
«`html
Исследование моделей видео-языкового восприятия (VLM)
Исследование моделей видео-языкового восприятия (VLM) приобрело значительный импульс, благодаря их потенциалу революционизировать различные приложения, включая визуальную помощь для людей с нарушениями зрения. Однако текущие оценки этих моделей часто нуждаются в большем внимании к сложностям, вносимым множественными объектами и различными культурными контекстами. Двое заметных исследователей проливают свет на эти проблемы, исследуя тонкости галлюцинации объектов в моделях видео-языкового восприятия и важность культурной инклюзивности в их применении.
Галлюцинация множественных объектов
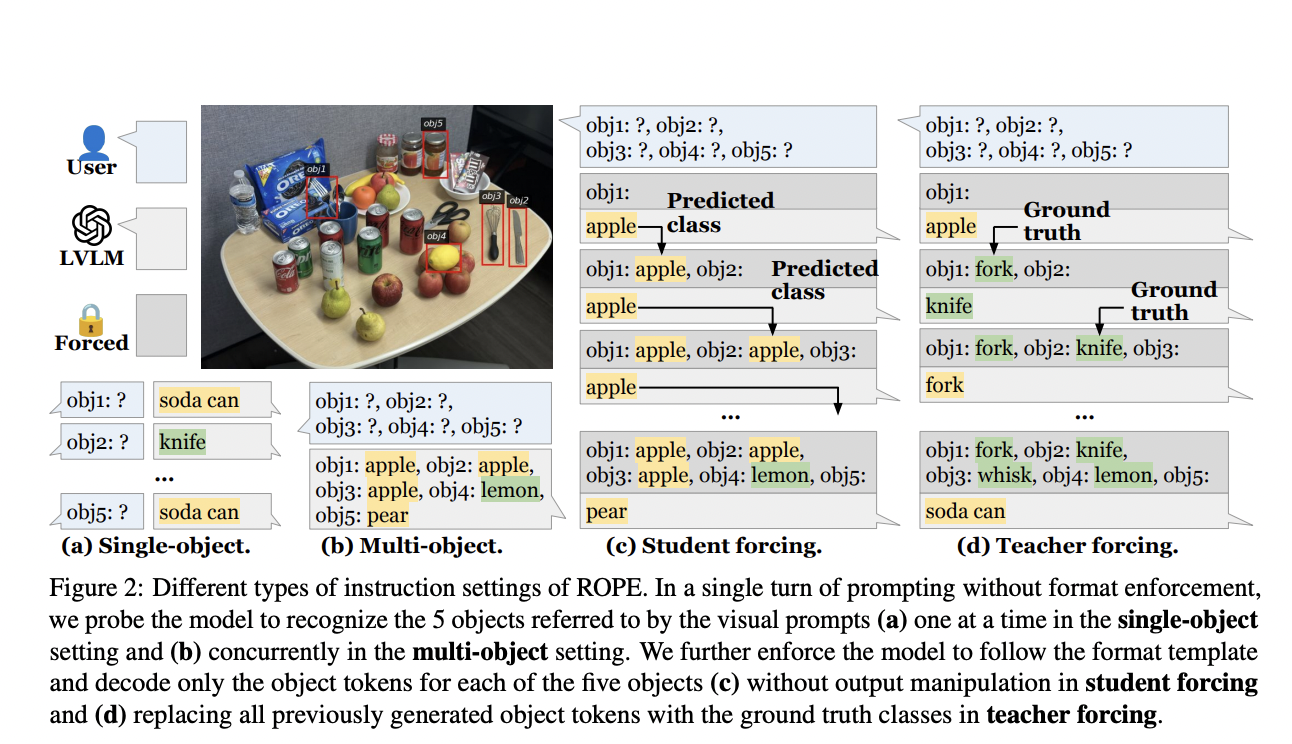
Галлюцинация объектов происходит, когда модели видео-языкового восприятия описывают объекты, которых нет на данном изображении. Это явление, впервые отмеченное в задачах описания изображений, особенно проблематично, когда модели должны распознавать несколько объектов одновременно. Исследование множественной галлюцинации объектов вводит протокол оценки объектов на основе распознавания (ROPE) — комплексную структуру, разработанную для оценки того, как модели обрабатывают сценарии с несколькими объектами. Оценка фокусируется на таких факторах, как распределение классов объектов на изображениях и влияние визуальных подсказок на производительность модели.
