
«`html
Создание синтетических данных для обучения больших языковых моделей
Создание синтетических данных стало ключевым элементом обучения больших языковых моделей (LLM). Это направление сосредотачивается на создании искусственных наборов данных, имитирующих реальные данные, что позволяет исследователям эффективно обучать и оценивать модели машинного обучения без ущерба для конфиденциальности или необходимости обширного сбора данных. Методология создания синтетических данных направлена на предоставление разнообразных и масштабируемых наборов данных для улучшения устойчивости и производительности LLM в различных приложениях.
Основные вызовы в создании синтетических данных
Основной вызов в создании синтетических данных заключается в создании разнообразных данных в масштабе. Традиционные методы часто сталкиваются с проблемой поддержания как разнообразия, так и масштабируемости. Подходы, основанные на экземплярах, ограничены разнообразием исходного набора данных. Методы, основанные на ключевых точках, пытаются разнообразить синтетические данные, используя отобранный список ключевых точек, но этот процесс сложно масштабировать на различные области из-за необходимости исчерпывающего отбора. В результате эти методы часто не могут создавать наборы данных, охватывающие широкий спектр сценариев и применений.
Методы создания синтетических данных
Текущие методы создания синтетических данных обычно включают подходы, основанные на экземплярах и ключевых точках. Методы, основанные на экземплярах, используют исходный корпус для создания новых экземпляров, но их разнообразие ограничено начальным корпусом. Методы, основанные на ключевых точках, полагаются на обширный список ключевых точек, что затрудняет их полный отбор и ограничивает применение только к определенным областям. Эти методы, хотя и полезны, часто не могут обеспечить достаточно разнообразные и масштабируемые синтетические наборы данных, необходимые для продвинутого обучения и применения LLM.
Persona Hub: новаторская методология синтеза данных
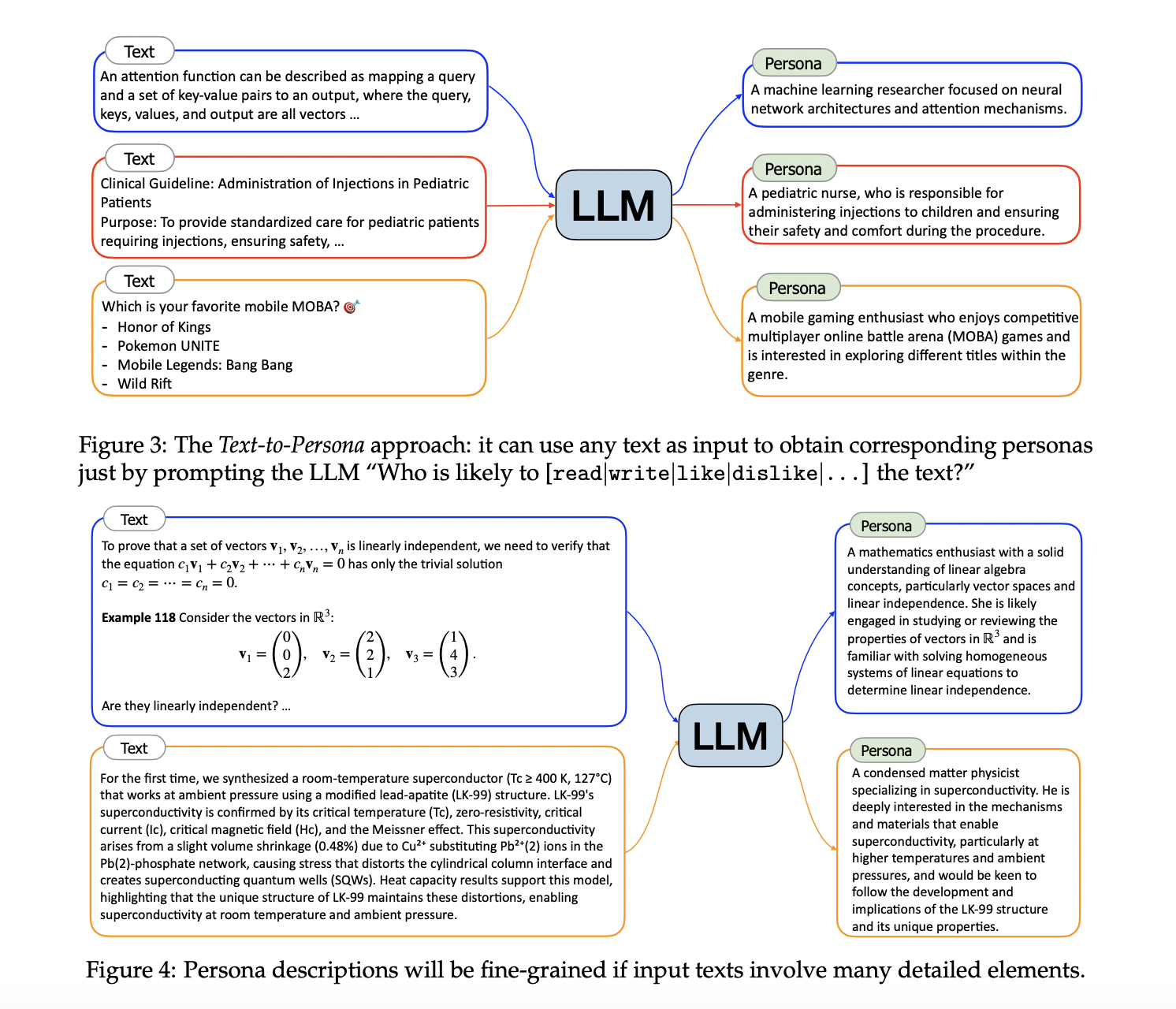
Исследователи из Tencent AI Lab представили Persona Hub, новаторскую методологию синтеза данных на основе персон. Этот подход использует коллекцию из одного миллиарда разнообразных персон, автоматически собранных из веб-данных, для генерации синтетических данных. Persona Hub позволяет LLM создавать данные с различных точек зрения, улучшая разнообразие и масштабируемость. Ассоциируя синтетические данные с конкретными персонами, данная методология может направлять LLM к созданию разнообразных и контекстно насыщенных наборов данных, преодолевая ограничения предыдущих методов.
