
«`html
Эффективное постоянное обучение для спайковых нейронных сетей с сжатием во временной области
Продвижения в области аппаратного и программного обеспечения позволили интегрировать искусственный интеллект в устройства Интернета вещей (IoT) с низким энергопотреблением, такие как ультранизкопотребляющие микроконтроллеры. Однако для развертывания сложных искусственных нейронных сетей (ANN) на этих устройствах требуются техники, такие как квантование и обрезка, чтобы соответствовать их ограничениям. Кроме того, модели edge AI могут столкнуться с ошибками из-за изменений в распределении данных между тренировочной и рабочей средой. Кроме того, многие приложения теперь требуют, чтобы алгоритмы ИИ адаптировались к индивидуальным пользователям, обеспечивая при этом конфиденциальность и уменьшая интернет-связь.
Непрерывное обучение
Непрерывное обучение (CL) — это способность постоянно учиться из новых ситуаций, не теряя при этом информацию, которая уже была обнаружена. Лучшие решения CL, известные как методы на основе повторения, снижают вероятность забывания, постоянно обучая обучающие данные и примеры из ранее приобретенных задач. Однако этот подход требует больше места для хранения на устройстве. Возможен компромисс в точности с подходами без повторения, которые зависят от конкретных настроек архитектуры сети или стратегии обучения, чтобы сделать модели устойчивыми к забыванию без хранения образцов на устройстве. Несколько моделей ANN, таких как CNN, требуют больших объемов хранения данных на устройстве для сложных обучающих данных, что может осложнить CL на краю, особенно подходы на основе повторения.
Спайковые нейронные сети
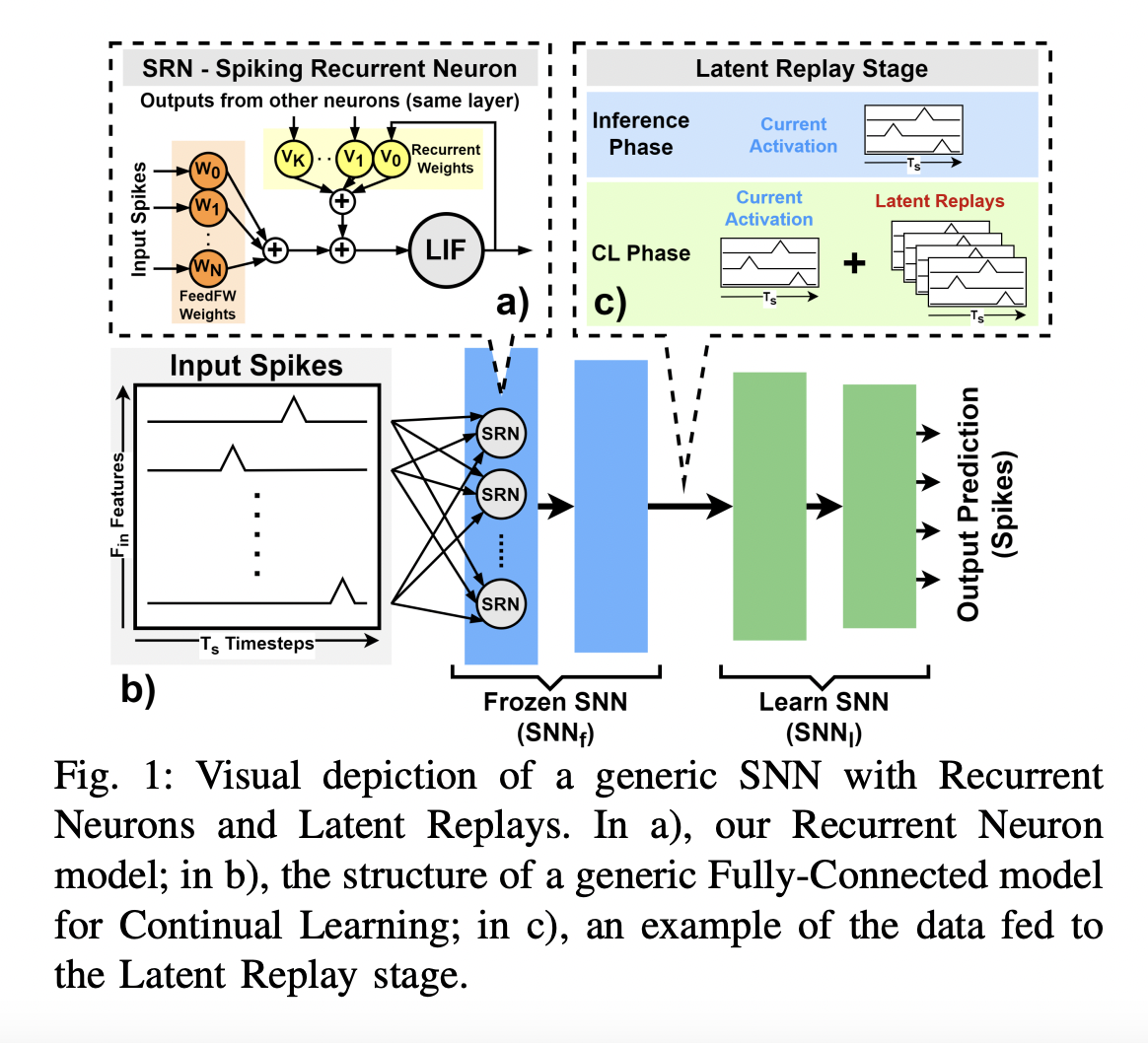
Спайковые нейронные сети (SNN) представляют собой потенциальный парадигму для энергоэффективной обработки временных рядов благодаря их высокой точности и эффективности. Обмениваясь информацией в виде спайков, которые представляют собой кратковременные, дискретные изменения потенциала мембраны нейрона, SNN имитируют активность органических нейронов. Эти спайки могут быть легко записаны в виде 1-битных данных в цифровых структурах, открывая возможности для создания решений CL. Использование онлайн-обучения в программном и аппаратном обеспечении SNN изучалось, но исследование методов CL в SNN с использованием подходов без повторения ограничено.