Протокол ROPE категоризирует тестовые сценарии на четыре подгруппы: «В естественной среде», «Однородные», «Разнородные» и «Антагонистические». Это классификация позволяет детально проанализировать поведение моделей в различных условиях. Исследование выявляет, что большие модели видео-языкового восприятия (LVLM) чаще галлюцинируют, когда фокусируются на нескольких объектах, чем на одиночных. В нем устанавливаются несколько ключевых факторов, влияющих на поведение галлюцинации, включая атрибуты данных, такие как яркость и частота объектов, и внутреннее поведение модели, такое как энтропия токенов и визуальный вклад.
Эмпирические результаты исследования показывают, что множественная галлюцинация объектов присутствует в различных LVLM, независимо от их масштаба или обучающих данных. Бенчмарк ROPE предоставляет надежный метод для оценки и количественной оценки этих галлюцинаций, подчеркивая необходимость более сбалансированных наборов данных и продвинутых протоколов обучения для устранения этой проблемы.
Культурная инклюзивность в моделях видео-языкового восприятия
Хотя техническая производительность моделей видео-языкового восприятия критична, их эффективность зависит от их способности учитывать различные культурные контексты. Второе исследование решает эту проблему, предлагая культурно-центричный бенчмарк оценки для VLM. Это исследование подчеркивает разрыв в текущих методах оценки, которые часто должны учитывать культурный контекст пользователей, особенно тех, кто имеет нарушения зрения.
Исследование включает создание опроса для сбора предпочтений от людей с нарушениями зрения относительно включения культурных деталей в подписи к изображению. На основе результатов опроса исследователи фильтруют набор данных VizWiz — коллекцию изображений, сделанных слепыми людьми — для выявления изображений с неявными культурными ссылками. Этот отфильтрованный набор данных служит в качестве бенчмарка для оценки культурной компетентности современных моделей VLM.
Несколько моделей, как открытые, так и закрытые, оцениваются с использованием этого бенчмарка. Результаты показывают, что, хотя закрытые модели, такие как GPT-4o и Gemini-1.5-Pro, показывают лучшие результаты в генерации культурно значимых подписей, все еще существует значительный разрыв в их способности полностью улавливать тонкости различных культур. Исследование также показывает, что автоматические метрики оценки, обычно используемые для оценки производительности модели, часто должны соответствовать человеческому суждению, особенно в культурно разнообразных средах.
Сравнительный анализ
Противопоставление результатов обоих исследований дает понимание проблем, с которыми сталкиваются модели видео-языкового восприятия в реальных приложениях. Проблема множественной галлюцинации объектов подчеркивает технические ограничения текущих моделей, в то время как акцент на культурной инклюзивности подчеркивает необходимость более ориентированных на человека рамок оценки.
Технические улучшения:
- Протокол ROPE: Внедрение автоматизированных протоколов оценки, учитывающих распределение классов объектов и визуальные подсказки.
- Разнообразие данных: Обеспечение сбалансированного распределения объектов и разнообразных аннотаций в обучающих наборах данных.
Культурные соображения:
- Опросы, ориентированные на пользователя: Включение обратной связи от людей с нарушениями зрения для определения предпочтений по подписям.
- Культурные аннотации: Дополнение наборов данных культурно-специфическими аннотациями для улучшения культурной компетентности VLM.
Заключение
Интеграция моделей видео-языкового восприятия в приложения для людей с нарушениями зрения обещает большие возможности. Однако решение технических и культурных проблем, выявленных в этих исследованиях, критически важно для реализации этого потенциала. Исследователи и разработчики могут создавать более надежные и удобные для пользователя VLM, приняв комплексные рамки оценки, такие как ROPE, и внедрив культурную инклюзивность в обучение и оценку моделей. Эти усилия улучшат точность этих моделей и обеспечат их лучшее соответствие разнообразным потребностям пользователей.
Проверьте Paper 1 и Paper 2. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашим сообществам в SubReddit, Telegram и LinkedIn.
Если вы заинтересованы в партнерстве (контент/реклама/рассылка), заполните эту форму.
Оригинальная публикация: Enhancing Vision-Language Models: Addressing Multi-Object Hallucination and Cultural Inclusivity for Improved Visual Assistance in Diverse Contexts.
«`


















