
Революция в рекуррентных нейронных сетях (RNN): как слои TTT-обучения во время тестирования превосходят трансформеры
Само-внимательные механизмы могут захватывать ассоциации по всей последовательности, благодаря чему отлично обрабатывают расширенные контексты. Однако они обладают высокой вычислительной стоимостью, в частности, квадратичной сложностью, что означает, что при увеличении длины последовательности увеличивается объем необходимого времени и памяти. Рекуррентные нейронные сети (RNN), напротив, имеют линейную сложность, что повышает их вычислительную эффективность. Однако из-за ограничений на их скрытое состояние, которое должно содержать всю информацию в фиксированном представлении, RNN хуже справляются с длинными последовательностями.
Практические решения и ценность
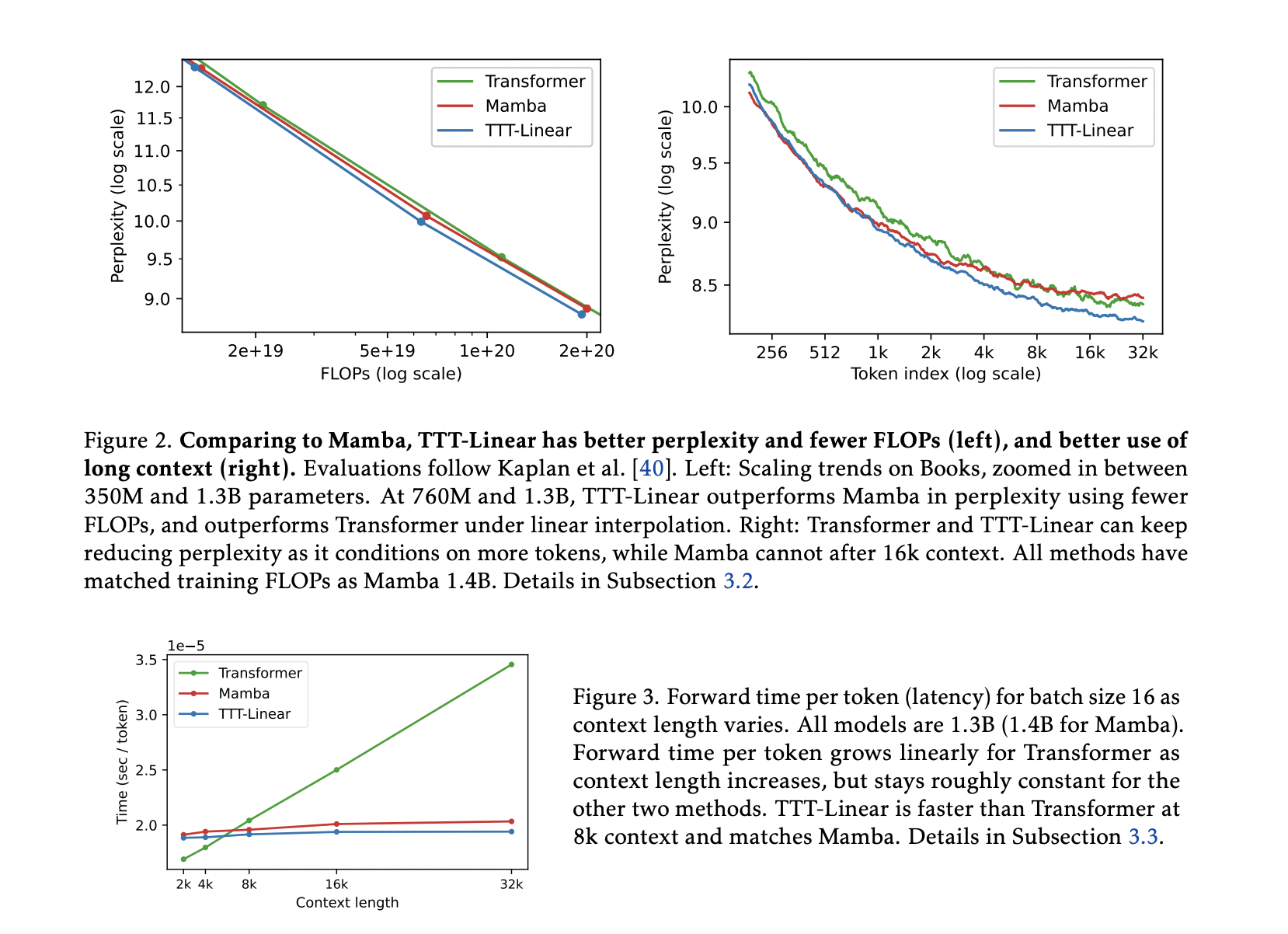
Для преодоления этих ограничений исследователи из Стэнфордского университета, Университета Калифорнии в Сан-Диего, Университета Калифорнии в Беркли и Meta AI предложили уникальный класс слоев моделирования последовательностей, который объединяет более выразительное скрытое состояние с линейной сложностью RNN. Основная идея заключается в использовании шага самообучения в качестве правила обновления и превращении скрытого состояния в модель машинного обучения. Это означает, что скрытое состояние обновляется путем эффективного обучения на входной последовательности, даже во время тестирования. Эти уровни называются слоями TTT (Test-Time Training).



















