
«`html
Большие языковые модели (LLM)
Большие языковые модели (LLM) привлекли значительное внимание своей впечатляющей производительностью в различных задачах, от резюмирования новостей до написания кода и ответов на тривиальные вопросы. Их эффективность применяется в реальных приложениях, например, модели, такие как GPT-4, успешно прошли юридические и медицинские экзамены. Однако у LLM есть две критические проблемы: галлюцинации и различия в производительности. Галлюцинации, когда LLM генерируют правдоподобный, но неточный текст, представляют риски в задачах фактического запоминания. Различия в производительности проявляются как несогласованная надежность в различных подмножествах входных данных, часто связанных с чувствительными атрибутами, такими как раса, пол или язык. Эти проблемы подчеркивают необходимость продолжения разработки разнообразных бенчмарков для оценки надежности LLM и выявления потенциальных проблем справедливости. Создание комплексных бенчмарков критично не только для оценки общей производительности, но и для количественной оценки и устранения различий в производительности, в конечном итоге работая над созданием моделей, которые работают справедливо для всех групп пользователей.
Исследование LLM фактического запоминания
Существующие исследования фактического запоминания LLM показали разнообразные результаты, с моделями, демонстрирующими определенное мастерство, но также склонными к вымыслу. Исследования связывали точность с популярностью сущности, но в основном сосредотачивались на общих показателях ошибок, а не на географических различиях. В широком контексте предвзятости в ИИ, наблюдались различия в различных демографических группах в различных областях. Однако отсутствовало комплексное, систематическое исследование различий по странам в фактическом запоминании LLM, что подчеркивает необходимость более надежного и географически чувствительного подхода к оценке.
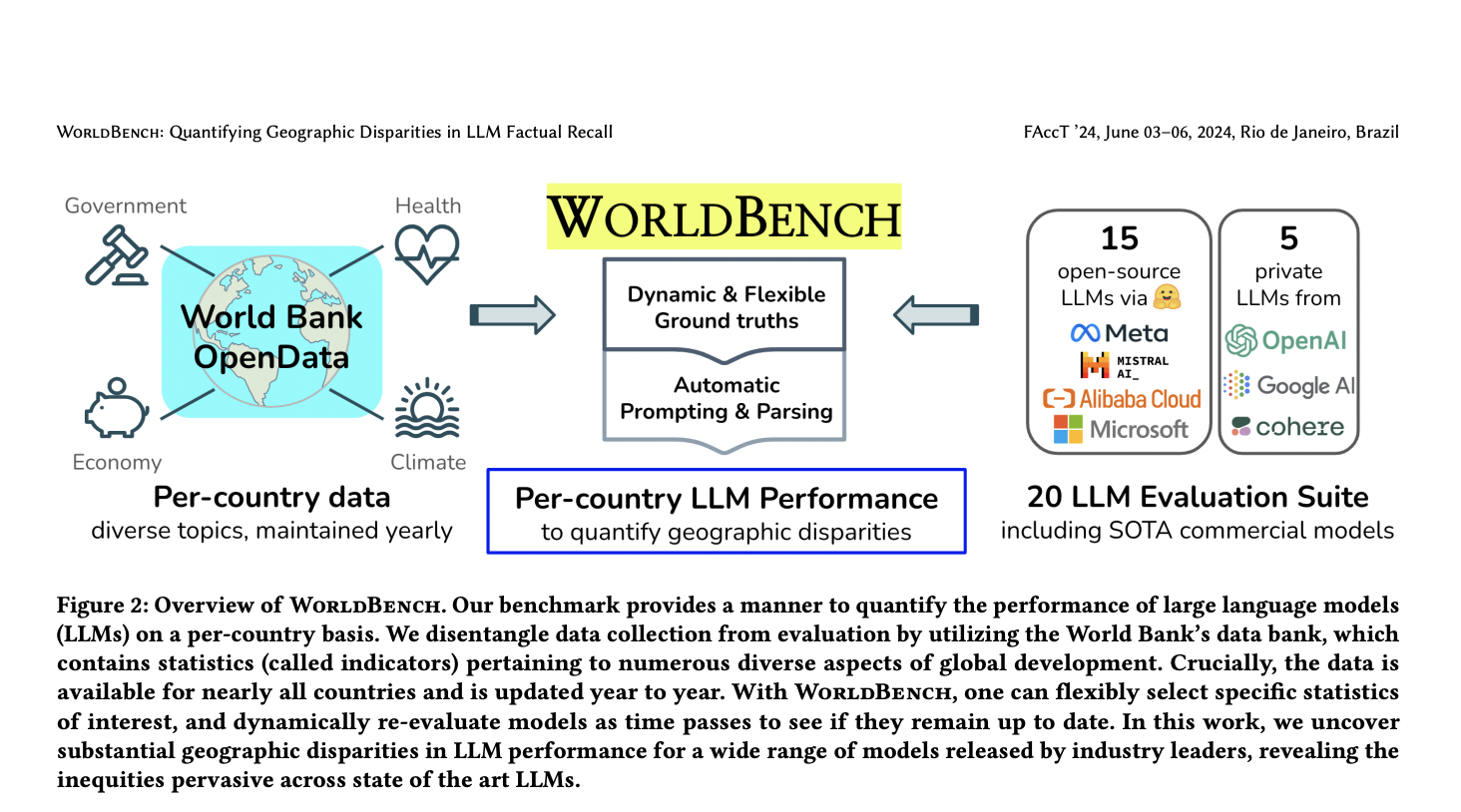
WorldBench: новый метод оценки LLM
Исследователи из Университета Мэриленда и Мичиганского государственного университета предлагают робастный бенчмарк под названием WorldBench для изучения потенциальных географических различий в возможностях фактического запоминания больших языковых моделей (LLM). Этот подход направлен на определение, демонстрируют ли LLM различные уровни точности при ответах на вопросы о разных частях мира. WorldBench использует страновые индикаторы от Всемирного банка, используя автоматизированный, независимый от индикаторов метод генерации и анализа. Бенчмарк включает 11 разнообразных индикаторов для примерно 200 стран, генерируя 2 225 вопросов на каждую LLM. Исследование оценивает 20 современных LLM, выпущенных в 2023 году, включая как открытые модели, такие как Llama-2 и Vicuna, так и частные коммерческие модели, такие как GPT-4 и Gemini. Этот комплексный метод оценки позволяет систематически анализировать производительность LLM в различных географических регионах и группах доходов.
Использование данных Всемирного банка
WorldBench создан с использованием статистики Всемирного банка, мировой организации, отслеживающей множество различных развивающихся индикаторов почти в 200 странах. Этот подход предлагает несколько уникальных преимуществ: справедливое представление всех стран, гарантированное качество данных от авторитетного источника и гибкость в выборе индикаторов. Бенчмарк включает 11 разнообразных индикаторов, что приводит к 2 225 вопросам, отражающим в среднем 202 страны на индикатор.
