
«`html
Исследование на мультимодальными моделями больших языков (MLLM) и их практическое применение
Исследования по мультимодальным большим языковым моделям (MLLM) фокусируются на интеграции визуальных и текстовых данных для улучшения способностей искусственного интеллекта к рассуждению. Путем объединения этих модальностей MLLM может интерпретировать сложную информацию из различных источников, таких как изображения и текст, что позволяет выполнять задачи, такие как визуальное ответ на вопросы и решение математических задач с большей точностью и глубиной понимания. Этот междисциплинарный подход использует преимущества как визуальных, так и языковых данных, целью создать более надежные системы искусственного интеллекта, способные понимать и взаимодействовать с миром, подобно людям.
Проблемы и решения
Одной из основных проблем в создании эффективных MLLM является их неспособность решать сложные математические задачи, содержащие визуальный контент. Несмотря на их профессионализм в решении текстовых математических задач, эти модели часто нуждаются в улучшении при интерпретации и рассуждении на основе визуальной информации. Это означает необходимость улучшения наборов данных и методологий, которые лучше интегрируют мультимодальные данные. Исследователи стремятся создать модели, способные понимать текст и извлекать содержательные идеи из изображений, диаграмм и других визуальных средств, критически важных в областях образования, науки и технологий.
Существующие методы улучшения математического рассуждения MLLM включают подходы с использованием подсказок и тонкой настройки. Методы с использованием подсказок используют скрытые способности моделей через тщательно разработанные подсказки, тогда как методы тонкой настройки корректируют параметры модели, используя данные рассуждения из реальных или синтетических источников. Однако текущие открытые наборы данных с инструкциями для изображений имеют ограниченный охват, содержащие небольшое количество пар вопрос-ответ на изображение, что ограничивает возможности моделей полноценно использовать визуальную информацию. Ограничения этих наборов данных затрудняют развитие MLLM и требуют создания более всесторонних и разнообразных наборов данных для эффективного обучения этих моделей.
Значимость Math-LLaVA и MathV360K
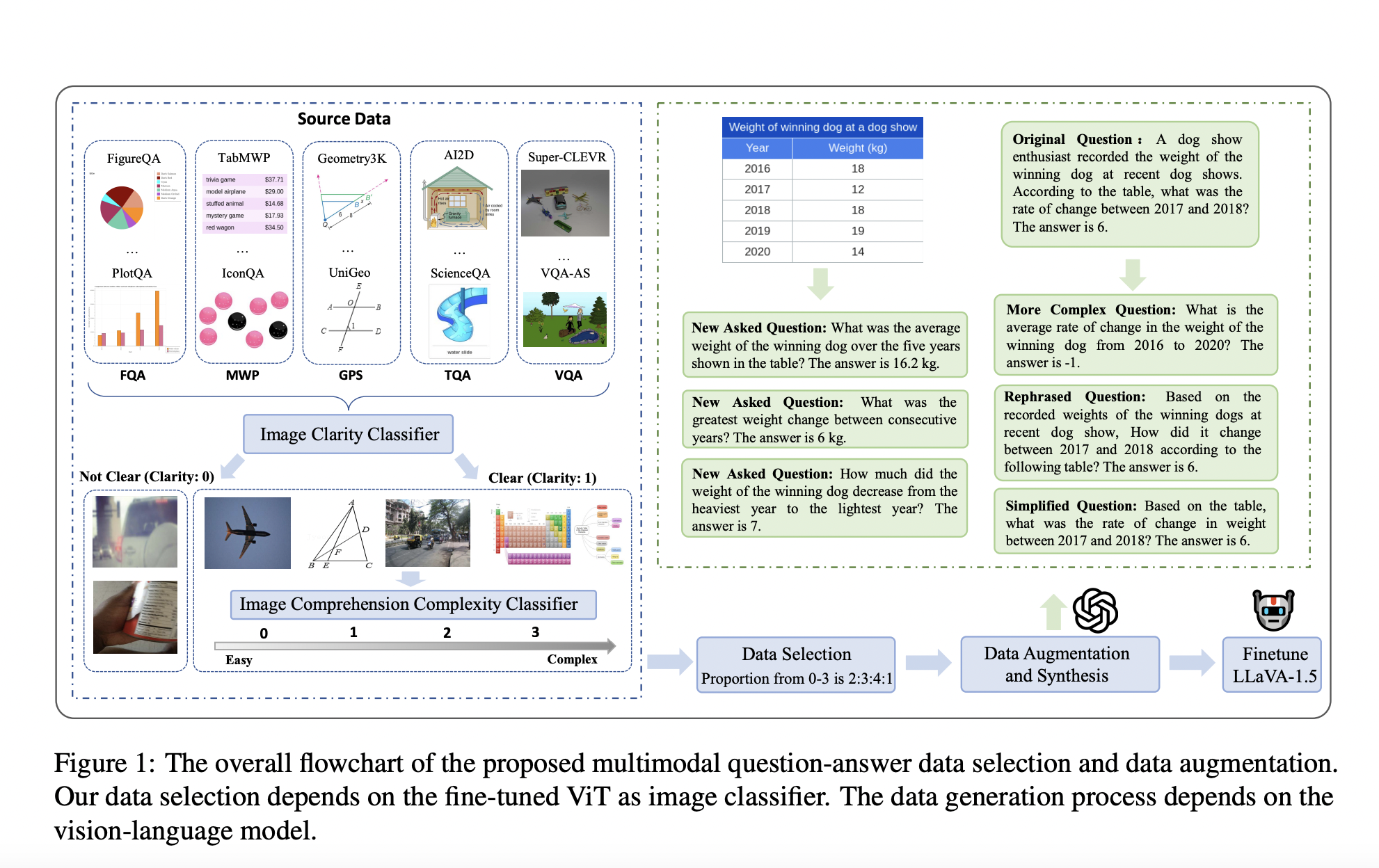
Исследователи из университетов, включая Университет электронной науки и технологии Китая, Университет технологии и дизайна Сингапура, Университет Тунджи и Национальный университет Сингапура, представили Math-LLaVA, модель, тонко настроенную с помощью нового набора данных под названием MathV360K. Этот набор данных включает 40 тыс. высококачественных изображений и 320 тыс. синтезированных пар вопрос-ответ, созданных с целью улучшить широту и глубину мультимодальных математических способностей рассуждения. Представление Math-LLaVA является значительным шагом вперед в данной области, обращая внимание на пробелы, оставленные предыдущими наборами данных и методами.