Новое исследование
Новое исследование команды Университета Болоньи, Политехнического университета Турина, ETH Цюриха представляет современную реализацию метода CL на основе повторения для SNN, который эффективен по памяти и разработан для безупречной работы с устройствами с ограниченными ресурсами. Исследователи используют метод на основе повторения, а именно скрытое повторение (LR), чтобы обеспечить CL на SNN. LR — это метод, который хранит подмножество прошлых опытов и использует их для обучения сети на новых задачах. Этот алгоритм доказал свою способность достигать современной точности классификации на CNN. Используя устойчивое кодирование информации SNN для снижения точности, они применяют потери сжатия по временной оси, что является новым способом уменьшения памяти повторения.
Подход команды не только надежен, но и впечатляюще эффективен. Они используют две популярные конфигурации CL, Sample-Incremental и Class-Incremental CL, чтобы протестировать свой подход. Они ориентируются на приложение распознавания ключевых слов с использованием рекуррентных SNN. Изучая десять новых классов из начального набора из 10 предварительно изученных, они тестируют предложенный подход в обширной процедуре многоклассового инкрементного CL, чтобы продемонстрировать его эффективность. На тестовом наборе данных Spiking Heidelberg Dataset (SHD) их подход достиг точности Top-1 92,46% в распределении Sample-Incremental, требуя 6,4 МБ данных LR. Это происходит при добавлении нового сценария, улучшая точность на 23,64%, сохраняя все ранее изученные. При изучении нового класса с точностью 92,50% в распределении Class-Incremental, метод достиг точности Top-1 92%, потребляя 3,2 МБ данных, с потерей до 3,5% на предыдущих классах. Комбинируя сжатие с выбором лучшего индекса LR, память, необходимая для данных повторения, была уменьшена в 140 раз, с потерей точности всего до 4% по сравнению с наивным методом. Кроме того, при изучении набора из 10 новых ключевых слов в настройке Multi-Class-Incremental, команда достигла точности 78,4% с использованием сжатых данных повторения. Эти результаты заложили основу нового метода CL на краю, который одновременно энергоэффективен и точен.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 46k+ ML SubReddit
Статья опубликована на сайте MarkTechPost.
«`



















