
«`html
Понимание документов
Понимание документов (DU) сосредотачивается на автоматической интерпретации и обработке документов, охватывающих сложные структуры макета и мультимодальные элементы, такие как текст, таблицы, диаграммы и изображения. Эта задача является важной для извлечения и использования огромного объема информации, содержащейся в годовых документах.
Текущие методы и вызовы
Одним из критических вызовов является понимание длинных документов, охватывающих множество страниц и требующих понимания различных модальностей и страниц. Традиционные модели DU для одной страницы испытывают затруднения с этим, что делает важным разработку бенчмарков для оценки производительности моделей на длинных документах.
Практические решения и ценность
Методы DU включают в себя большие модели видео-языка (LVLM), такие как GPT-4o, Gemini-1.5 и Claude-3, разработанные компаниями OpenAI и Anthropic. Эти модели показали перспективы в задачах на одной странице, но требуют помощи в понимании длинных документов из-за необходимости мультимодального понимания и интеграции мультимодальных элементов. Этот разрыв в возможностях подчеркивает важность создания комплексных бенчмарков для продвижения разработки более продвинутых моделей.
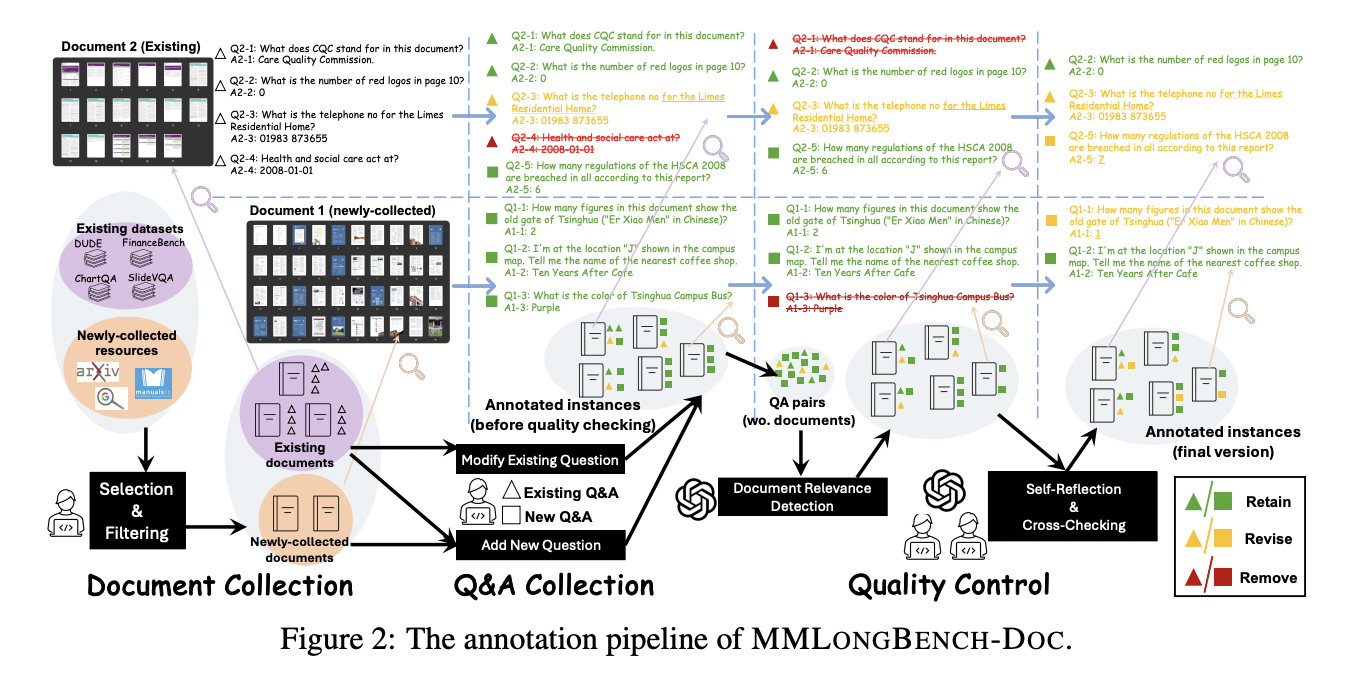
Исследователи из учреждений, включая Университет Наньян, Шанхайскую лабораторию искусственного интеллекта и Пекинский университет, представили MMLongBench-Doc, комплексный бенчмарк, разработанный для оценки возможностей моделей LVLM в длинном контексте DU. Этот бенчмарк включает 135 документов в формате PDF из различных областей, со средним количеством страниц 47,5 и 21 214,1 текстовых токенов. Он содержит 1 091 вопрос, требующий доказательств из текста, изображений, диаграмм, таблиц и структур макета, причем значительная часть требует мультимодального понимания. Этот строгий бенчмарк направлен на расширение возможностей текущих моделей DU.
В заключение, это исследование подчеркивает сложность понимания документов в длинном контексте и необходимость создания более эффективных моделей для обработки и понимания длинных мультимодальных документов. Бенчмарк MMLongBench-Doc, разработанный в сотрудничестве с ведущими исследовательскими учреждениями, является ценным инструментом для оценки и улучшения производительности этих моделей.
Ссылки и контакты
Подробнее о работе исследователей можно узнать в статье. Следите за нашими новостями в Twitter и присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn. Если вам интересна наша работа, вам понравится наш рассылка. Присоединяйтесь также к нашему Reddit-сообществу.
Практические рекомендации
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале или в Twitter. Попробуйте AI Sales Bot, помощник в продажах, который помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















