
«`html
Vision-Language Models: Practical Solutions and Value
Эволюция моделей видео-языкового восприятия
Модели видео-языкового восприятия значительно развились за последние годы, исследователи DeepMind представили PaliGemma — открытую модель видео-языкового восприятия, объединяющую преимущества серии моделей PaLI с семейством языковых моделей Gemma. PaliGemma обладает впечатляющими возможностями обработки изображений и текста, превосходя предыдущие модели своими результатами.
Архитектура PaliGemma
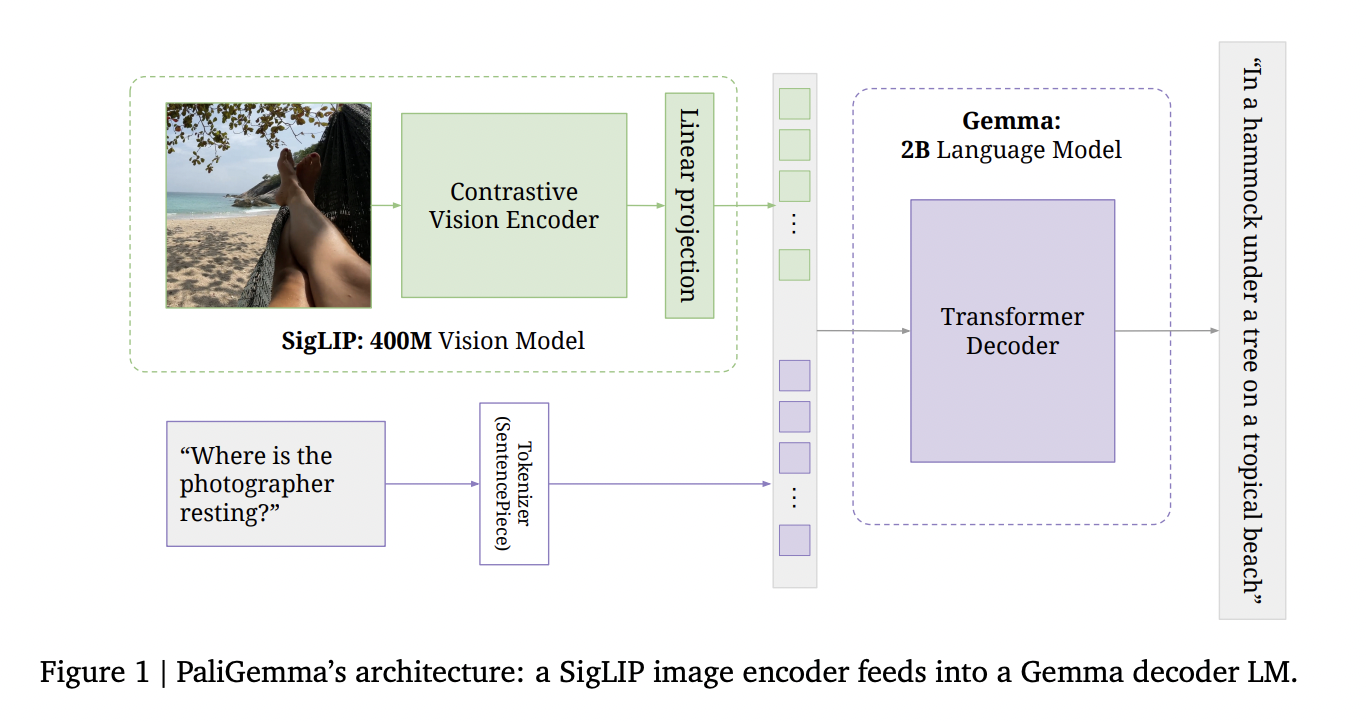
Архитектура PaliGemma включает в себя три ключевых компонента: энкодер изображений SigLIP ViTSo400m, декодерно-только языковую модель Gemma-2B v1.0 и линейный проекционный слой. Эта простая и эффективная конструкция позволяет PaliGemma успешно решать различные задачи, включая классификацию изображений, подписывание изображений и визуальное вопросно-ответное взаимодействие.
Обучение PaliGemma
Процесс обучения PaliGemma включает несколько этапов, начиная с предварительного обучения каждого компонента по отдельности, затем мультимодального обучения на разнообразных задачах, увеличения разрешения модели для обработки изображений высокого разрешения и, наконец, этапа трансфера для адаптации базовой модели к конкретным задачам или сценариям использования.
Результаты исследования PaliGemma
Результаты исследования демонстрируют впечатляющие возможности PaliGemma в решении широкого спектра задач видео-языкового восприятия, таких как подписывание изображений, визуальное вопросно-ответное взаимодействие, понимание графиков и OCR-задачи. Модель также успешно справляется с входными данными видео и задачами сегментации изображений.
Заключение и рекомендации
PaliGemma представляет собой мощную открытую модель видео-языкового восприятия, которая превосходит более крупные модели своими результатами. Предоставление базовой модели без инструкции настройки обучения способствует дальнейшему исследованию и разработке в области видео-языкового восприятия.
Для получения дополнительной информации ознакомьтесь с документом. Все права защищены и принадлежат исследователям.
Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram.
«`



















