
«`html
Глубокие модели обучения, такие как сверточные нейронные сети (CNN) и Vision Transformers, достигли большого успеха во многих визуальных задачах, таких как классификация изображений, обнаружение объектов и семантическая сегментация. Однако их способность обрабатывать различные изменения в данных по-прежнему вызывает большую озабоченность, особенно при использовании в приложениях, требующих повышенной безопасности. Многие исследования оценили устойчивость CNN и Transformers к общим искажениям, изменениям домена, потере информации и атакам. Это показывает, что конструкция модели влияет на ее способность управлять этими проблемами, и устойчивость варьируется в зависимости от различных архитектур. Основной недостаток трансформеров заключается в квадратичном вычислительном масштабировании с размером входных данных, что делает их затратными для выполнения сложных задач.
Робастность моделей глубокого обучения и модели пространства состояний
Робастность глубоких моделей обучения (RDLM) сосредотачивается на том, насколько хорошо традиционно обученная модель может поддерживать высокую производительность при столкновении с естественными и адверсными изменениями в распределении данных. Глубокие модели обучения часто сталкиваются с искажениями данных, такими как шум, размытие, артефакты сжатия и преднамеренные нарушения, созданные для обмана модели в реальных ситуациях. Эти проблемы могут значительно ухудшить их производительность, поэтому для обеспечения надежности и устойчивости этих моделей важно оценить их производительность в этих сложных условиях. С другой стороны, модели пространства состояний (SSM) — это многообещающий подход для моделирования последовательных данных в глубоком обучении. Эти модели преобразуют одномерную последовательность с использованием неявного скрытого состояния.
Анализ производительности VSSMs, Vision Transformers и CNNs
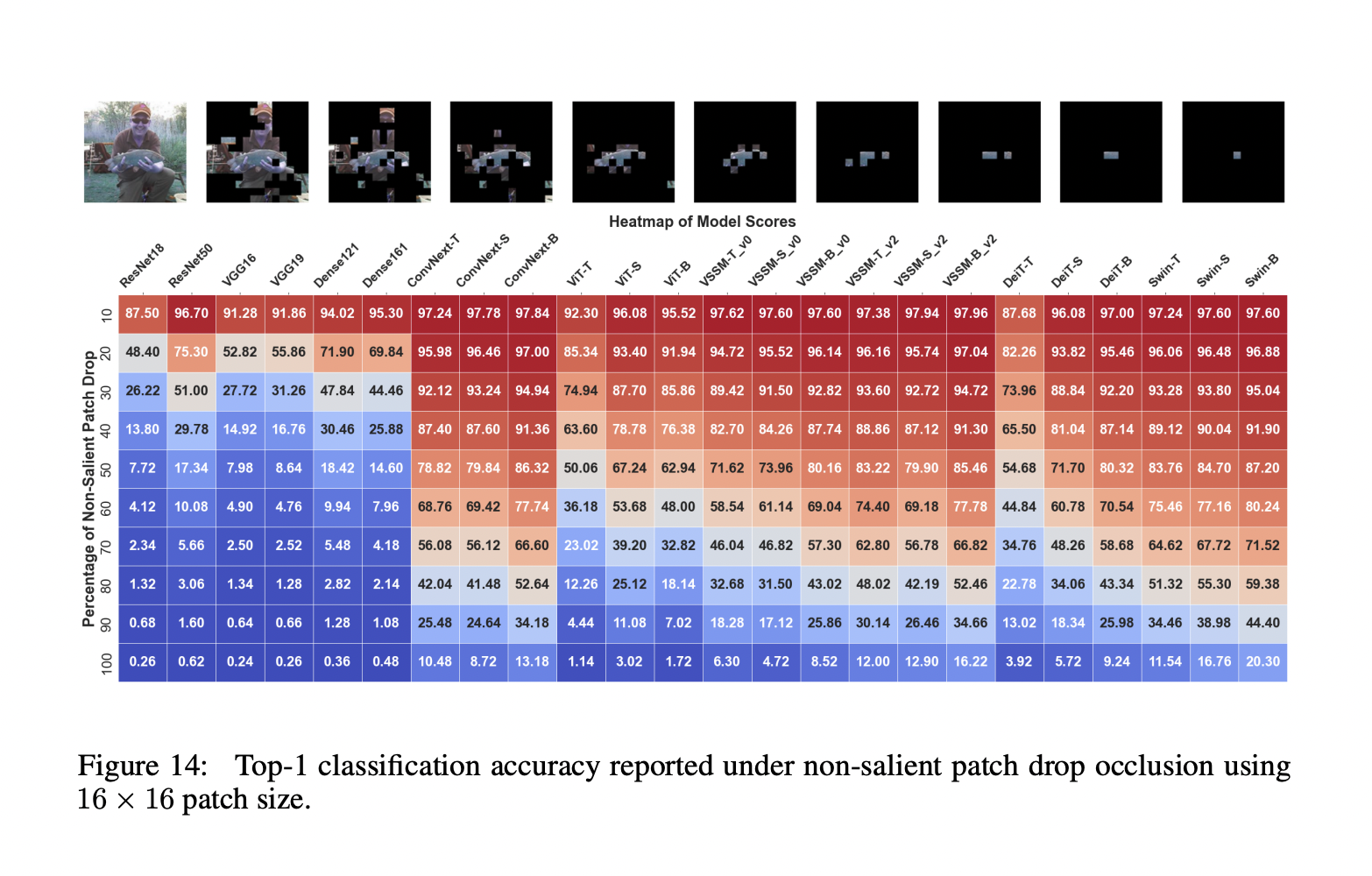
Исследователи из MBZUAI ОАЭ, Университета Linkoping и ANU Австралии представили всесторонний анализ производительности VSSMs, Vision Transformers и CNNs. Этот анализ способен решать различные задачи классификации, обнаружения и сегментации, а также предоставляет ценные идеи относительно их устойчивости и пригодности для реальных приложений. Оценка, проведенная исследователями, разделена на три части, каждая из которых сосредотачивается на важной области устойчивости модели. Первая часть — Эффекты заслонения и потери информации, где оценивается устойчивость VSSMs к потере информации вдоль направлений сканирования и заслонениям. Другие две части — Общие искажения и адверсные атаки.
Ключевые выводы
