
«`html
The GTA Benchmark: A New Standard for General Tool Agent AI Evaluation
Новое исследование решает важную проблему оценки возможностей использования инструментов больших моделей языка (LLM) в реальных сценариях. Существующие бенчмарки часто не могут эффективно измерить эти возможности, так как они основаны на запросах, созданных искусственным интеллектом, одношаговых задачах, фиктивных инструментах и текстовых взаимодействиях, которые не отражают сложности и требования реального решения проблем.
Практические решения и ценность:
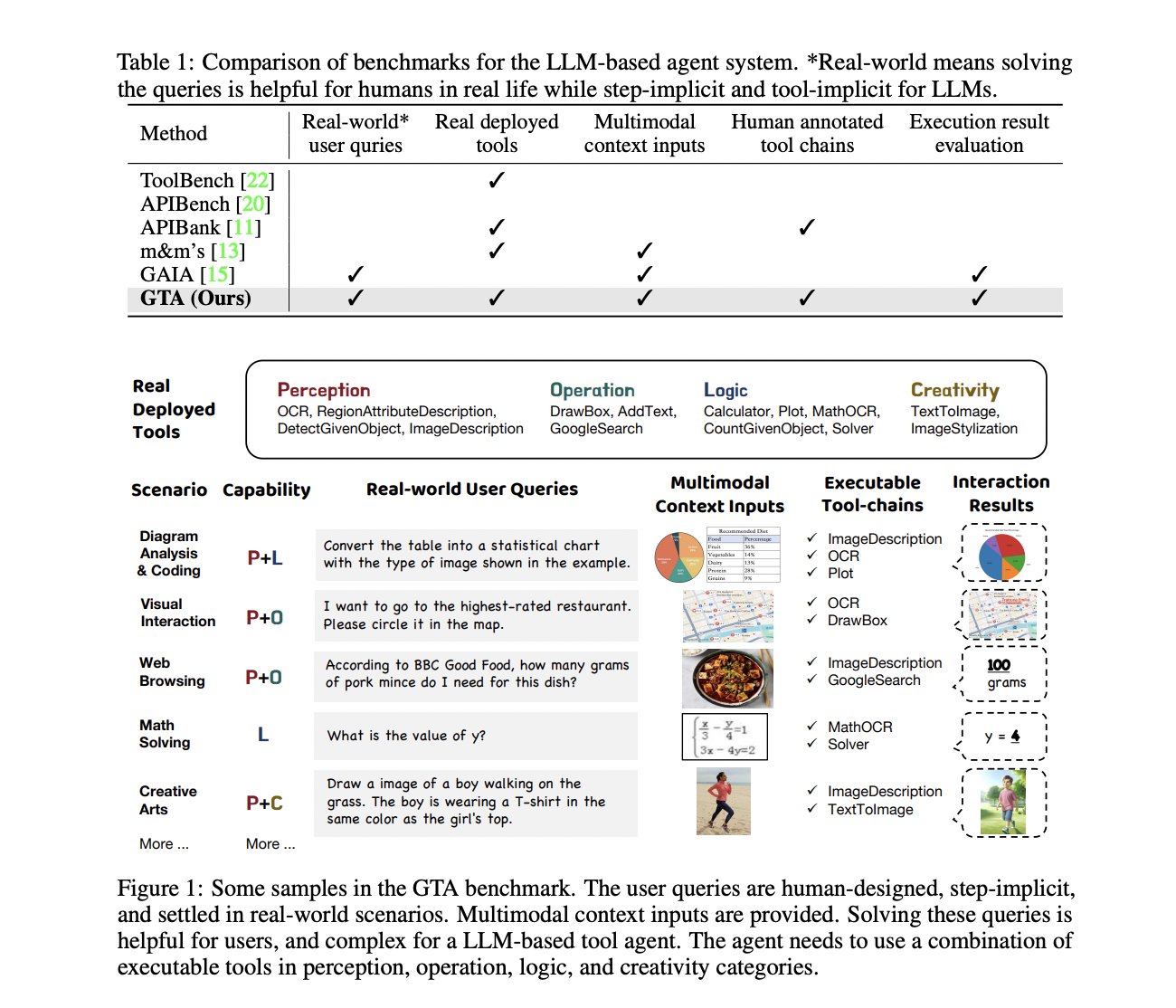
Мы предлагаем использовать инновационный бенчмарк GTA для более точной оценки возможностей LLM в реальных ситуациях. Этот бенчмарк включает в себя запросы, написанные людьми с неявными требованиями к использованию инструментов, реальные инструменты из различных категорий и мультимодальные входы, которые близки к реальным контекстам. Такая настройка обеспечит более полную и реалистичную оценку способности LLM планировать и выполнять сложные задачи с использованием различных инструментов.
Бенчмарк GTA состоит из 229 реальных задач, требующих использования различных инструментов. Каждая задача включает несколько шагов и требует рассуждений и планирования со стороны LLM для определения, какие инструменты использовать и в каком порядке. Оценка проводится в двух режимах: пошаговом и полномасштабном. В пошаговом режиме LLM получает начальные шаги референсной цепочки инструментов и должен предсказать следующее действие. Этот режим позволяет детально сравнить выводы модели с референсными шагами.
В полномасштабном режиме LLM вызывает инструменты и пытается самостоятельно решить проблему, при этом каждый шаг зависит от предыдущих. Этот режим отражает фактическую производительность выполнения задач LLM. Исследователи используют несколько метрик для оценки производительности, включая точность следования инструкциям, точность выбора инструментов, точность аргументов, точность сводки в пошаговом режиме и точность ответа в полномасштабном режиме.
Результаты показывают, что реальные задачи представляют существенную сложность для текущих LLM. Лучшие модели, GPT-4 и GPT-4o, смогли правильно решить менее 50% задач. Другие модели достигли менее 25% точности. Однако эти результаты также подчеркивают потенциал улучшения возможностей использования инструментов LLM. Среди моделей с открытым исходным кодом Qwen-72b достигла наивысшей точности, демонстрируя, что с дальнейшим развитием LLM могут лучше соответствовать требованиям реальных сценариев.
Бенчмарк GTA эффективно выявляет недостатки текущих LLM в обработке реальных задач использования инструментов. Путем использования запросов, написанных людьми, реальных инструментов и мультимодальных входов, бенчмарк обеспечивает более точную и всестороннюю оценку возможностей LLM. Полученные результаты подчеркивают необходимость дальнейшего развития агентов общего назначения для использования инструментов. Этот бенчмарк устанавливает новый стандарт для оценки LLM и будет служить важным руководством для будущих исследований, направленных на улучшение их профессионализма в использовании инструментов.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 46k+ ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`




















