
«`html
Применение метода PATH для обучения нейронных моделей информационного поиска малого масштаба (менее 100 млн параметров) с использованием всего 10 золотых меток релевантности
Креативное применение и управление предварительно обученными языковыми моделями привели к значительным улучшениям качества информационного поиска (IR). Существующие модели IR обычно обучаются на больших наборах данных, включающих сотни тысяч или даже миллионы запросов и оценок релевантности, особенно тех, которые могут обобщаться на новые, необычные темы.
Полезность и необходимость таких масштабных данных для оптимизации языковых моделей для задач информационного поиска подвергаются сомнению, возникают научные и инженерные проблемы. В частности, неясно с научной точки зрения, необходимо ли такое огромное количество данных, и с инженерной точки зрения неочевидно, как обучать модели IR для языков с небольшим или отсутствующим размеченным IR-данным или для узкоспециализированных областей.
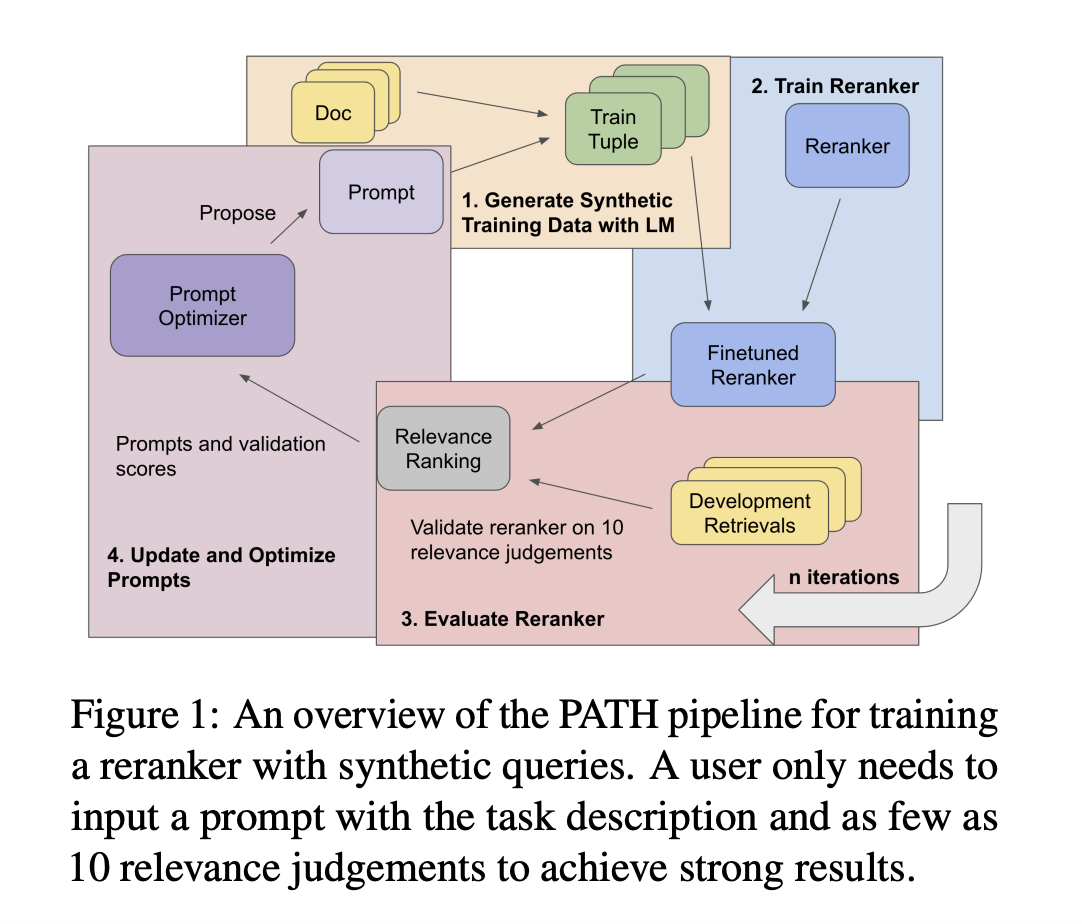
В недавних исследованиях команда ученых из Университета Ватерлоо, Стэнфордского университета и IBM Research AI представила метод обучения нейронных моделей информационного поиска малого масштаба с использованием всего десяти золотых меток релевантности, то есть моделей с менее чем 100 миллионами параметров. Этот подход был назван PATH – Prompts as Auto-optimized Training Hyperparameters.
Основой этого метода является создание фиктивных запросов документов с использованием языковой модели (LM). Ключевым новшеством является то, что языковая модель автоматически оптимизирует подсказку, которую она использует для создания этих фиктивных запросов, гарантируя оптимизацию качества обучения.
Команда поделилась процедурой, которая выглядит следующим образом. Начальными точками являются текстовый корпус и очень небольшое количество релевантных меток. Затем с использованием LM создаются потенциальные поисковые запросы, которые могут быть соответствующими документам в корпусе. Для создания обучающих данных необходимо создать пары запросов и отрывков. Оптимизация подсказки LM, направляющей создание запроса, является ключевым шагом в повышении качества синтетических данных в ответ на вход из процедуры обучения.
Используя бенчмарк BIRCO, включающий сложные и необычные задачи IR, команда провела испытания и обнаружила, что этот подход значительно улучшает производительность обученных моделей. В частности, модели малого масштаба превосходят RankZephyr и конкурентоспособны с RankLLama, обученными с минимальным количеством размеченных данных и оптимизированными подсказками. Эти последние модели, включающие 7 миллиардов параметров и обученные на наборах данных с более чем 100 000 метками, значительно больше.
Эти результаты демонстрируют, насколько хорошо автоматическая быстрая оптимизация производит искусственные наборы данных высокого качества. Этот подход не только показывает, что эффективные модели IR могут быть обучены с меньшими ресурсами, но и демонстрирует, что с правильными настройками процесса создания данных более маленькие модели могут превзойти намного большие модели.
Проверьте статью. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу более чем 45 тыс. подписчиков на ML SubReddit.
«`


















