
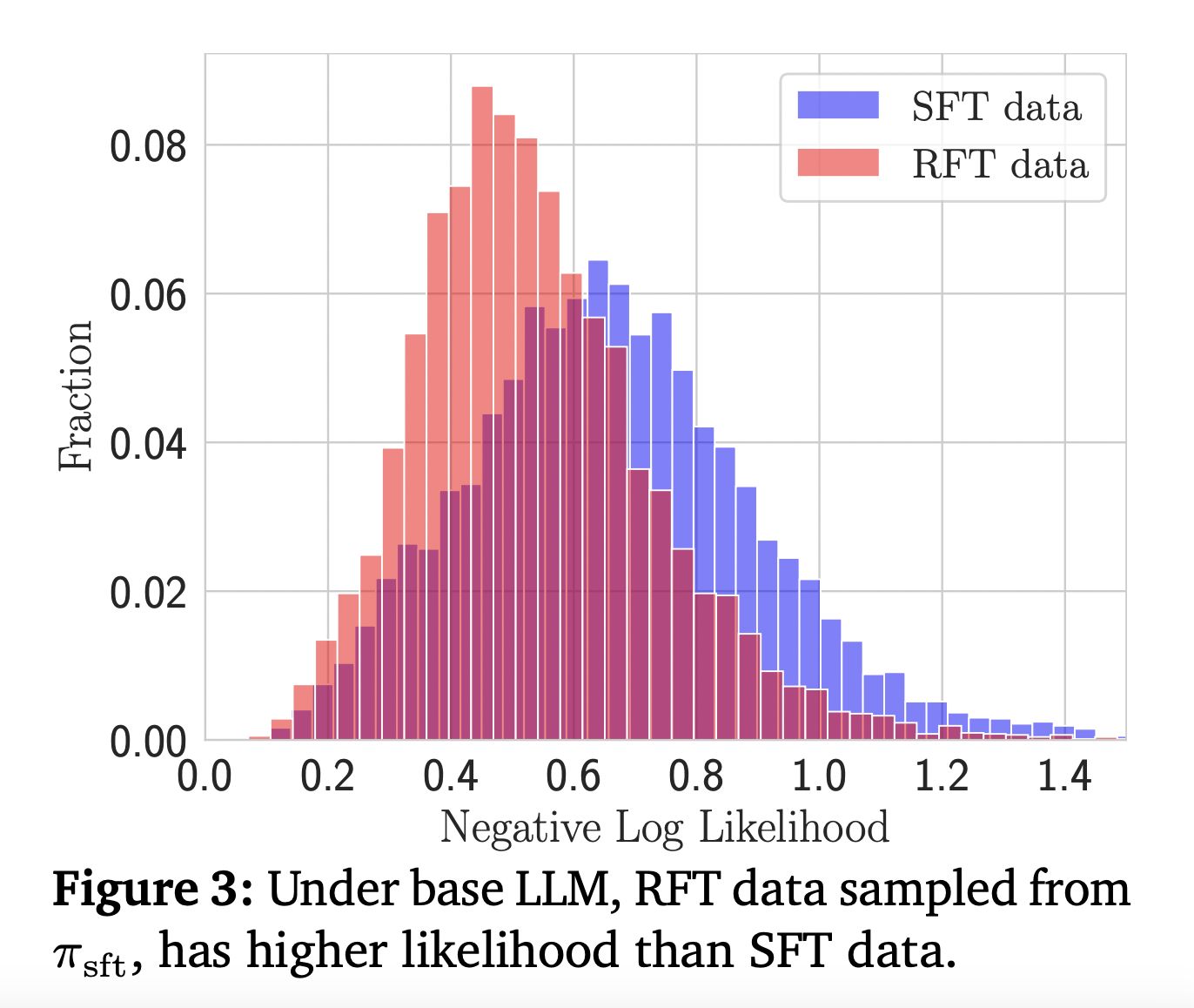
«`html
Исследование роли синтетических данных в улучшении математических способностей LLMs от CMU и Google DeepMind
Большие языковые модели (LLMs) сталкиваются с критическим вызовом в процессе обучения: нехватка высококачественных интернет-данных. Прогнозы показывают, что к 2026 году доступный объем таких данных исчерпается, вынуждая исследователей обращаться к синтетическим данным для обучения. Этот сдвиг представляет как возможности, так и риски. Одни исследования показывают, что масштабирование синтетических данных может улучшить производительность на сложных задачах рассуждения, другие выявляют тревожную тенденцию. Обучение на синтетических данных может потенциально привести к ухудшению производительности модели, усилению предвзятостей, распространению дезинформации и укреплению нежелательных стилевых свойств. Основная проблема заключается в создании синтетических данных, которые эффективно решают проблему нехватки данных, не подвергая качество и целостность результирующих моделей риску. Эта задача особенно сложна из-за текущего недостатка понимания того, как синтетические данные влияют на поведение LLM.