Persona Hub включает в себя один миллиард персон, представляющих 13% населения мира, каждая из которых ассоциирована с уникальными знаниями, опытом, интересами и профессиями. Эта коллекция позволяет генерировать синтетические данные для различных сценариев, направляя LLM с использованием конкретных персон. Персоны выступают в качестве распределенных носителей мировых знаний, направляя LLM на создание разнообразных и контекстно насыщенных синтетических данных. Исследователи разработали масштабируемые подходы к выводу этих персон из обширных веб-данных, используя методы текст-к-персоне и персона-к-персоне. Подход текст-к-персоне выводит персоны из конкретных текстов, в то время как подход персона-к-персоне расширяет разнообразие персон через межличностные отношения.
Персона-ориентированный подход показал впечатляющие количественные результаты. Исследователи создали 50 000 математических задач, 50 000 задач на логическое мышление, 50 000 инструкций, 10 000 текстов с обширными знаниями, 10 000 игровых NPC и 5 000 инструментов. В рамках оценки модель, настроенная на 1,07 миллиона синтетических математических задач, достигла точности 79,4% на тестовом наборе из 11 600 экземпляров, превзойдя все протестированные открытые LLM. На тесте MATH модель достигла точности 64,9%, сравнимой с производительностью gpt-4-turbo-preview, демонстрируя значительные улучшения возможностей LLM благодаря персона-ориентированному синтезу данных.
Исследователи подчеркнули значительные улучшения производительности LLM и глубокое влияние персона-ориентированного синтеза данных на обучение и развитие LLM. Благодаря использованию 1 миллиарда персон в Persona Hub, исследователи смогли создать разнообразные синтетические наборы данных, значительно улучшающие возможности LLM. Эта методология оказалась эффективной в различных сценариях синтеза данных, демонстрируя свой потенциал стать стандартной практикой в создании синтетических данных.
Перспективы применения методологии
Методология персона-ориентированного синтеза данных исследователей из Tencent AI Lab решает ограничения традиционных методов путем внедрения масштабируемого и разнообразного подхода. Обширная коллекция персон в Persona Hub облегчает создание богатых и разнообразных синтетических данных, продвигая область обучения и применения LLM. Этот инновационный метод обещает улучшить возможности LLM и расширить их применимость в реальном мире. Предоставляя надежное решение для вызовов создания синтетических данных, данное исследование имеет потенциал для значительных достижений в области искусственного интеллекта и машинного обучения.
Подробнее о статье и проекте вы можете узнать на нашем сайте. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу 45 тыс. подписчиков на ML SubReddit.
«`



