В первой части было выяснено, что модели ConvNext и VSSM лучше справляются с последовательной потерей информации вдоль направления сканирования, чем модели ViT и Swin. В ситуациях, включающих потерю фрагментов, VSSM показывают наивысшую устойчивость, хотя модели Swin проявляют себя лучше при экстремальной потере информации.
Анализ производительности VSSMs, Vision Transformers и CNNs
Исследователи из MBZUAI ОАЭ, Университета Linkoping и ANU Австралии представили всесторонний анализ производительности VSSMs, Vision Transformers и CNNs. Этот анализ способен решать различные задачи классификации, обнаружения и сегментации, а также предоставляет ценные идеи относительно их устойчивости и пригодности для реальных приложений. Оценка, проведенная исследователями, разделена на три части, каждая из которых сосредотачивается на важной области устойчивости модели. Первая часть — Эффекты заслонения и потери информации, где оценивается устойчивость VSSMs к потере информации вдоль направлений сканирования и заслонениям. Другие две части — Общие искажения и адверсные атаки.
Ключевые выводы
В первой части было выяснено, что модели ConvNext и VSSM лучше справляются с последовательной потерей информации вдоль направления сканирования, чем модели ViT и Swin. В ситуациях, включающих потерю фрагментов, VSSM показывают наивысшую устойчивость, хотя модели Swin проявляют себя лучше при экстремальной потере информации.
Модели VSSM испытывают наименьшее среднее снижение производительности по сравнению с моделями Swin и ConvNext при глобальных искажениях. Для мелкозернистых искажений модели VSSM превосходят все вариации трансформеров и соответствуют им.
При адверсных атаках меньшие модели VSSM проявляют большую устойчивость к атакам в белом ящике по сравнению с их аналогами Swin Transformer. Модели VSSM сохраняют устойчивость более 90% к сильным низкочастотным искажениям, но их производительность быстро падает при атаках высокой частоты.
В заключение, исследователи тщательно оценили устойчивость моделей Vision State-Space (VSSMs) к различным естественным и адверсным воздействиям, показав их преимущества и недостатки по сравнению с трансформерами и CNNs. Эксперименты раскрывают возможности и ограничения VSSMs в обработке заслонений, общих искажений и адверсных атак, а также их способность адаптироваться к изменениям в составе объекта и фона в сложных визуальных сценах. Это исследование будет руководить будущими исследованиями по улучшению надежности и эффективности систем визуального восприятия в реальных ситуациях.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу более 45 тыс. участников в подразделе ML на Reddit.
The post Comprehensive Analysis of The Performance of Vision State Space Models (VSSMs), Vision Transformers, and Convolutional Neural Networks (CNNs) appeared first on MarkTechPost.
«`



















