
«`html
Решение проблемы «Потерянные посреди» в больших языковых моделях: прорыв в калибровке внимания
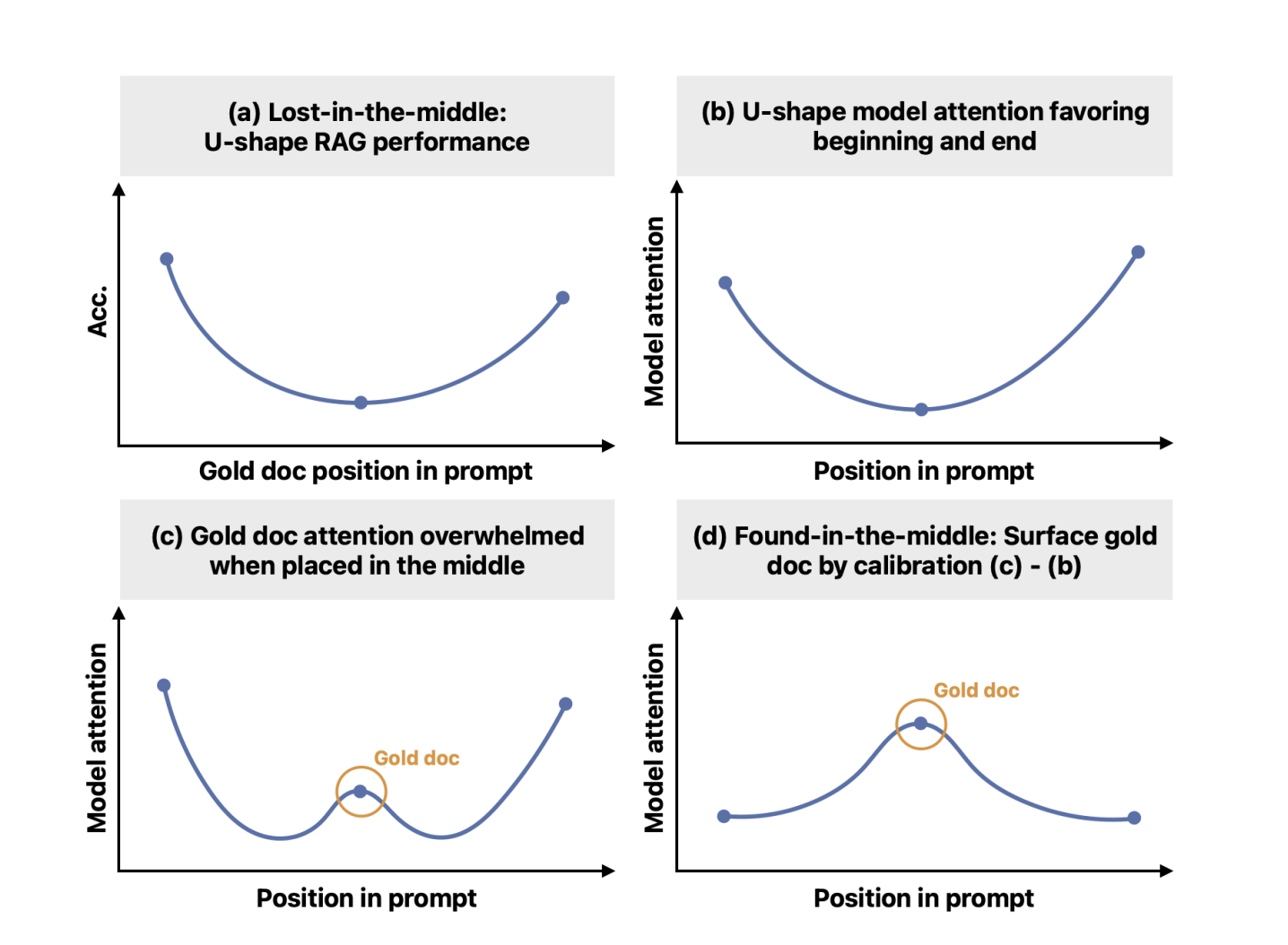
Несмотря на значительные успехи в области больших языковых моделей (LLM), LLM часто нуждаются в помощи с длинными контекстами, особенно там, где информация распределена по всему тексту. LLM теперь могут обрабатывать длинные участки текста в качестве входных данных, но они все еще сталкиваются с проблемой «потерянного посреди». Их способность точно находить и использовать информацию в этом контексте ослабевает, когда соответствующая информация находится дальше от начала или конца. Другими словами, они склонны сосредотачиваться на информации в начале и в конце, игнорируя то, что находится между ними.
Практические решения и ценность
Исследователи из Университета Вашингтона, MIT, Google Cloud AI Research и Google сотрудничали, чтобы решить проблему «потерянного посреди». Несмотря на то, что обучены обрабатывать большие контексты ввода, LLM проявляют врожденный перекос внимания, что приводит к более высокому вниманию к токенам в начале и в конце ввода. Это приводит к снижению точности, когда критическая информация находится посередине. Цель исследования — смягчить позиционный перекос, позволяя модели обращать внимание на контексты исходя из их значимости, независимо от их положения в предложенной последовательности.
Текущие методы решения проблемы «потерянного посреди» часто включают переоценку значимости документов и переупорядочивание наиболее подходящих в начало или конец последовательности ввода. Однако эти методы обычно требуют дополнительного наблюдения или точной настройки и не решают фундаментально способность LLM эффективно использовать информацию в середине последовательности. Чтобы преодолеть эту ограниченность, исследователи предлагают новый механизм калибровки под названием «найденное посреди».
Исследователи впервые установили, что проблема «потерянного посреди» связана с перекосом внимания в форме буквы U. Этот врожденный перекос сохраняется даже при случайном изменении порядка документов. Для проверки своей гипотезы авторы вмешиваются, регулируя распределение внимания, чтобы отражать значимость, а не положение. Они количественно оценивают этот позиционный перекос, измеряя изменения внимания при изменении положения фиксированного контекста ввода.
Предложенный механизм «найденное посреди» разъединяет позиционный перекос от оценок внимания, обеспечивая более точное отражение значимости документов. Эта калибровка включает оценку перекоса и соответствующую корректировку оценок внимания. Эксперименты показывают, что откалиброванное внимание значительно улучшает способность модели находить соответствующую информацию в длинных контекстах, что приводит к улучшению производительности в задачах генерации с использованием поисков.
Исследователи операционализировали этот механизм калибровки для улучшения общей производительности генерации с использованием поисков. Метод калибровки внимания последовательно превосходит неоткалиброванные модели в различных задачах и моделях, включая те, у которых различная длина окна контекста. Подход приводит к улучшениям до 15 процентных пунктов на наборе данных NaturalQuestions. Кроме того, сочетание калибровки внимания с существующими методами переупорядочивания дополнительно улучшает производительность модели, демонстрируя эффективность и дополняющую ценность предложенного решения.
В заключение, предложенный механизм эффективно выявляет и решает проблему «потерянные посреди», связывая ее с врожденным позиционным перекосом внимания в LLM. Механизм «найденное посреди» успешно смягчает этот перекос, позволяя моделям более точно обращаться к значимым контекстам и значительно улучшая производительность в задачах использования длинных контекстов. Этот прорыв открывает новые возможности для улучшения механизмов внимания LLM и их применения в различных приложениях, ориентированных на пользователей.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Телеграм-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Источник: MarkTechPost
«`





















