
«`html
Language models (LMs) and the Challenges of Machine Unlearning
Модели языка (LM) сталкиваются с серьезными проблемами, связанными с конфиденциальностью и авторскими правами из-за их обучения на огромных объемах текстовых данных. Непреднамеренное включение частных и охраняемых авторскими правами материалов в обучающие наборы данных привело к юридическим и этическим проблемам, включая судебные иски по авторским правам и требования соответствия регулятивным актам, таким как GDPR. Владельцы данных все чаще требуют удаления своих данных из обученных моделей, подчеркивая необходимость эффективных методов машинного забывания. Эти события стимулировали исследования методов, которые могут преобразовать существующие обученные модели так, чтобы они вели себя так, будто им никогда не демонстрировались определенные данные, сохраняя при этом общую производительность и эффективность.
Проблемы машинного забывания в моделях языка
Исследователи предприняли различные попытки решить проблемы машинного забывания в моделях языка. Точные методы машинного забывания, которые стремятся сделать забытую модель идентичной модели, обученной без забытых данных, были разработаны для простых моделей, таких как SVM и наивные байесовские классификаторы. Однако эти подходы вычислительно невозможны для современных больших моделей языка.
Оптимизационные методы приблизительного забывания возникли как более практичные альтернативы. Они включают в себя методы оптимизации параметров, такие как градиентное восхождение, информационно-ориентированное забывание, направленное на определенные модельные блоки, и забывание с учетом контекста, изменяющее выводы модели с использованием внешних знаний. Исследователи также исследовали применение забывания к конкретным вспомогательным задачам и для устранения вредных поведенческих моделей языка.
Методы оценки машинного забывания в моделях языка в основном сосредоточены на конкретных задачах, таких как вопросно-ответные системы или завершение предложений. Метрики, такие как оценки знакомства и сравнения с переобученными моделями, использовались для оценки эффективности забывания. Однако существующие оценки часто лишены комплексности и неадекватно учитывают реальные аспекты развертывания, такие как масштабируемость и последовательные запросы на забывание.
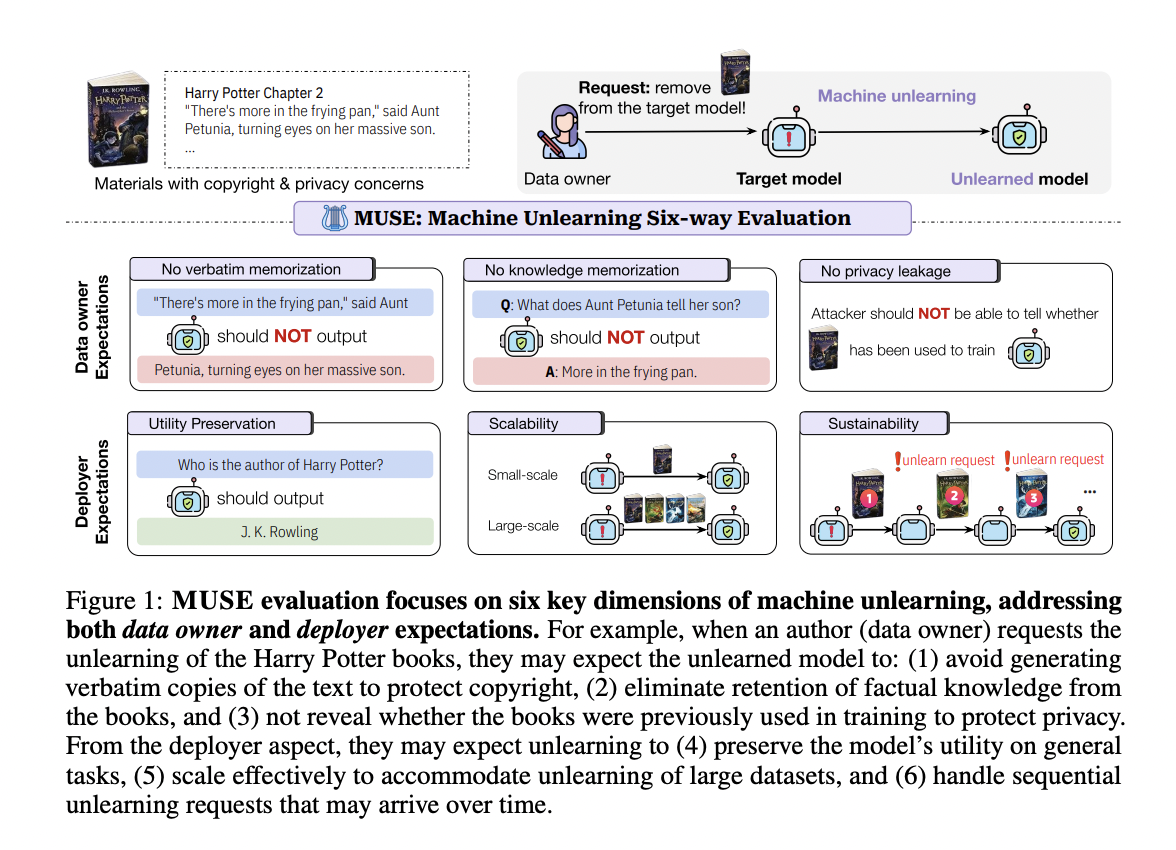
Фреймворк MUSE для Оценки Машинного Забывания
Исследователи из Университета Вашингтона, Принстонского Университета, Университета Южной Калифорнии, Чикагского Университета и Google Research представляют MUSE (Machine Unlearning Six-Way Evaluation) — комплексный фреймворк, разработанный для оценки эффективности алгоритмов машинного забывания для моделей языка. Этот систематический подход оценивает шесть критических свойств, которые удовлетворяют требованиям как владельцев данных, так и развертывающих модели по поводу практичного забывания. MUSE проверяет способность алгоритмов забывания удалить буквальное запоминание, запоминание знаний и утечки конфиденциальной информации, а также оценивает их способность сохранять полезность, масштабироваться и поддерживать производительность при многократных запросах на забывание. Применяя этот подход для оценки восьми представительных алгоритмов машинного забывания на наборах данных, сфокусированных на забывании книг о Гарри Поттере и новостных статьях, MUSE предоставляет комплексное представление о текущем состоянии и ограничениях методов забывания в реальных сценариях.
