
«`html
Оценка больших языковых моделей с помощью FLAMe
Оценка больших языковых моделей (LLM) становится все более сложной из-за их сложности и универсальности. Обеспечение надежности и качества выходных данных этих моделей критически важно для развития технологий и приложений искусственного интеллекта. Исследователи нуждаются в помощи в разработке надежных методов оценки для оценки точности и беспристрастности выходных данных LLM, учитывая субъективный, несогласованный и дорогостоящий характер человеческих оценок.
Проблемы существующих методов оценки
Текущие метрики оценки, такие как BLEU и ROUGE, в основном фокусируются на лексических перекрытиях и не улавливают тонкое качество выходных данных LLM. Хотя недавние методы использовали предварительно обученные модели для измерения распределительной схожести и вероятностей токенов, эти подходы все еще требуют доработки в обобщаемости и последовательности. Высокая стоимость и время, необходимые для человеческих оценок, дополнительно усложняют процесс, делая его непрактичным для оценок в масштабе.
FLAMe: решение для оценки LLM
Исследовательская группа из Google DeepMind, Google и UMass Amherst представила FLAMe, семейство моделей Foundational Large Autorater, разработанных для улучшения оценки LLM. FLAMe использует большую и разнообразную коллекцию задач оценки качества, полученных из человеческих оценок, для обучения и стандартизации авторейтеров. FLAMe обучается с использованием надзорного многозадачного донастройки на более чем 100 задачах оценки качества, охватывающих более 5 миллионов человеческих оценок. Этот подход позволяет FLAMe обобщаться на новые задачи, превосходя существующие модели, такие как GPT-4 и Claude-3.
Обучение FLAMe включает тщательный процесс сбора и стандартизации данных. Исследовательская группа составила коллекцию человеческих оценок из предыдущих исследований, фокусируясь на задачах, таких как качество машинного перевода и инструкции для искусственного интеллекта. Этот обширный набор данных был затем преобразован в единый формат текст-к-текст, где каждая задача оценки качества была преобразована в пары вход-выход. Входы содержат контексты, специфичные для задачи, а выходы содержат ожидаемые человеческие оценки. Благодаря обучению на этом большом и разнообразном наборе данных, FLAMe изучает устойчивые закономерности человеческого суждения, минимизируя влияние шумных или низкокачественных данных. Вариант FLAMe-RM, специально донастроенный для оценки моделирования вознаграждения, иллюстрирует эффективность этой методологии. Даже при донастройке всего на 50 шагов на смеси четырех наборов данных, охватывающих чат, рассуждение и безопасность, FLAMe-RM продемонстрировал значительное улучшение производительности.
