
«`html
Мульти-модальные генеративные модели: оптимизация через совместную разработку данных и моделей
Мульти-модальные генеративные модели интегрируют различные типы данных, такие как текст, изображения и видео, расширяя область применения ИИ в различных областях. Однако оптимизация этих моделей представляет сложные задачи, связанные с обработкой данных и обучением моделей. Необходимость согласованных стратегий для улучшения как данных, так и моделей критически важна для достижения высокой производительности ИИ.
Проблема и решение
Основная проблема в разработке мульти-модальных генеративных моделей заключается в изолированном развитии подходов, ориентированных на данные и модели. Исследователи часто сталкиваются с трудностями интеграции обработки данных и обучения моделей, что приводит к неэффективности и неоптимальным результатам. Текущие методы разработки мульти-модальных генеративных моделей обычно фокусируются либо на улучшении алгоритмов и архитектур моделей, либо на совершенствовании техник обработки данных. Эти методы работают независимо друг от друга, что приводит к фрагментированным и менее эффективным усилиям в разработке.
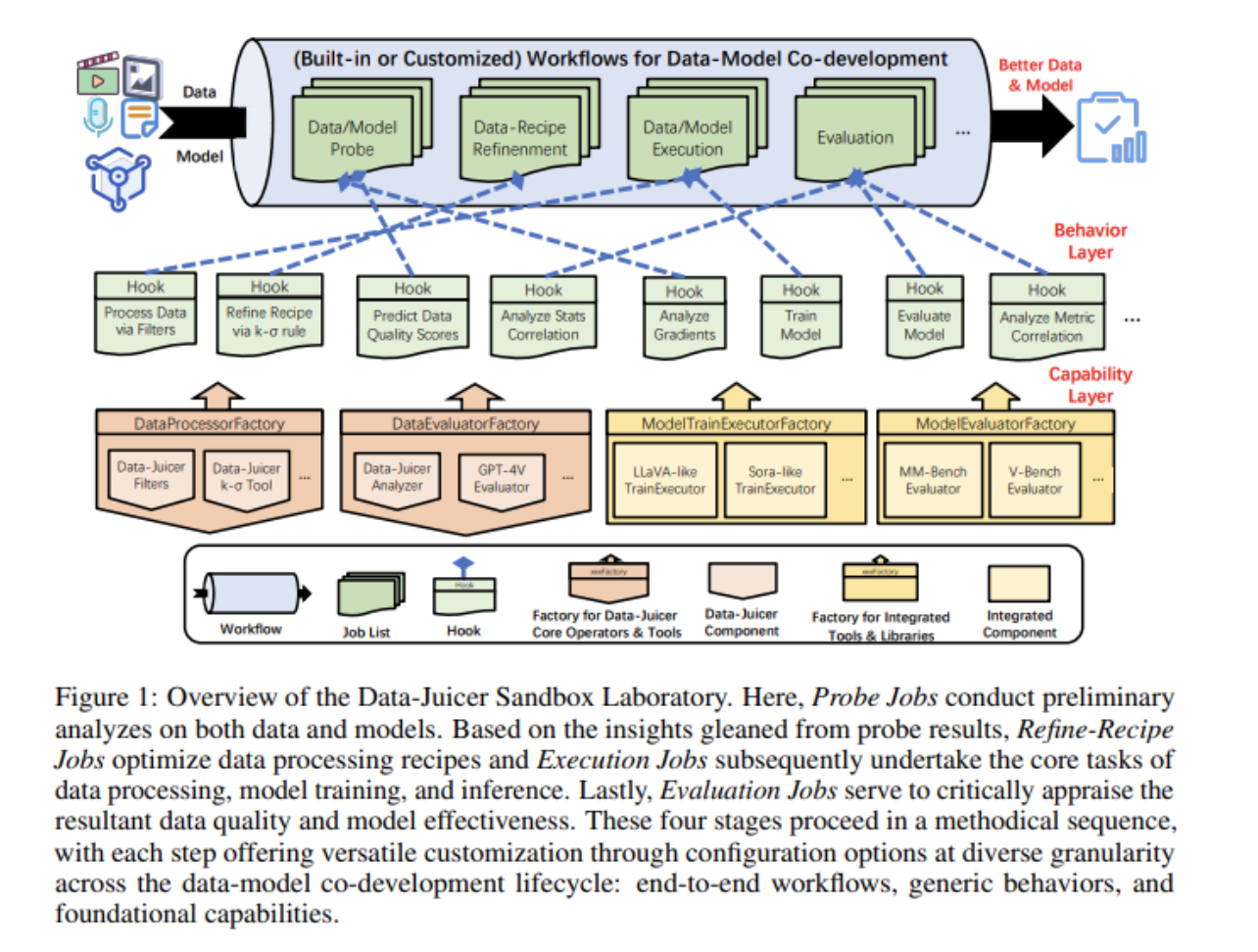
Исследователи из Alibaba Group представили Data-Juicer Sandbox, открытый набор инструментов, который решает эти проблемы. Этот инструмент облегчает совместную разработку мульти-модальных данных и генеративных моделей, интегрируя различные настраиваемые компоненты. Он предлагает гибкую платформу для систематического исследования и оптимизации, сокращая разрыв между обработкой данных и обучением моделей. Data-Juicer Sandbox разработан для упрощения процесса разработки и улучшения синергии между данными и моделями.
Практические результаты
Data-Juicer Sandbox достиг значительного улучшения производительности в нескольких задачах. Например, для генерации текста по изображению средняя производительность на TextVQA, MMBench и MME увеличилась на 7,13%. В задаче генерации видео по тексту, используя модель EasyAnimate, Sandbox занял первое место в рейтинге VBench, превзойдя сильных конкурентов. Эксперименты также продемонстрировали увеличение эстетических оценок на 59,9% и улучшение языковых оценок на 49,9% при использовании высококачественных данных. Эти результаты подчеркивают эффективность Sandbox в оптимизации мульти-модальных генеративных моделей.
Заключение
Data-Juicer Sandbox решает критическую проблему интеграции обработки данных и обучения моделей в мульти-модальных генеративных моделях. Предоставляя систематическую и гибкую платформу для совместной разработки, он позволяет исследователям достичь значительных улучшений в производительности ИИ. Этот инновационный подход представляет собой значительное достижение в области ИИ, предлагая комплексное решение для задач оптимизации мульти-модальных генеративных моделей.
Подробнее о статье и проекте можно узнать на этой странице. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram. Если вам понравилась наша работа, вам понравится и наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 46 тысячами подписчиков.
Вы также можете найти предстоящие вебинары по ИИ здесь.
Эта статья была опубликована на портале MarkTechPost.
«`



















