
«`html
Q*: A Versatile Artificial Intelligence AI Approach to Improve LLM Performance in Reasoning Tasks
Большие языковые модели (LLM) продемонстрировали удивительные способности в решении различных задач рассуждения, выраженных естественным языком, включая математические задачи, генерацию кода и планирование. Однако с увеличением сложности задач рассуждения даже самые передовые LLM сталкиваются с ошибками, галлюцинациями и несоответствиями из-за их авторегрессивной природы. Эта проблема особенно заметна в задачах, требующих нескольких этапов рассуждения, где «Система 1» мышления LLM — быстрое и инстинктивное, но менее точное — оказывается недостаточным. Необходимость более обдуманного, логического мышления «Системы 2» становится критической для точного и последовательного решения сложных задач рассуждения.
Практические решения и ценность
Несколько попыток были предприняты для преодоления вызовов, с которыми сталкиваются LLM в сложных задачах рассуждения. Например, Supervised Fine-Tuning (SFT) и Reinforcement Learning from Human Feedback (RLHF) направлены на согласование выводов LLM с ожиданиями человека. Также были разработаны методы Direct Preference Optimization (DPO) и Aligner для улучшения согласованности. В области улучшения LLM с возможностями планирования были применены методы Tree-of-Thoughts (ToT), A* search и Monte Carlo Tree Search (MCTS). Для математических рассуждений и генерации кода исследовались такие техники, как инженерия подсказок, донастройка с использованием задачно-специфических корпусов и обучение моделей вознаграждения. Однако эти методы часто требуют значительной экспертизы, больших вычислительных ресурсов или задачно-специфических модификаций, что ограничивает их обобщаемость и эффективность.
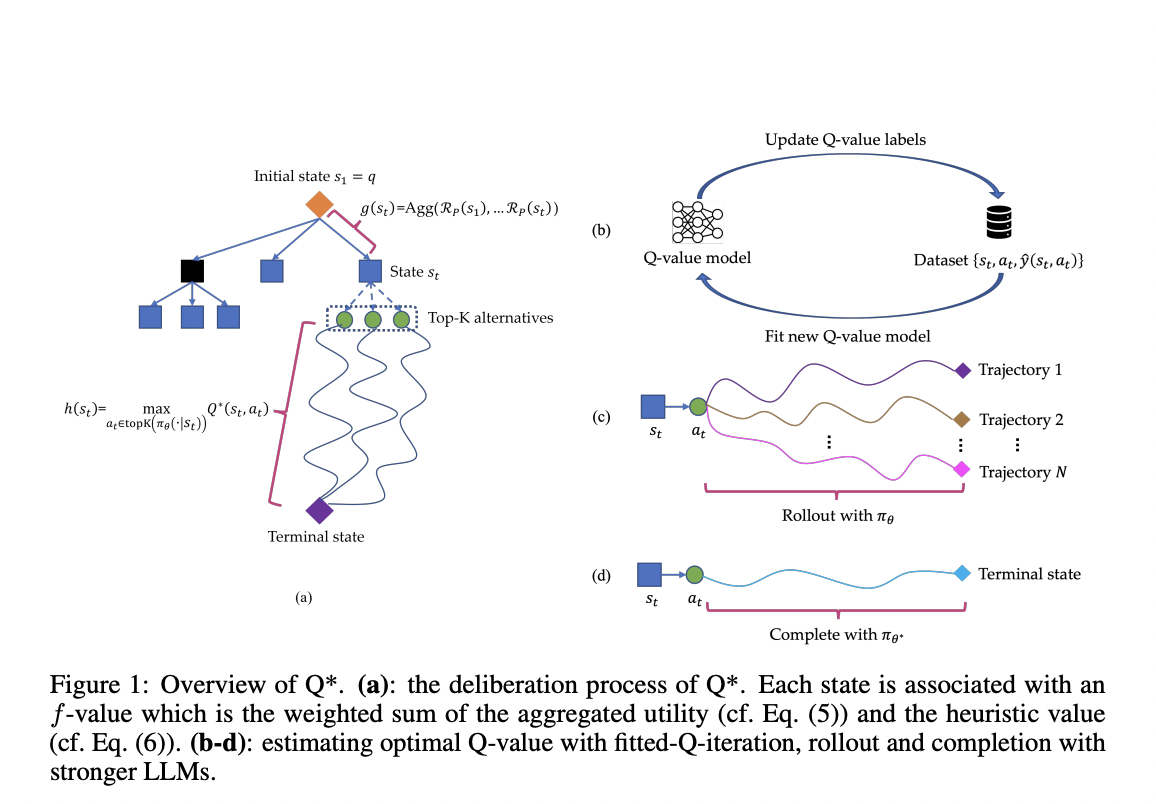
Исследователи из Skywork AI и Nanyang Technological University представляют Q*, надежную структуру, разработанную для улучшения многошаговых рассуждений LLM через обдуманное планирование. Этот подход формализует рассуждение LLM как процесс принятия решений Маркова (MDP), где состояние объединяет вводной запрос и предыдущие этапы рассуждения, действие представляет следующий этап рассуждения, а вознаграждение измеряет успех задачи. Q* вводит общие методы для оценки оптимальных Q-значений пар состояние-действие, включая оффлайн обучение с подкреплением, выбор лучшей последовательности из прогонов и завершение с использованием более мощных LLM. Формализуя многошаговое рассуждение как проблему эвристического поиска, Q* использует модели Q-значений, которые можно подключить и использовать как эвристические функции в рамках алгоритма A*, направляя LLM на выбор наиболее перспективных следующих шагов эффективно.