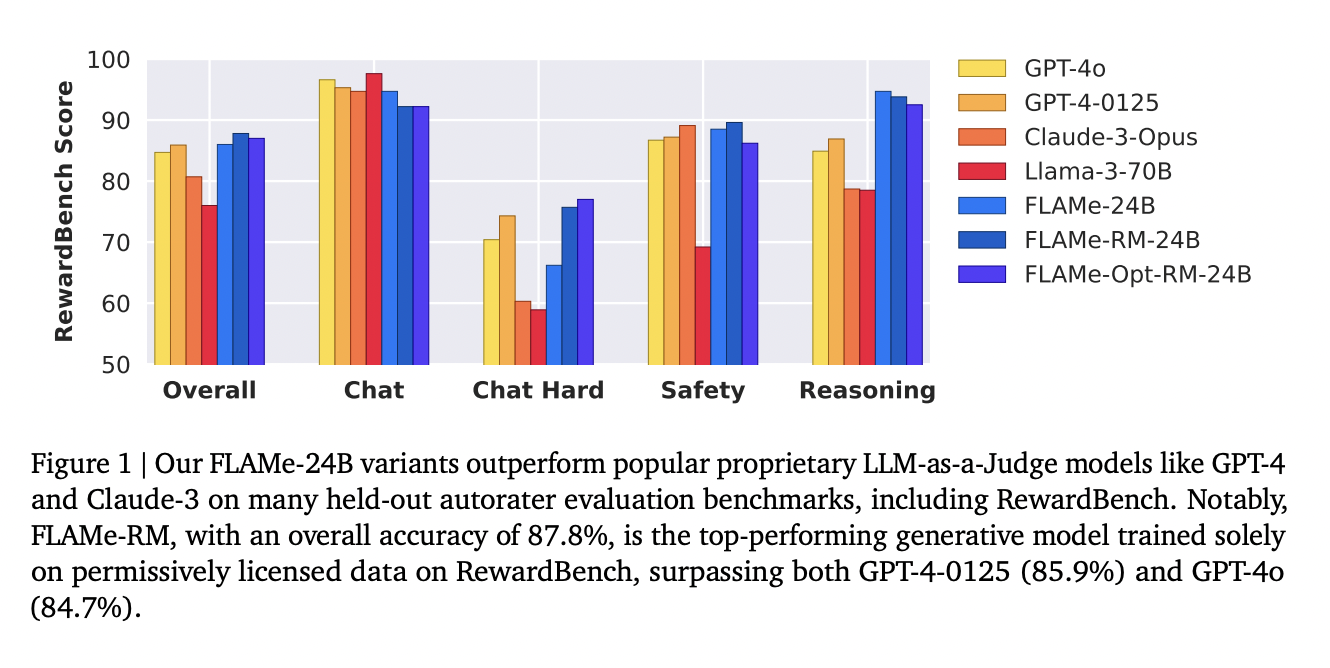
Производительность FLAMe заметна на различных бенчмарках. Модель FLAMe-RM-24B, вариант, донастроенный для оценки моделирования вознаграждения, достигла точности 87,8% на бенчмарке RewardBench, превзойдя как GPT-4-0125 (85,9%), так и GPT-4o (84,7%). На бенчмарке CoBBLEr bias, FLAMe проявляет значительно меньший уровень предвзятости по сравнению с другими моделями авторейтеров. Помимо RewardBench, производительность FLAMe впечатляет на других бенчмарках. Модели FLAMe превосходят существующие LLM в 8 из 12 автоматизированных бенчмарков оценки качества, охватывающих 53 задачи оценки качества. Это включает задачи, такие как сравнение резюме, оценка полезности и фактическая точность. Результаты демонстрируют широкие возможности и надежную производительность FLAMe в различных сценариях оценки.
FLAMe-Opt-RM, вычислительно эффективный вариант, оптимизирует многозадачную смесь для оценки моделирования вознаграждения с использованием новой стратегии донастройки хвостового патча. Этот метод донастраивает начальную точку PaLM-2-24B, настроенную на инструкцию, на оптимизированной смеси в течение 5000 шагов, достигая конкурентоспособной производительности на бенчмарке RewardBench с примерно в 25 раз меньшим количеством обучающих точек данных. Исследование подчеркивает, что более длительное обучение и дополнительная донастройка могут улучшить производительность, что свидетельствует о том, что FLAMe-Opt-RM является универсальной и эффективной моделью.
В заключение, исследование подчеркивает важность надежных и эффективных методов оценки для LLM. FLAMe предлагает надежное решение, используя стандартизированные человеческие оценки, демонстрируя значительное улучшение производительности и снижение предвзятости. Этот прогресс призван улучшить разработку и внедрение технологий искусственного интеллекта. Семейство моделей FLAMe, разработанное коллективной командой из Google DeepMind, Google и UMass Amherst, представляет собой значительный шаг вперед в оценке больших языковых моделей, обеспечивая надежные, беспристрастные и высококачественные выходные данные.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
The post This AI Paper from Google AI Introduces FLAMe: A Foundational Large Autorater Model for Reliable and Efficient LLM Evaluation appeared first on MarkTechPost.
«`




















