
«`html
Большие языковые модели (LLM) в решении задач планирования
Проблемы с применением LLM в планировании
Большие языковые модели (LLM) привлекли значительное внимание при решении задач планирования, однако текущие методологии требуют пересмотра. Прямое создание планов с использованием LLM показало ограниченный успех, причем GPT-4 достиг лишь 35% точности на простых задачах планирования. Это низкая точность подчеркивает необходимость более эффективных подходов. Еще одной значительной проблемой является отсутствие строгих методик и бенчмарков для оценки перевода естественно-языковых описаний планирования в структурированные языки планирования, такие как Planning Domain Definition Language (PDDL).
Решения для преодоления вызовов с использованием LLM в планировании
Исследователи изучили различные подходы к преодолению вызовов при использовании LLM для планирования. Один метод включает использование LLM для прямого создания планов, но он показал ограниченный успех из-за низкой производительности даже на простых задачах планирования. Другой подход, «Planner-Augmented LLMs», сочетает LLM с классическими методиками планирования. Этот метод формулирует задачу как задачу машинного перевода, преобразуя естественно-языковые описания планировочных задач в структурированные форматы, такие как PDDL, конечные автоматы или логическое программирование.
Гибридный подход перевода естественного языка в PDDL
Гибридный подход перевода естественного языка в PDDL использует преимущества как LLM, так и традиционных символьных планировщиков. LLM интерпретируют естественный язык, в то время как эффективные традиционные планировщики обеспечивают корректность решения. Однако оценка задач генерации кода, включая перевод PDDL, остается сложной. Существующие методики оценки, такие как метрики на основе сопоставления и валидаторы планов, требуют пересмотра при оценке точности и актуальности сгенерированного PDDL по сравнению с исходными инструкциями.
Введение бенчмарка Planetarium
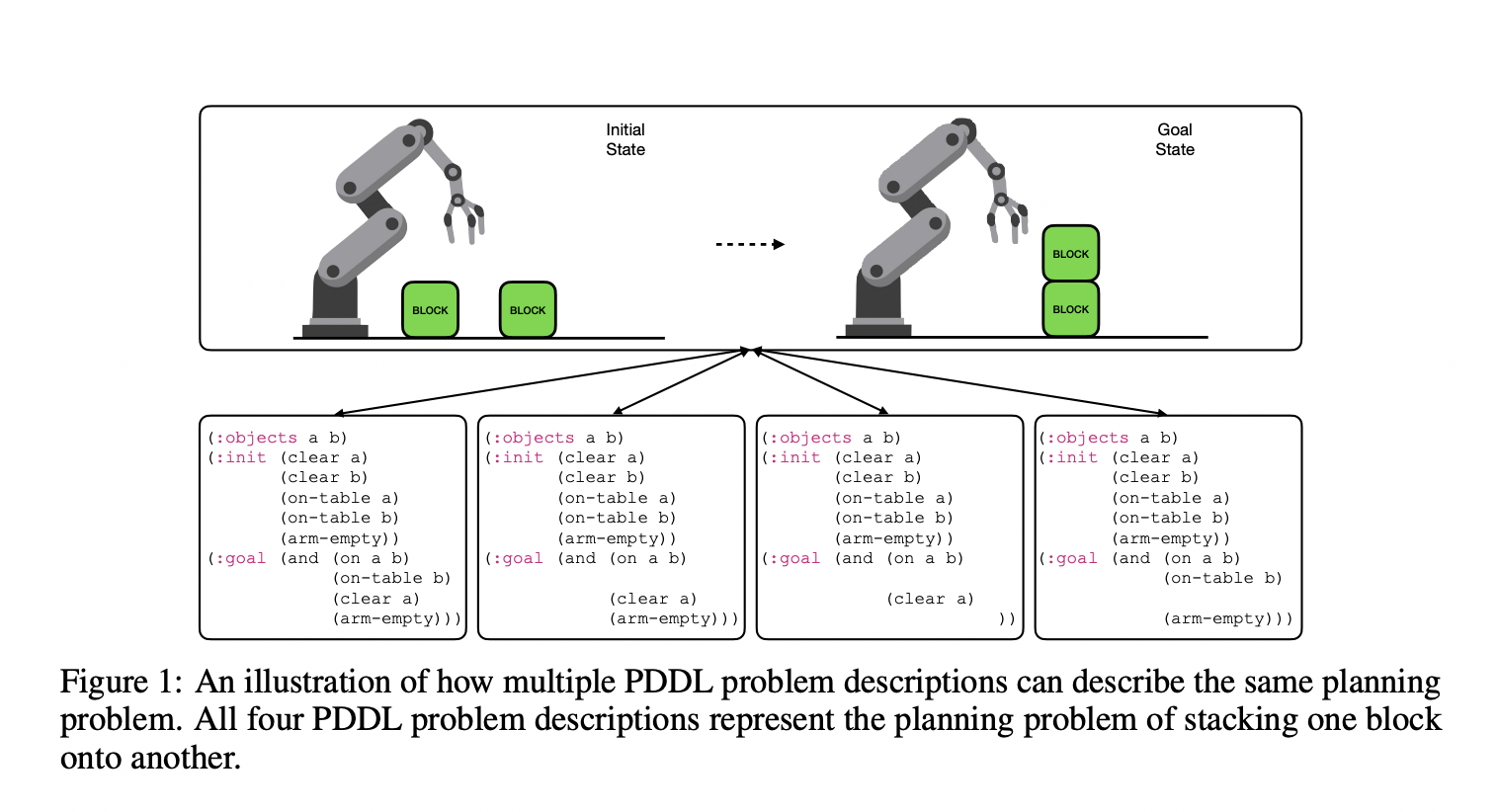