Фреймворк Q* использует сложную архитектуру для улучшения многошаговых рассуждений LLM. Он формализует процесс как проблему эвристического поиска, используя алгоритм поиска A*. Фреймворк ассоциирует каждое состояние с f-значением, вычисляемым как взвешенная сумма агрегированной полезности и эвристического значения. Агрегированная полезность рассчитывается с использованием функции вознаграждения на основе процесса, а эвристическое значение оценивается с использованием оптимального Q-значения состояния. Q* вводит три метода оценки оптимальных Q-значений: оффлайн обучение с подкреплением, обучение на прогонках и аппроксимация с использованием более мощных LLM. Эти методы позволяют фреймворку учиться на обучающих данных без задачно-специфических модификаций. Процесс обдуманного планирования следует алгоритму поиска A*. Он поддерживает два набора состояний: непосещенные и посещенные. Алгоритм итеративно выбирает состояние с наибольшим f-значением из набора непосещенных, расширяет его с использованием политики LLM и соответственно обновляет оба набора. Этот процесс продолжается до достижения терминального состояния (полной траектории), после чего ответ извлекается из конечного состояния.
Q* продемонстрировал значительное улучшение производительности в различных задачах рассуждения. На наборе данных GSM8K он улучшил Llama-2-7b, достигнув точности 80,8%, превзойдя ChatGPT-turbo. Для набора данных MATH Q* улучшил Llama-2-7b и DeepSeekMath-7b, достигнув точности 55,4%, превзойдя модели, такие как Gemini Ultra (4-shot). В генерации кода Q* улучшил CodeQwen1.5-7b-Chat, достигнув точности 77,0% на наборе данных MBPP. Эти результаты последовательно показывают эффективность Q* в улучшении производительности LLM в задачах математического рассуждения и генерации кода, превзойдя традиционные методы и некоторые закрытые модели.
Q* является эффективным методом преодоления вызова многошагового рассуждения в LLM путем введения надежной структуры обдуманного планирования. Этот подход улучшает способность LLM решать сложные задачи, требующие глубокого, логического мышления, превышающего простую авторегрессивную генерацию токенов. В отличие от предыдущих методов, основанных на задачно-специфических функциях полезности, Q* использует универсальную модель Q-значений, обученную исключительно на данных истинной информации, что делает его легко адаптируемым к различным задачам рассуждения без модификаций. Фреймворк использует модели Q-значений, которые можно подключить и использовать как эвристические функции, эффективно направляя LLM без необходимости задачно-специфической донастройки, сохраняя при этом производительность в различных задачах. Гибкость Q* проистекает из его подхода к рассмотрению одного шага, в отличие от более вычислительно интенсивных методов, таких как MCTS. Обширные эксперименты в математических рассуждениях и генерации кода демонстрируют превосходную производительность Q*, подчеркивая его потенциал значительно улучшить способности LLM в решении сложных проблем.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Q*: A Versatile Artificial Intelligence AI Approach to Improve LLM Performance in Reasoning Tasks
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Q*: A Versatile Artificial Intelligence AI Approach to Improve LLM Performance in Reasoning Tasks.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`





















