
«`html
LLM Efficiency Enhancement through Q-Sparse
Преимущества применения Q-Sparse в искусственном интеллекте
Исследования показывают, что Q-Sparse позволяет достичь базовой производительности LLM с более низкими затратами на вывод, устанавливает оптимальный закон масштабирования для разреженно-активированных LLM и демонстрирует эффективность в различных настройках обучения.
Q-Sparse работает с полными и квантованными моделями, включая 1-битные модели, предлагая путь к более эффективным, экономичным и энергосберегающим LLM.
Эффективность Q-Sparse подтверждена в различных сценариях обучения, включая обучение с нуля, продолжение обучения и донастройку, поддерживая эффективность и производительность в различных настройках.
Практическое применение Q-Sparse
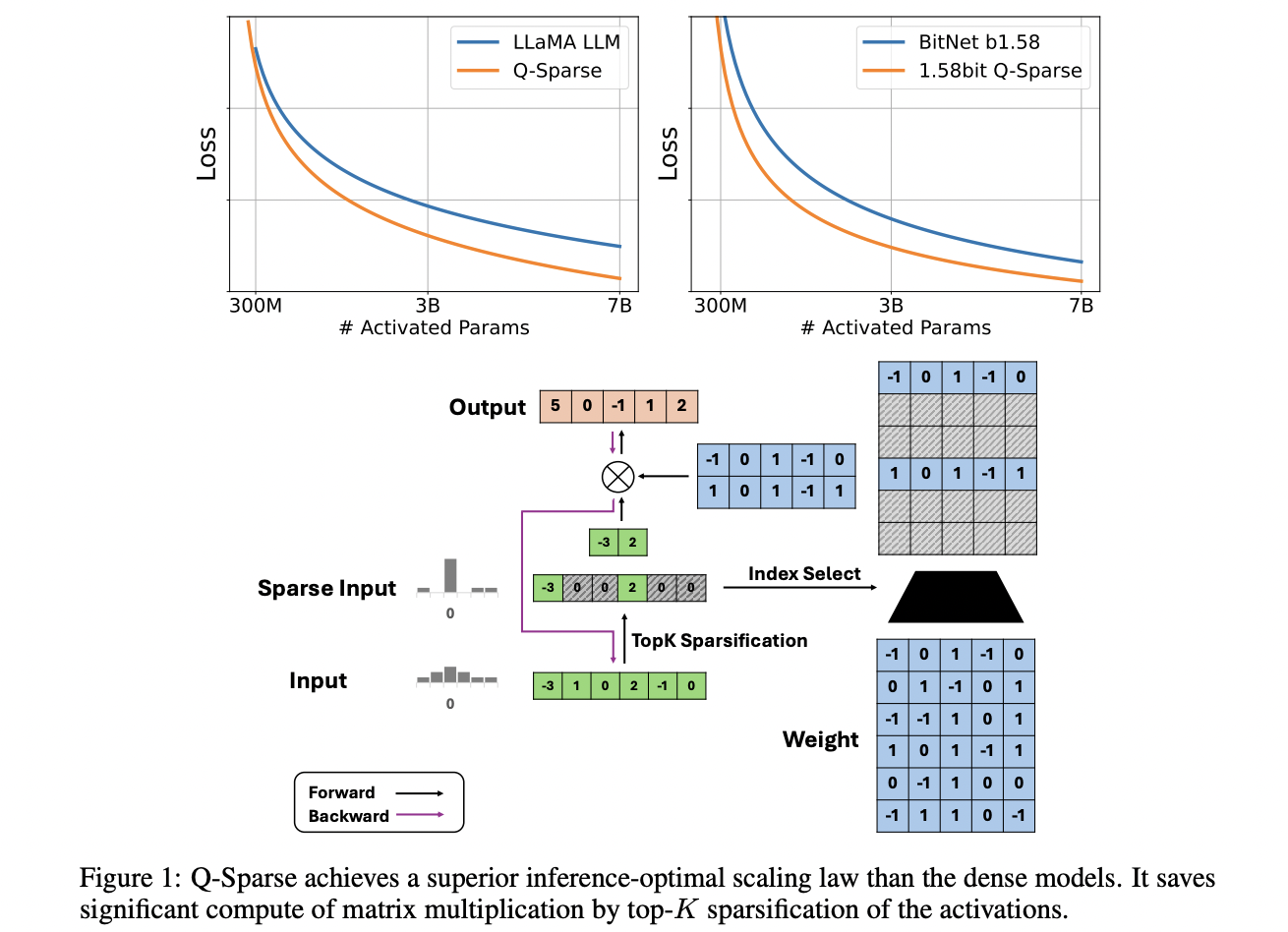
Q-Sparse улучшает архитектуру Transformer, позволяя полную разреженность в активациях через технику top-K разреженности и прямую оценку (STE). Этот подход применяется к активациям во время умножения матриц, снижая вычислительные затраты и объем памяти.
Q-Sparse эффективен для обучения с нуля, продолжения обучения и донастройки, поддерживая эффективность и производительность в различных настройках.
Исследования показывают, что производительность разреженно-активированных LLM также подчиняется закону степени с размером модели и экспоненциальному закону соотношения разреженности.
Эффективность Q-Sparse в различных сценариях обучения
Оценка Q-Sparse LLM в различных настройках, включая обучение с нуля, продолжение обучения и донастройку, показала, что Q-Sparse модели сопоставимы или превосходят производительность плотных моделей, доказывая эффективность и эффективность Q-Sparse в различных сценариях обучения.
Комбинация BitNet b1.58 с Q-Sparse предлагает значительные выгоды в эффективности, особенно в выводе.
Планы на будущее
Исследователи планируют масштабировать обучение с более крупными моделями и токенами и интегрировать YOCO для оптимизации управления кэшем KV. Q-Sparse будет адаптирован для пакетной обработки, чтобы улучшить его практичность.
Q-Sparse дополняет MoE и будет адаптирован для пакетной обработки, чтобы улучшить его практичность.
Подробнее о статье можно узнать здесь.
Все права на это исследование принадлежат его авторам. Также не забудьте следить за нами в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.