Набор данных MathV360K был создан путем выбора 40 тыс. высококачественных изображений из 24 существующих наборов данных, фокусирующихся на предметах, таких как алгебра, геометрия и визуальные ответы на вопросы. Исследователи синтезировали 320 тыс. новых пар вопрос-ответ на основе этих изображений для улучшения разнообразия и сложности набора данных. Этот всесторонний набор данных затем использовался для тонкой настройки модели LLaVA-1.5, что привело к разработке Math-LLaVA. Процесс выбора изображений включал строгие критерии для обеспечения ясности и сложности с целью охвата широкого спектра математических концепций и типов вопросов. Синтез дополнительных пар вопрос-ответ включал создание разнообразных вопросов, исследующих различные аспекты изображений и требующих нескольких шагов рассуждения, дополнительно улучшая надежность набора данных.
Math-LLaVA продемонстрировала значительные улучшения, достигнув 19-пунктового прироста на MathVista Minutest split по сравнению с исходной моделью LLaVA-1.5. Кроме того, она продемонстрировала улучшенную обобщаемость и показала хорошие результаты на бенчмарке MMMU. В частности, Math-LLaVA достигла точности 57,7% на подмножестве GPS, превзойдя G-LLaVA-13B, обученную на 170 тыс. высококачественных геометрических изображений с подписями и парами вопрос-ответ. Эти результаты подчеркивают эффективность разнообразного и всестороннего набора данных MathV360K в улучшении мультимодальных математических способностей рассуждения MLLM. Производительность модели на различных бенчмарках подчеркивает ее способность обобщаться на различные задачи математического рассуждения, делая ее ценным инструментом для широкого спектра применений.
Заключение
Исследование подчеркивает критическую необходимость высококачественных разнообразных мультимодальных наборов данных для улучшения математического рассуждения в MLLM. Путем разработки и тонкой настройки Math-LLaVA с использованием MathV360K исследователи значительно улучшили производительность и обобщаемость модели, демонстрируя важность разнообразия и синтеза наборов данных в продвижении возможностей искусственного интеллекта. Набор данных MathV360K и модель Math-LLaVA представляют собой значительный прогресс в данной области, обеспечивая надежную основу для дальнейших исследований и разработок. Эта работа не только подчеркивает потенциал MLLM в трансформации различных областей путем интеграции визуальной и текстовой информации, но и вдохновляет надежду на будущее искусственного интеллекта, проложив путь к более сложным и способным системам искусственного интеллекта.
Проверьте статью. Вся заслуга за это исследование принадлежит ученым проекта. Также не забывайте подписываться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вы полюбите наш рассылку.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Оригинальная публикация: Math-LLaVA: A LLaVA-1.5-based AI Model Fine-Tuned with MathV360K Dataset
«`




















