем передовые модели, такие как GPT-4V и Gemini 1.5 Pro (успешность 17,7%). Это делает его первым агентом, достигшим передовой производительности в управлении устройствами с использованием автономного метода оффлайн-онлайн RL.
В заключение, исследователи предложили DigiRL — новый автономный метод RL для обучения агентов управления устройствами, который устанавливает новую передовую производительность на нескольких задачах управления устройствами Android из AitW. Была разработана масштабируемая и параллельная среда Android для достижения этой цели с надежным универсальным оценщиком на основе VLM для быстрого сбора онлайн данных. Агент, обученный на DigiRL, достиг улучшения на 28,7% по сравнению с существующими передовыми агентами 18B CogAgent. Однако обучение было ограничено задачами из набора данных AitW, а не всеми возможными задачами устройств. Поэтому будущая работа включает в себя алгоритмические исследования и расширение задачного пространства, сделав DigiRL базовым алгоритмом.
Применение в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте DigiRL: A Novel Autonomous Reinforcement Learning RL Method to Train Device-Control Agents.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