Методология оценки
Процесс оценки включает стандартизированный метод генерации, используя шаблон с базовой инструкцией и примером. Автоматизированная система анализа извлекает числовые значения из выводов LLM, используя абсолютную относительную ошибку в качестве метрики сравнения. Эффективность пайплайна была подтверждена через ручные исследования, подтверждающие его полноту и правильность. Фактические значения определяются путем усреднения статистики за последние три года для максимального включения стран. Эта комплексная методология позволяет систематически анализировать производительность LLM в различных географических регионах и группах доходов.
Результаты исследования
Исследование показало значительные географические различия в фактическом запоминании LLM в различных регионах и группах доходов. В среднем Северная Америка и Европа и Центральная Азия испытали самые низкие уровни ошибок (0,316 и 0,321 соответственно), в то время как Южная Африка имела самый высокий (0,461), примерно в 1,5 раза выше, чем в Северной Америке. Уровни ошибок стабильно увеличивались с уменьшением уровня дохода стран, с самыми низкими ошибками в высокодоходных странах (0,346) и самыми высокими в низкодоходных (0,480).
На уровне каждой страны различия были еще более выраженными. 15 стран с наименьшими уровнями ошибок были все высокодоходными, в основном европейскими, тогда как 15 стран с наибольшими ошибками были все низкодоходными. Удивительно, уровни ошибок почти утроились между этими двумя группами. Эти различия были последовательны для всех 20 оцененных LLM и всех 11 использованных индикаторов, превышая ожидаемые различия от случайной категоризации стран. Даже лучшие LLM показали значительные возможности для улучшения, с наименьшей средней абсолютной относительной ошибкой на уровне 0,19 и большинство моделей около 0,4.
Заключение
Это исследование представляет WorldBench, робастный бенчмарк для количественной оценки географических различий в фактическом запоминании LLM, раскрывая всеохватывающие и последовательные предвзятости в 20 оцененных LLM. Исследование показывает, что западные и более богатые страны последовательно испытывают более низкие уровни ошибок в задачах фактического запоминания. Используя данные Всемирного банка, WorldBench предлагает гибкую и постоянно обновляемую платформу для оценки этих различий. Этот бенчмарк служит ценным инструментом для выявления и устранения географических предвзятостей в LLM, что может способствовать развитию будущих моделей, работающих справедливо во всех регионах и по уровням дохода. В конечном итоге WorldBench направлен на создание более глобально инклюзивных и справедливых языковых моделей, которые могут эффективно служить пользователям со всех уголков мира.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также подписывайтесь на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу на Reddit.
Оригинальная статья: WorldBench: A Dynamic and Flexible LLM Benchmark Composed of Per-Country Data from the World Bank.
«`





















