
«`html
Оценка качества разговорных ассистентов AI
Оценка разговорных ассистентов AI, таких как GitHub Copilot Chat, является сложной из-за их зависимости от языковых моделей и интерфейсов на основе чата. Существующие метрики качества разговора требуют пересмотра для доменно-специфических диалогов, что затрудняет оценку эффективности этих инструментов разработки программного обеспечения.
Техника RUBICON от Microsoft для оценки доменно-специфических разговоров Human-AI
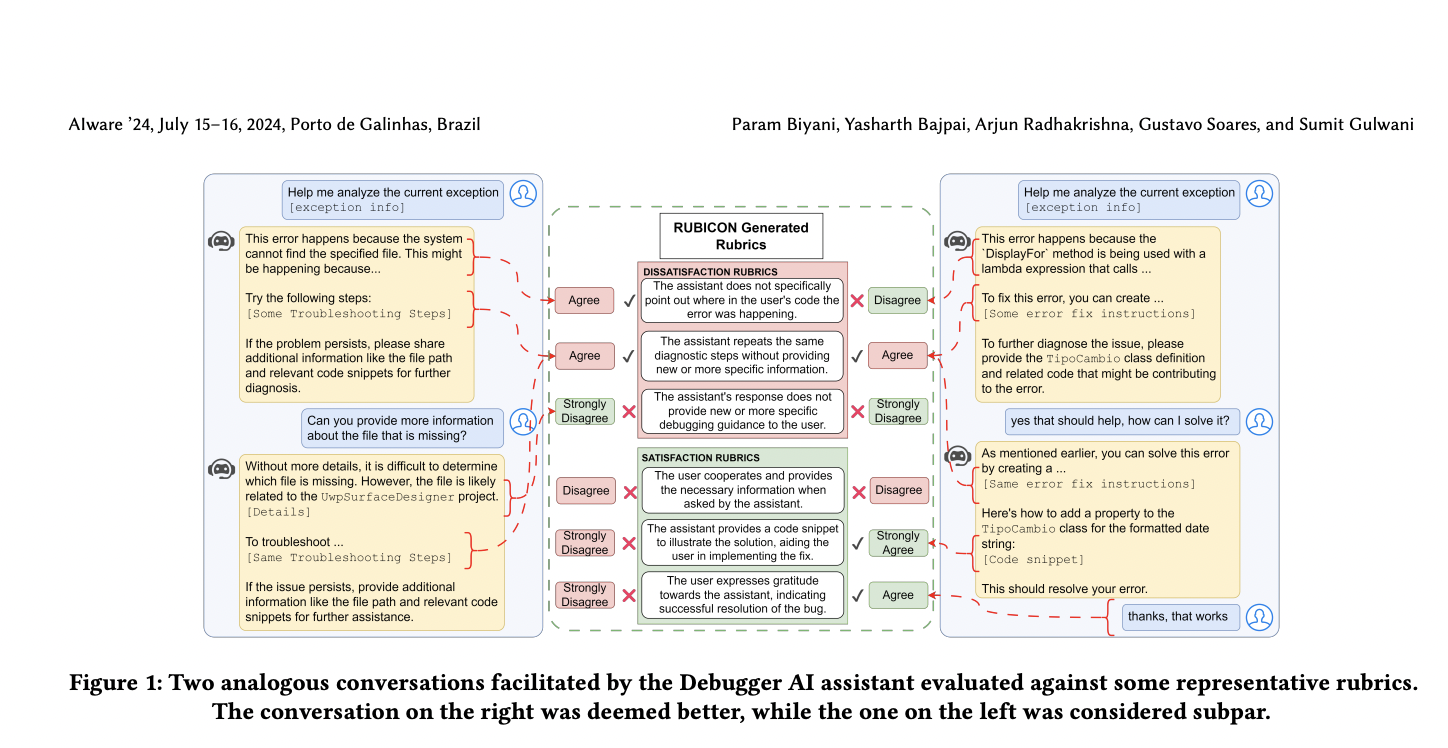
Исследователи из Microsoft представляют RUBICON — технику для оценки доменно-специфических разговоров Human-AI с использованием больших языковых моделей. RUBICON генерирует кандидатов для оценки качества разговора и выбирает лучшие из них. Он улучшает метод SPUR, интегрируя доменно-специфические сигналы и максимы Грайса, создавая пул оцениваемых рубрик. RUBICON был протестирован на 100 разговорах между разработчиками и ассистентом на основе чата для отладки C#, используя GPT-4 для генерации и оценки рубрик. Он превзошел альтернативные наборы рубрик, достигнув высокой точности в предсказании качества разговора и продемонстрировав эффективность своих компонентов через исследования абляции.
Оценка RUBICON
RUBICON оценивает качество разговора для доменно-специфических ассистентов, изучая рубрики для удовлетворения (SAT) и неудовлетворения (DSAT) из размеченных разговоров. Он включает три этапа: генерацию разнообразных рубрик, выбор оптимизированного набора рубрик и оценку разговоров. Рубрики — это утверждения естественного языка, захватывающие атрибуты разговора. Разговоры оцениваются с использованием 5-балльной шкалы Ликерта, нормализованной до диапазона [0, 10]. Генерация рубрик включает надзорное извлечение и суммирование, а выбор оптимизирует рубрики для точности и охвата. Потери корректности и резкости направляют выбор оптимального подмножества рубрик, обеспечивая эффективную и точную оценку качества разговора.
Оценка и выводы
Оценка RUBICON включает три ключевых вопроса: его эффективность по сравнению с другими методами, влияние доменной сенсибилизации (DS) и принципов дизайна разговора (CDP), а также производительность его политики выбора. Результаты показали, что RUBICON превосходит базовые варианты в разделении положительных и отрицательных разговоров и классификации разговоров с высокой точностью, подчеркивая важность инструкций DS и CDP.
Подробности исследования можно найти в оригинальной статье. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
Если вам нужны советы по внедрению ИИ, пишите нам на itinai. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















