
«`html
Преодоление Вызовов Масштабирования Моделей Трансформера с Помощью PEER
Проблема
В архитектуре трансформеров вычислительные затраты и объем активационной памяти линейно растут с увеличением ширины скрытого слоя слоев прямого распространения (FFW). Эта проблема масштабирования представляет существенное вызов, особенно по мере увеличения размеров и сложности моделей. Преодоление этого вызова является ключевым для продвижения исследований в области искусственного интеллекта, поскольку это непосредственно влияет на возможность развертывания масштабных моделей в реальных приложениях, таких как языковое моделирование и обработка естественного языка.
Решение
Новый подход под названием Parameter Efficient Expert Retrieval (PEER), предложенный исследователями из Google DeepMind, специально решает ограничения существующих моделей MoE. PEER использует технику product key для разреженного извлечения из огромного количества маленьких экспертов, превышающего миллион. Этот подход повышает детализацию моделей MoE, обеспечивая лучший баланс между производительностью и вычислительными затратами. Инновация заключается в использовании изученной структуры индекса для маршрутизации, обеспечивающей эффективное и масштабируемое извлечение экспертов. Этот метод отделяет вычислительные затраты от количества параметров, представляя значительное продвижение по сравнению с предыдущими архитектурами. PEER-слои демонстрируют существенные улучшения в эффективности и производительности для задач языкового моделирования.
Результаты
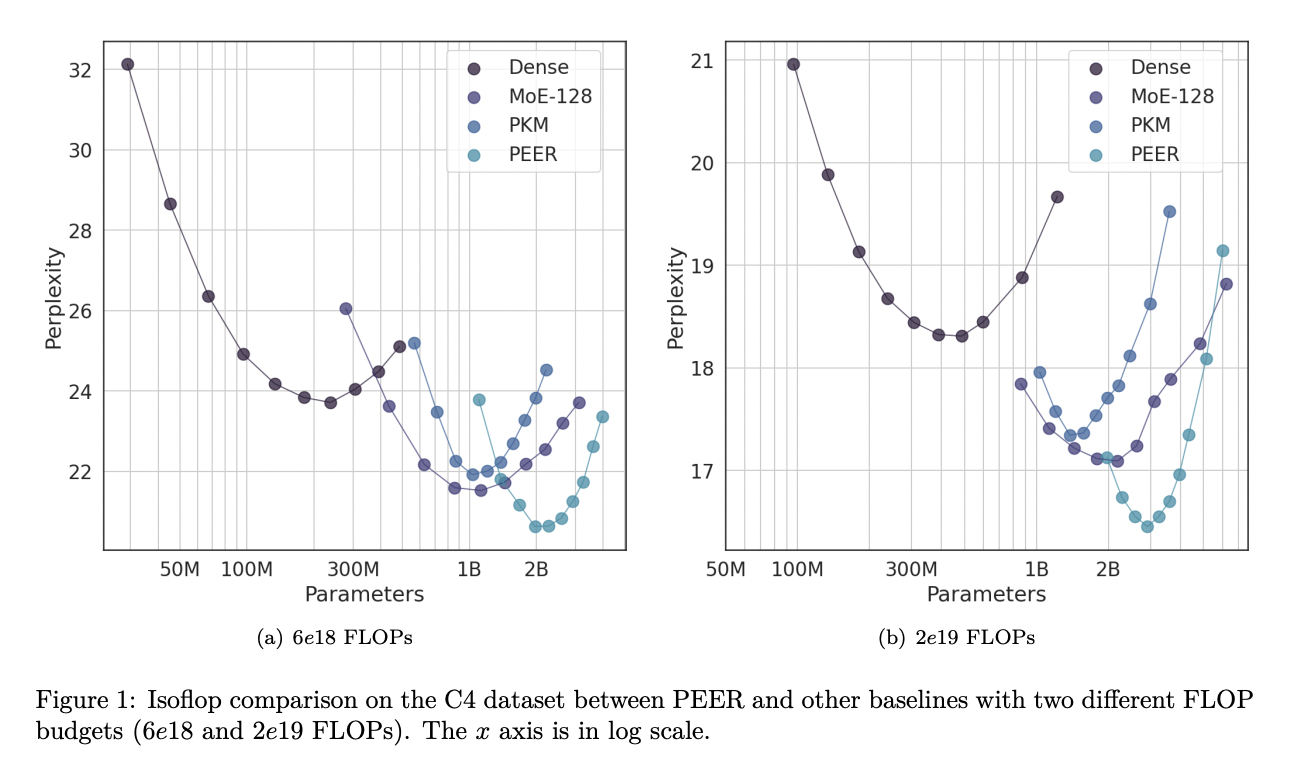
Эксперименты показывают, что PEER-слои значительно превосходят плотные FFW и грубозернистые MoE в плане баланса производительности и вычислительных затрат. Примененные к нескольким наборам данных для языкового моделирования, включая Curation Corpus, Lambada, Pile, Wikitext и C4, модели PEER достигли значительно более низких показателей непонятности. Например, при бюджете FLOP в 2е19 PEER-модели достигли показателя непонятности 16,34 на наборе данных C4, что ниже, чем 17,70 для плотных моделей и 16,88 для моделей MoE. Эти результаты подчеркивают эффективность и эффективность архитектуры PEER в улучшении масштабируемости и производительности моделей трансформера.
Заключение
Предложенный метод представляет собой значительный вклад в исследования в области искусственного интеллекта путем внедрения архитектуры PEER. Этот новый подход решает вычислительные вызовы, связанные с масштабированием моделей трансформера, используя огромное количество маленьких экспертов и эффективные техники маршрутизации. Превосходство модели PEER в балансе производительности и вычислительных затрат, продемонстрированное через обширные эксперименты, подчеркивает ее потенциал для продвижения исследований в области искусственного интеллекта путем создания более эффективных и мощных языковых моделей.
«`



