Критерии Оценки Фреймворка MUSE
Фреймворк MUSE предлагает комплексный набор метрик оценки, удовлетворяющих ожиданиям как владельцев данных, так и развертывающих модель, касающихся машинного забывания в моделях языка. Фреймворк состоит из шести ключевых критериев:
Ожидания владельцев данных:
- Отсутствие буквального запоминания: Измеряется посредством предъявления модели начала последовательности из набора данных для забывания и сравнения продолжения модели с истинным продолжением с использованием оценки ROUGE-L F1.
- Отсутствие запоминания знаний: Оценивается путем проверки способности модели отвечать на вопросы, полученные из набора данных для забывания, с использованием метрики ROUGE для сравнения ответов, сгенерированных моделью, с истинными ответами.
- Отсутствие утечки конфиденциальной информации: Оценивается с использованием метода атаки на определение членства (MIA) для выявления того, сохраняет ли модель информацию, указывающую на то, что набор данных для забывания был частью обучающих данных.
Ожидания развертывающего модель:
- Сохранение полезности: Измеряется путем оценки производительности модели на наборе данных для сохранения с использованием метрики запоминания знаний.
- Масштабируемость: Оценивается путем изучения производительности модели на наборах данных для забывания различного размера.
- Устойчивость: Анализируется путем отслеживания производительности модели при последовательных запросах на забывание.
МUSE оценивает эти метрики на двух представительных наборах данных: NEWS (новостные статьи BBC) и BOOKS (серия о Гарри Поттере), предоставляя реалистичную площадку для оценки алгоритмов забывания в практических сценариях.
Фреймворк MUSE выявил значительные проблемы в машинном забывании для моделей языка. В то время как большинство методов эффективно удаляли буквальное и запоминание знаний, они сталкивались с утечкой конфиденциальной информации, часто недо- или пере-забывая. Все методы значительно ухудшили полезность модели, при этом некоторые сделали модели непригодными для использования. Возникли проблемы масштабируемости с увеличением размеров наборов данных для забывания, и устойчивость оказалась проблематичной при последовательных запросах на забывание, что привело к постепенному ухудшению производительности. Эти результаты подчеркивают значительные компромиссы и ограничения в текущих методах забывания, акцентируя настоятельную потребность в разработке более эффективных и сбалансированных подходов для удовлетворения требований как владельцев данных, так и развертывающих модели.
Это исследование представляет MUSE, комплексный бенчмарк оценки машинного забывания, оценивающий шесть ключевых свойств, критических как для владельцев данных, так и развертывающих модель. Оценка показывает, что, хотя текущие методы забывания эффективно предотвращают запоминание контента, они делают это за значительную цену для полезности модели на сохраненных данных. Кроме того, эти методы часто приводят к значительной утечке конфиденциальной информации и испытывают сложности с масштабируемостью и устойчивостью при обработке удаления контента крупномасштабных или последовательных запросов на забывание. Эти результаты подчеркивают ограничения существующих подходов и акцентируют насущную необходимость в разработке более надежных и сбалансированных методов машинного забывания, способных лучше удовлетворять сложные требования реальных приложений.
Проверьте Paper and Project. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram Channel и LinkedIn Group.
Если вам нравится наша работа, вам понравится наш newsletter.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
Применение Искусственного Интеллекта для вашего Бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте MUSE: A Comprehensive AI Framework for Evaluating Machine Unlearning in Language Models.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















