
«`html
Крупные языковые модели (LLM) в AI
Крупные языковые модели (LLM) получили значительное признание в индустрии искусственного интеллекта, революционизируя различные приложения, такие как чат, программирование и поиск. Однако эффективное обслуживание нескольких LLM стало критической проблемой для поставщиков конечных точек. Основная проблема заключается в значительных вычислительных требованиях этих моделей, с одной 175B LLM, требующей восемь A100 (80GB) GPU для вывода.
Вызовы и решения
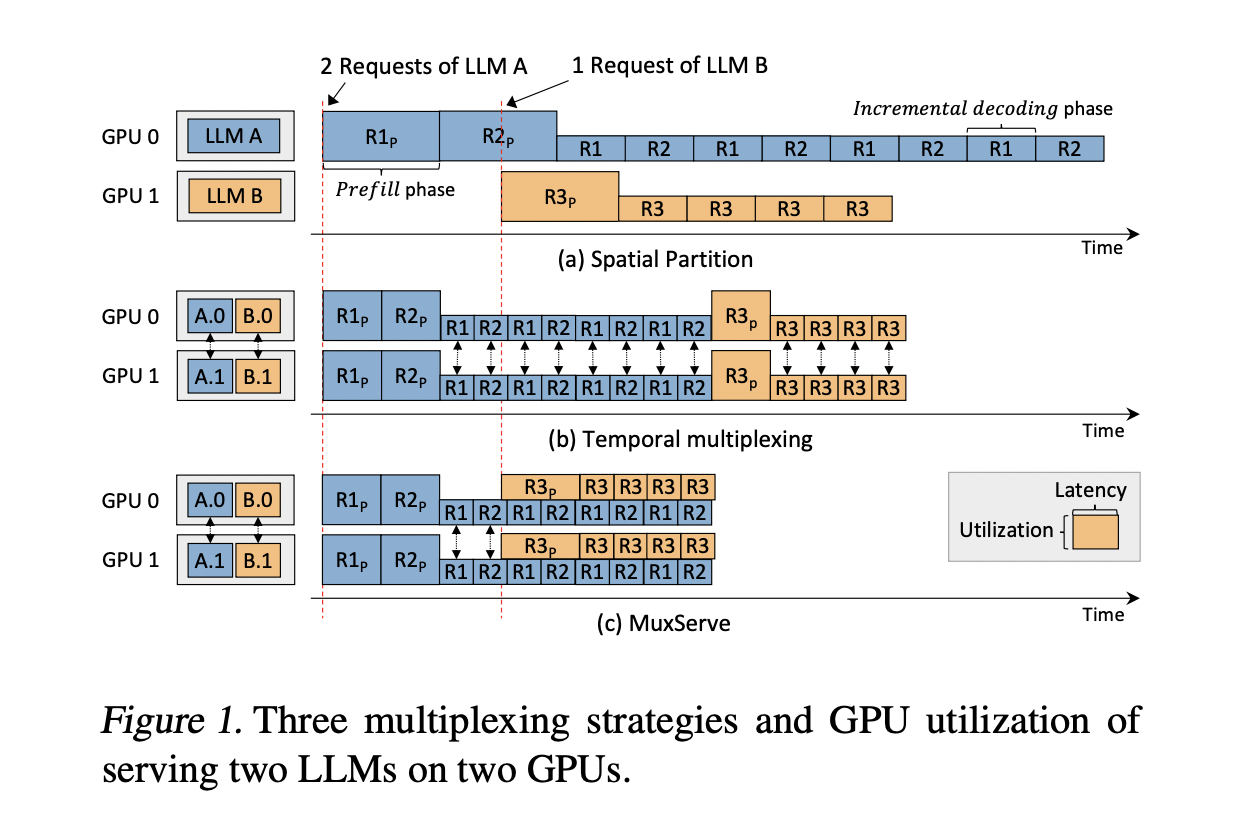
Текущие методологии, в частности, пространственное разделение, должны улучшить использование ресурсов. Этот подход выделяет отдельные группы GPU для каждого LLM, что приводит к недоиспользованию из-за различной популярности моделей и скорости запросов. Существующие попытки решить проблемы обслуживания LLM исследовали различные подходы. Системы обслуживания глубокого обучения сосредоточились на временном мультиплексировании и стратегиях планирования, но они в основном предназначены для более маленьких моделей. Специфические для LLM системы продвинулись благодаря настраиваемым ядрам GPU, параллельным техникам и оптимизациям, таким как управление памятью и выгрузка. Однако эти методы обычно нацелены на одиночный вывод LLM. Техники совместного использования GPU, включая временное и пространственное совместное использование, были разработаны для улучшения использования ресурсов, но они обычно нацелены на более мелкие задачи DNN.
Преимущества MuxServe
Исследователи из нескольких университетов представляют MuxServe, гибкий пространственно-временной мультиплексный подход для обслуживания нескольких LLM, решающий проблемы использования GPU. Система использует жадный алгоритм размещения, адаптивное планирование партий и унифицированный менеджер ресурсов для максимизации эффективности. Путем разделения GPU SM с помощью CUDA MPS MuxServe достигает эффективного пространственно-временного разделения. Этот подход приводит к увеличению пропускной способности до 1,8× по сравнению с существующими системами, что является значительным прорывом в эффективном мульти-LLM обслуживании.
Применение в реальной жизни
MuxServe демонстрирует превосходную производительность как в синтетических, так и в реальных рабочих нагрузках. В синтетических сценариях он достигает до 1,8× большей пропускной способности и обрабатывает на 2,9× больше запросов при достижении 99% SLO по сравнению с базовыми системами. Система эффективно совмещает LLM с различной популярностью и потребностями в ресурсах, улучшая общее использование системы.
Заключение
Это исследование представляет MuxServe как значительный прорыв в области обслуживания LLM. Его инновационный подход к совмещению LLM на основе их популярности и разделение задач приводит к улучшению использования GPU. MuxServe демонстрирует значительные улучшения производительности по сравнению с существующими системами, достигая более высокой пропускной способности и лучшего достижения SLO в различных сценариях рабочей нагрузки.
«`
«`html
Подробнее о проекте и научной статье вы можете узнать на нашем сайте. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
Если вам нужны советы по внедрению ИИ, пишите нам на нашем Telegram-канале. Следите за новостями о ИИ в нашем Telegram-канале или в Twitter.
«`




