Исследователи из CMU, Google DeepMind и MultiOn представляют исследование, чтобы изучить влияние синтетических данных на математические способности LLM. Оно рассматривает как положительные, так и отрицательные синтетические данные, обнаруживая, что положительные данные улучшают производительность, но с медленной скоростью масштабирования по сравнению с предварительным обучением. Заметно, что самосгенерированные положительные ответы часто соответствуют эффективности в два раза большего объема данных от более крупных моделей. Они представляют надежный подход с использованием отрицательных синтетических данных, контрастируя его с положительными данными на критических этапах. Эта техника, эквивалентная взвешенному обучению с преимуществом на каждом шаге, демонстрирует потенциал увеличения эффективности до восьми раз по сравнению с использованием только положительных данных. Исследование разрабатывает законы масштабирования для обоих типов данных на общих бенчмарках рассуждения, предлагая ценные идеи для оптимизации использования синтетических данных для улучшения производительности LLM в задачах математического рассуждения.
Подробная архитектура предложенного метода включает несколько ключевых компонентов:
- Синтетический поток данных: Побуждает модели, такие как GPT-4 и Gemini 1.5 Pro, генерировать новые проблемы, похожие на реальные.
- Построение набора данных: Создает положительный синтетический набор данных из правильных пар проблем-решений. Генерирует положительные и отрицательные наборы данных, используя модельно-сгенерированные решения.
- Алгоритмы обучения:
- Надзорное дообучение (SFT): Обучает на 𝒟syn с использованием предсказания следующего токена.
- Отказное дообучение (RFT): Использует политику SFT для генерации положительных ответов для проблем из 𝒟syn. Применяет потерю предсказания следующего токена на этих самосгенерированных положительных ответах.
- Оптимизация предпочтений: Использует прямую оптимизацию предпочтений (DPO) для изучения как положительных, так и отрицательных данных. Реализует два варианта: стандартное DPO и DPO на каждом шаге. DPO на каждом шаге идентифицирует «первую яму» в следах решения для фокусировки на критических шагах.
Это позволяет провести всесторонний анализ различных типов синтетических данных и подходов к обучению, позволяя изучить их влияние на математические способности LLM.
Исследование раскрывает значительные идеи масштабирования синтетических данных для математического рассуждения LLM. Масштабирование положительных данных показывает улучшение, но с медленной скоростью по сравнению с предварительным обучением. Удивительно, самосгенерированные положительные данные (RFT) превосходят данные более крупных моделей, удваивая эффективность. Самый впечатляющий результат происходит от стратегического использования отрицательных данных с применением DPO на каждом шаге, что увеличивает эффективность данных в 8 раз по сравнению только с положительными данными. Этот подход последовательно превосходит другие методы, подчеркивая важность тщательного создания и использования как положительных, так и отрицательных синтетических данных в обучении LLM для задач математического рассуждения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 45 тыс. подписчиков.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper from CMU and Google DeepMind Studies the Role of Synthetic Data for Improving Math Reasoning Capabilities of LLMs .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















