
«`html
Групповая относительная оптимизация политики (GRPO): улучшение математического мышления в открытых языковых моделях
GRPO — это новый метод обучения с подкреплением, представленный в документе DeepSeekMath в этом году. GRPO основан на рамке Proximal Policy Optimization (PPO), разработанной для улучшения математического мышления и снижения потребления памяти. Этот метод предлагает несколько преимуществ, особенно подходящих для задач, требующих сложного математического мышления.
Реализация GRPO
Реализация GRPO включает несколько ключевых шагов:
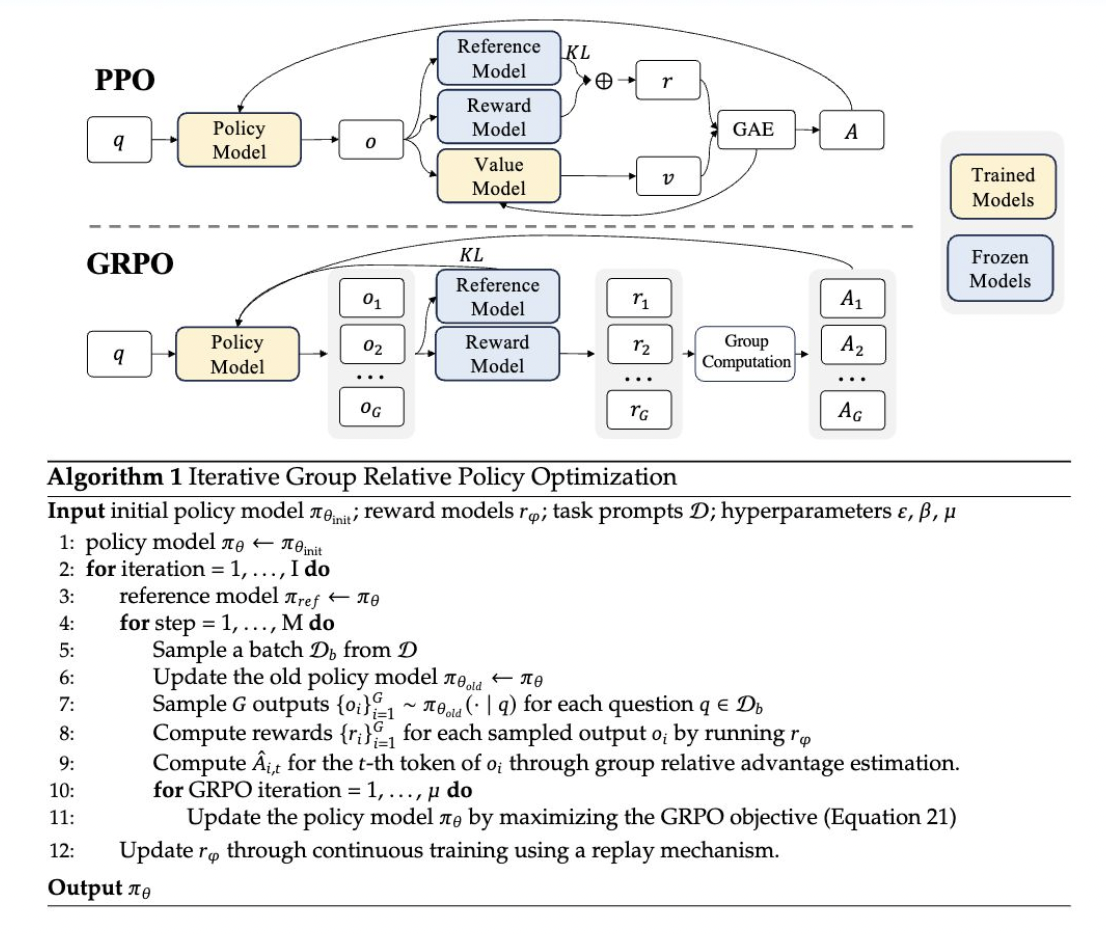
Генерация выводов: текущая политика генерирует несколько выводов для каждого входного вопроса.
Оценка выводов: эти выводы затем оцениваются с использованием модели вознаграждения.
Вычисление преимуществ: среднее значение этих вознаграждений используется в качестве базовой линии для вычисления преимуществ.
Обновление политики: политика обновляется для максимизации цели GRPO, которая включает в себя преимущества и термин расхождения KL.
Этот подход отличается от традиционной PPO тем, что он устраняет необходимость в модели функции ценности, тем самым сокращая потребление памяти и вычислительную сложность. Вместо этого GRPO использует групповые баллы для оценки базовой линии, упрощая процесс обучения и потребности в ресурсах.
Преимущества и польза GRPO
GRPO вводит несколько инновационных особенностей и преимуществ:
Упрощенный процесс обучения: предшествуя модели функции ценности и используя групповые баллы, GRPO уменьшает сложность и объем памяти, обычно связанные с PPO. Это делает процесс обучения более эффективным и масштабируемым.
Термин KL в функции потерь: в отличие от других методов, которые добавляют термин расхождения KL к вознаграждению, GRPO интегрирует этот термин непосредственно в функцию потерь. Это изменение помогает стабилизировать процесс обучения и улучшить производительность.
Улучшение производительности: GRPO продемонстрировал значительное улучшение производительности на математических бенчмарках. Например, он улучшил оценки GSM8K и набора данных MATH примерно на 5%, показывая свою эффективность в улучшении математического мышления.
Сравнение с другими методами
GRPO схож с методом тонкой настройки отборочной выборки (RFT), но включает уникальные элементы, которые выделяют его. Одним из ключевых отличий является его итерационный подход к обучению моделей вознаграждения. Этот итеративный процесс помогает более эффективно настраивать модель, постоянно обновляя ее на основе последних выводов политики.
Применение и результаты
GRPO был применен к DeepSeekMath, модели языка, специфичной для области, разработанной для превосходства в математическом мышлении. Данные обучения с подкреплением состояли из 144 000 промптов Chain-of-Thought (CoT) из набора данных надзорного обучения с тонкой настройкой (SFT). Модель вознаграждения, обученная с использованием процесса «Math-Shepherd», была ключевой при оценке и направлении обновлений политики.
Результаты применения GRPO были обнадеживающими. DeepSeekMath значительно улучшился как в задачах внутри домена, так и в задачах за пределами домена во время фазы обучения с подкреплением. Возможность метода улучшить производительность без использования отдельной модели функции ценности подчеркивает его потенциал для более широкого применения в сценариях обучения с подкреплением.
Заключение
Групповая относительная оптимизация политики (GRPO) значительно продвигает методы обучения с подкреплением, нацеленные на математическое мышление. Его эффективное использование ресурсов, в сочетании с инновационными техниками расчета преимуществ и интеграции расхождения KL, позиционирует его как отличный инструмент для расширения возможностей открытых языковых моделей. Как показано его применением в DeepSeekMath, GRPO имеет потенциал расширить границы того, что языковые модели могут достичь в сложных структурированных задачах, таких как математика.
Источники:
https://arxiv.org/pdf/2312.08935
https://arxiv.org/pdf/2402.03300
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте A Deep Dive into Group Relative Policy Optimization (GRPO) Method: Enhancing Mathematical Reasoning in Open Language Models.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!