
«`html
Большие языковые модели (LLM) в области искусственного интеллекта (ИИ)
Большие языковые модели (LLM) продемонстрировали впечатляющую профессиональность в задачах генерации языка. Однако их процесс обучения, который включает обучение без учителя на обширных наборах данных, а затем контролируемую настройку, представляет существенные вызовы. Основная проблема заключается в природе наборов данных для предварительного обучения, таких как Common Crawl, которые часто содержат нежелательный контент. В результате LLM непреднамеренно приобретают способность генерировать оскорбительный язык и потенциально вредные советы. Эта непреднамеренная способность представляет серьезный риск безопасности, поскольку эти модели могут производить связные ответы на входные данные пользователей без должной фильтрации контента. Задача исследователей заключается в разработке методов сохранения возможностей генерации языка LLM, одновременно эффективно уменьшая производство небезопасного или неэтичного контента.
Решения для безопасности в LLM
Существующие попытки преодолеть проблемы безопасности в LLM в основном сосредоточены на двух подходах: безопасной настройке и внедрении барьеров. Безопасная настройка направлена на оптимизацию моделей для реагирования таким образом, чтобы соответствовать человеческим ценностям и безопасности. Однако эти модели чата остаются уязвимыми для атак jailbreak, которые используют различные стратегии для обхода мер безопасности. Для противодействия этим уязвимостям исследователи разработали барьеры для мониторинга обмена данными между моделями чата и пользователями.
Инновационное решение LoRA-Guard
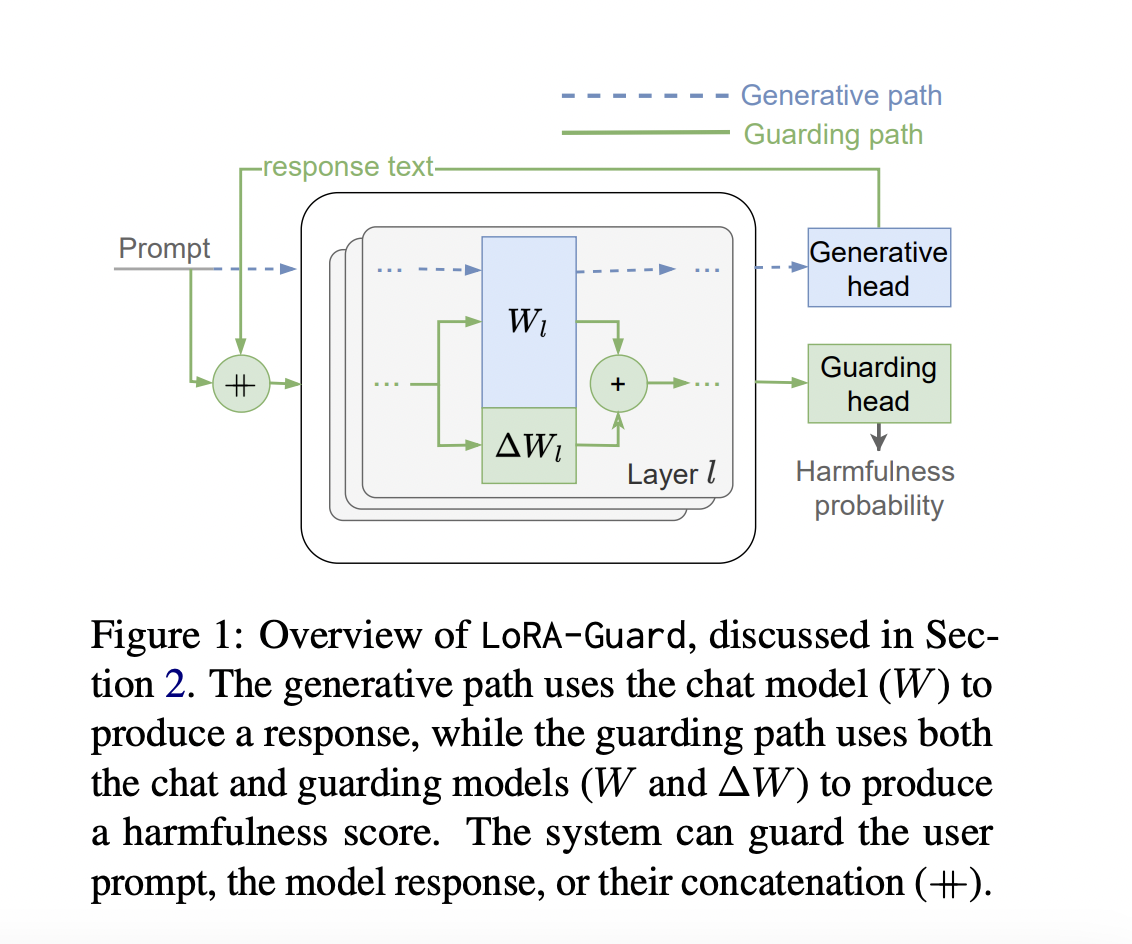
Исследователи Samsung R&D Institute представляют LoRA-Guard, инновационную систему, которая интегрирует модели чата и барьеры, решая проблемы безопасности в LLM. Она использует низкоранговый адаптер на основе трансформатора модели чата для обнаружения вредного контента. Система работает в двойных режимах: активация параметров LoRA для обеспечения безопасности с помощью классификационной головы и их деактивация для нормальной работы чата. Этот подход значительно снижает нагрузку параметров на 100-1000 раз по сравнению с предыдущими методами, делая развертывание возможным в условиях ограниченных ресурсов.
Архитектура LoRA-Guard разработана для эффективной интеграции возможностей обеспечения безопасности в модель чата. Она использует те же вложения и токенизаторы как для модели чата C, так и для барьерной модели G. Основное новшество заключается в карте объектов: в то время как C использует исходную карту объектов f, G использует f’ с прикрепленными к ней адаптерами LoRA. G также использует отдельную выходную голову hguard для классификации в категории вредности.
LoRA-Guard обучается путем контролируемой настройки f’ и hguard на размеченных наборах данных, при этом параметры модели чата остаются замороженными. Этот подход использует существующие знания модели чата при обучении эффективному обнаружению вредного контента.
LoRA-Guard демонстрирует исключительную производительность на нескольких наборах данных. На ToxicChat он превосходит базовые показатели AUPRC, используя значительно меньше параметров – до 1500 раз меньше, чем полностью настроенные модели. Для OpenAIModEval он соответствует альтернативным методам с 100 раз меньшим количеством параметров. Кросс-доменные оценки показывают интересные асимметрии: модели, обученные на ToxicChat, хорошо обобщаются на OpenAIModEval, но обратное показывает значительное падение производительности. В целом LoRA-Guard является эффективным и эффективным решением для модерации контента в языковых моделях.
LoRA-Guard представляет собой значительный прорыв в модерированных разговорных системах, снижая нагрузку параметров для обеспечения безопасности на 100-1000 раз, сохраняя или улучшая производительность. Эта эффективность достигается за счет обмена знаниями и механизмов обучения, эффективных по параметрам. Его двойной дизайн позволяет предотвращать катастрофическое забывание во время настройки, что является распространенной проблемой в других подходах. Путем значительного сокращения времени обучения, времени вывода и требований к памяти LoRA-Guard становится критическим развитием для внедрения надежной модерации контента в условиях ограниченных ресурсов.
Проверьте статью. Весь кредит за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему подпроекту по машинному обучению на Reddit.