Исследователи из Департамента компьютерных наук Университета Брауна представляют Planetarium, строгий бенчмарк для оценки способности LLM переводить естественно-языковые описания планировочных задач в PDDL, решая вызовы в оценке точности генерации PDDL. Этот бенчмарк предлагает строгий подход к оценке эквивалентности PDDL, формально определяя эквивалентность планировочной задачи и предоставляя алгоритм для проверки того, удовлетворяют ли две PDDL-задачи этому определению. Planetarium включает обширный набор данных, включающий 132,037 истинных PDDL-задач с соответствующими текстовыми описаниями, изменяющимися по абстракции и размеру. Бенчмарк также предоставляет широкую оценку текущих LLM как в нулевом режиме, так и после настройки, выявляя сложность задачи. С GPT-4, достигшим лишь 35.1% точности в нулевом режиме, Planetarium служит ценным инструментом для измерения прогресса в генерации PDDL на основе LLM и общедоступен для будущего развития и оценки.
Алгоритм оценки эквивалентности PDDL
Бенчмарк Planetarium вводит строгий алгоритм для оценки эквивалентности PDDL, решая проблему сравнения различных представлений одной и той же планировочной задачи. Этот алгоритм преобразует код PDDL в графы сцен, представляющие начальное и целевое состояния. Затем он полностью специфицирует целевые сцены, добавляя все тривиально истинные связи, и создает графы задач, объединяя начальные и целевые графы сцен.
Оценка производительности LLM в переводе в PDDL
Результаты показывают, что GPT-4o, Mistral v0.3 7B Instruct и Gemma 1.1 IT 2B & 7B показали плохую производительность в нулевом режиме, причем GPT-4o достиг наивысшей точности на уровне 35.12%. Статья также подчеркивает, что тонкая настройка значительно улучшила производительность для всех моделей. Mistral v0.3 7B Instruct достиг наивысшей точности после тонкой настройки.
Заключение
Данное исследование представляет бенчмарк Planetarium, который является значительным шагом в оценке способности LLM переводить естественный язык в PDDL для задач планирования. Оно решает ключевые технические и общественные вызовы, подчеркивая важность точных переводов для предотвращения потенциального вреда от несоответствующих результатов. Нынешний уровень производительности, даже для продвинутых моделей, подчеркивает сложность этой задачи и необходимость дальнейших инноваций. При развитии планировочных систем на основе LLM, Planetarium предоставляет важную основу для измерения прогресса и обеспечения надежности. Это исследование расширяет возможности ИИ и подчеркивает важность ответственного развития надежных систем планирования на основе ИИ.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab здесь. Будущее уже здесь!