
«`html
Ограничения больших языковых моделей (LLM): новые бенчмарки и метрики для задач классификации
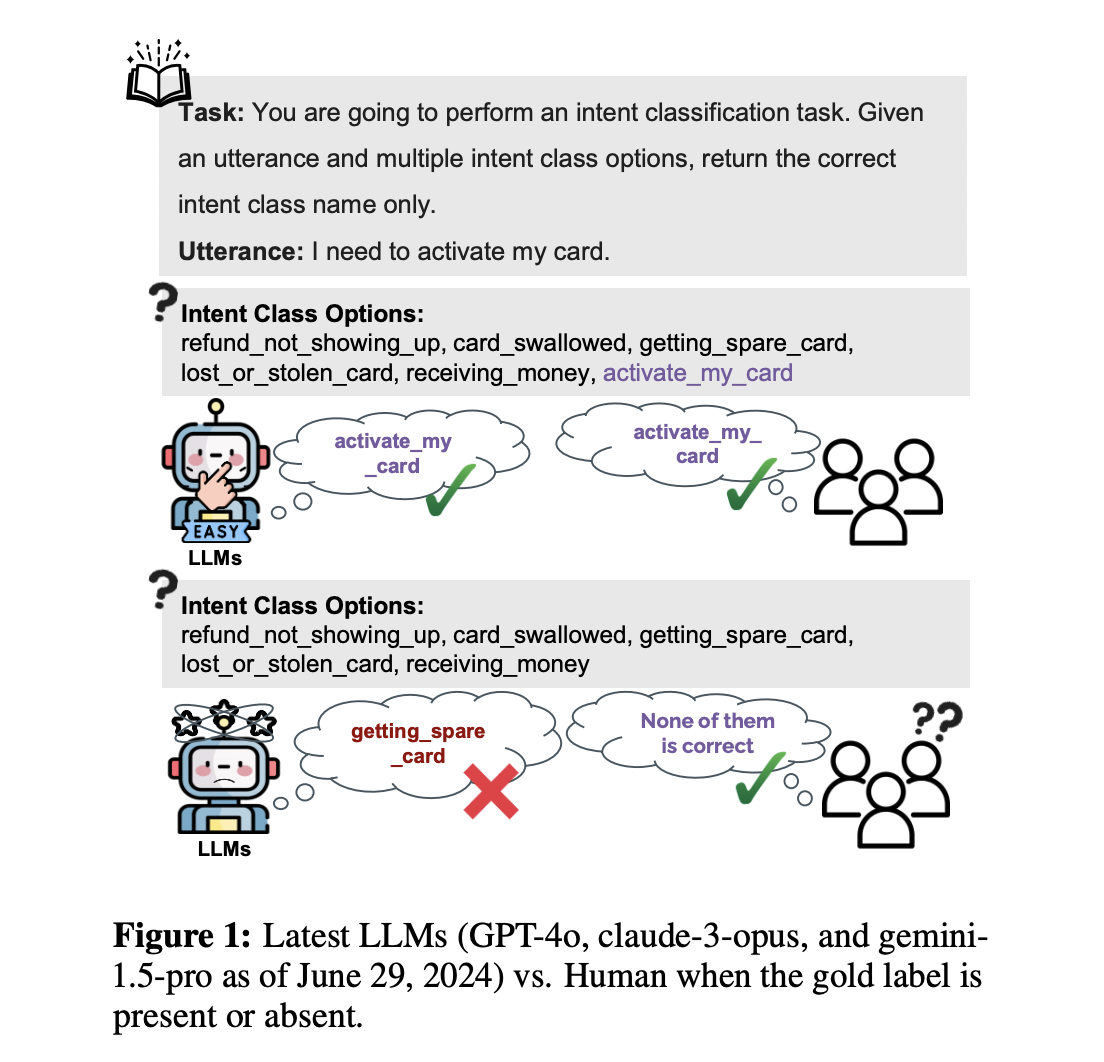
Большие языковые модели (LLM) продемонстрировали впечатляющую производительность в ряде задач, особенно в задачах классификации. Однако их способность выбирать среди вариантов, даже если ни один из них не является правильным, вызывает серьезные опасения относительно их реального понимания и интеллекта в сценариях классификации.
Проблемы отсутствия неопределенности в LLM
Отсутствие неопределенности в LLM вызывает две основные проблемы:
- Гибкость и обработка меток: LLM могут работать с любым набором меток, даже сомнительной точности. Для избежания введения пользователей в заблуждение они должны имитировать поведение человека, распознавая точные метки или указывая на их отсутствие.
- Дискриминационные и генеративные возможности: LLM, в основном, предназначены для генеративных моделей и часто не обладают дискриминационными возможностями. Существующие показатели могут недооценивать полезность LLM.
Новые бенчмарки и метрики
В недавних исследованиях были представлены три общих задачи категоризации в качестве бенчмарков для дальнейших исследований:
- BANK77: Задача классификации намерений.
- MC-TEST: Задача вопросов-ответов с множественным выбором.
- EQUINFER: Недавно разработанная задача, определяющая правильное уравнение из четырех вариантов на основе окружающих абзацев в научных статьях.
Этот набор бенчмарков назван KNOW-NO и включает проблемы классификации с различными размерами, длинами и областями меток, включая пространства меток на уровне экземпляра и задачи.
Также была предложена новая метрика под названием OMNIACCURACY для оценки производительности LLM с большей точностью. Эта статистика оценивает навыки категоризации LLM, объединяя их результаты из двух измерений рамки KNOW-NO: Accuracy-W/-GOLD и ACCURACY-W/O-GOLD.
Основные вклады
Команда суммировала свои основные вклады следующим образом:
- Это первое исследование, которое обращает внимание на ограничения LLM, когда правильные ответы отсутствуют в задачах классификации.
- Была представлена CLASSIFY-W/O-GOLD, новая рамка для оценки LLM и описания этой задачи.
- Был представлен бенчмарк KNOW-NO, включающий одну новую задачу и две известные задачи категоризации, для оценки LLM в сценарии CLASSIFY-W/O-GOLD.
- Была предложена метрика OMNIACCURACY, объединяющая результаты при наличии и отсутствии правильных меток для оценки производительности LLM в задачах классификации.
Подробнее ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Статья опубликована на портале MarkTechPost.
«`



















