
«`html
Снижение затрат на обучение LLM с помощью метода обучения на уровне патчей
Инновационный подход к оптимизации процесса обучения моделей на больших данных
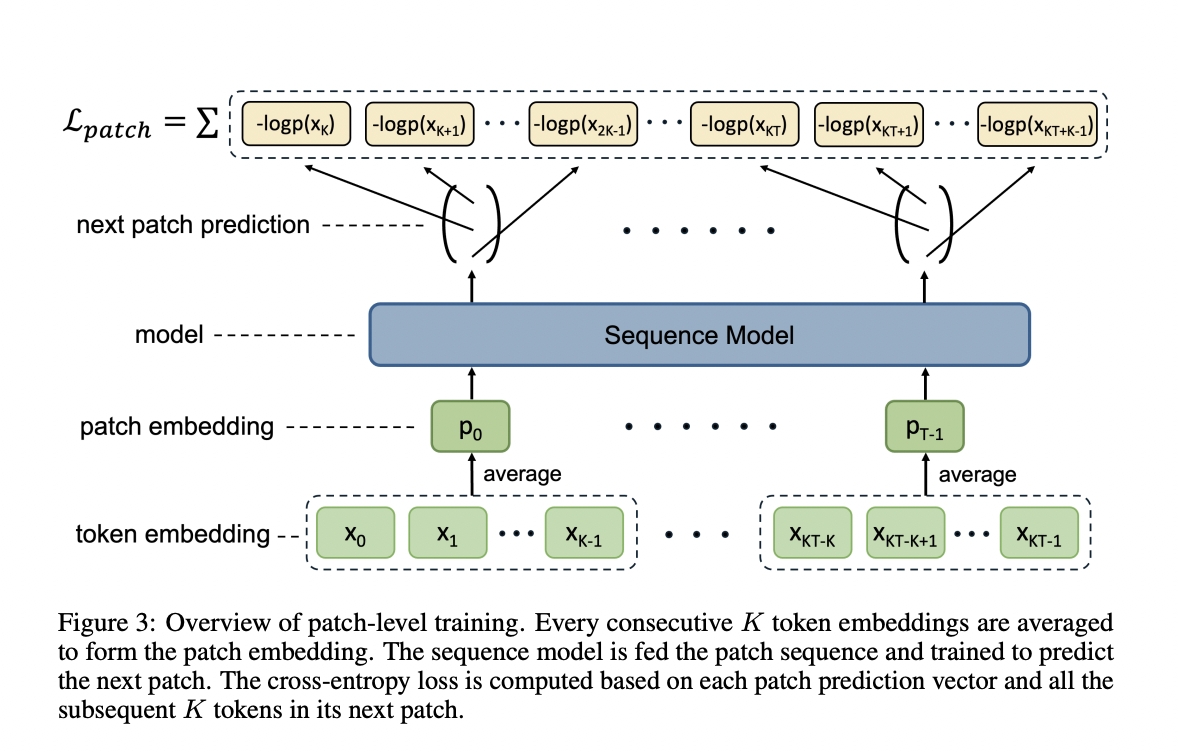
Благодаря предложенному методу обучения на уровне патчей от исследователей из Pattern Recognition Center, WeChat AI, Tencent Inc., удалось значительно сократить издержки на обучение и повысить эффективность моделей LLM. Основная идея заключается в сжатии нескольких токенов в один патч для уменьшения последовательности, что позволяет значительно сократить вычислительные затраты.
Метод предполагает два основных компонента: обучение на уровне патчей и обучение на уровне токенов. Это позволяет эффективно повысить скорость обучения и снизить расходы. Важно, что этот подход не требует изменений в архитектуре модели или разработки сложных методов отображения.
Благодаря экспериментальным результатам, этот метод позволяет сократить затраты на обучение LLM на 50%, сохраняя при этом производительность модели на сопоставимом уровне. Открывается перспектива дальнейших исследований и тестирования масштабирования этого подхода на более крупных моделях и наборах данных, что может принести еще больше выгоды.
Для получения подробной информации о исследовании и его применении, обращайтесь к статье и репозиторию на GitHub.
Если вам интересно, как можно применить этот подход в вашем бизнесе, свяжитесь с нашей командой AI-экспертов для консультации по внедрению наших решений.
«`



















