
«`html
Искусственный интеллект и генерация аудио: новые возможности
Открытые модели и их значение
В области искусственного интеллекта открытые генеративные модели являются основой для прогресса. Они играют важную роль в научных исследованиях и стимулируют творчество, позволяя настраивать и использовать их в качестве эталонов для новых инноваций. Однако существует значительная проблема: многие передовые модели текст-в-аудио остаются закрытыми, что ограничивает доступ исследователей.
Новая открытая модель текст-в-аудио
Команда исследователей из Stability AI представила новую открытую модель текст-в-аудио, обученную исключительно на данных Creative Commons. Эта парадигма призвана обеспечить открытость и этичное использование данных, предоставляя сообществу искусственного интеллекта мощный инструмент.
Ключевые особенности новой модели
Новая модель имеет открытые веса, в отличие от многих закрытых моделей, что позволяет исследователям и разработчикам изучать, изменять и расширять модель, так как её конструкция и параметры доступны общественности.
Для обучения модели использовались только аудиофайлы с лицензией Creative Commons, что гарантирует этичность и законность использованных данных.
Архитектура новой модели
Модель использует сложную архитектуру, обеспечивающую высокую точность синтеза аудио из текста. При частоте дискретизации 44,1 кГц она способна генерировать высококачественный стереозвук, соответствуя строгим требованиям к четкости и реализму.
В процессе обучения модели использовались разнообразные аудиофайлы с лицензией Creative Commons, что обеспечивает её способность генерировать реалистичные и разнообразные звуковые выходы.
Оценка производительности модели
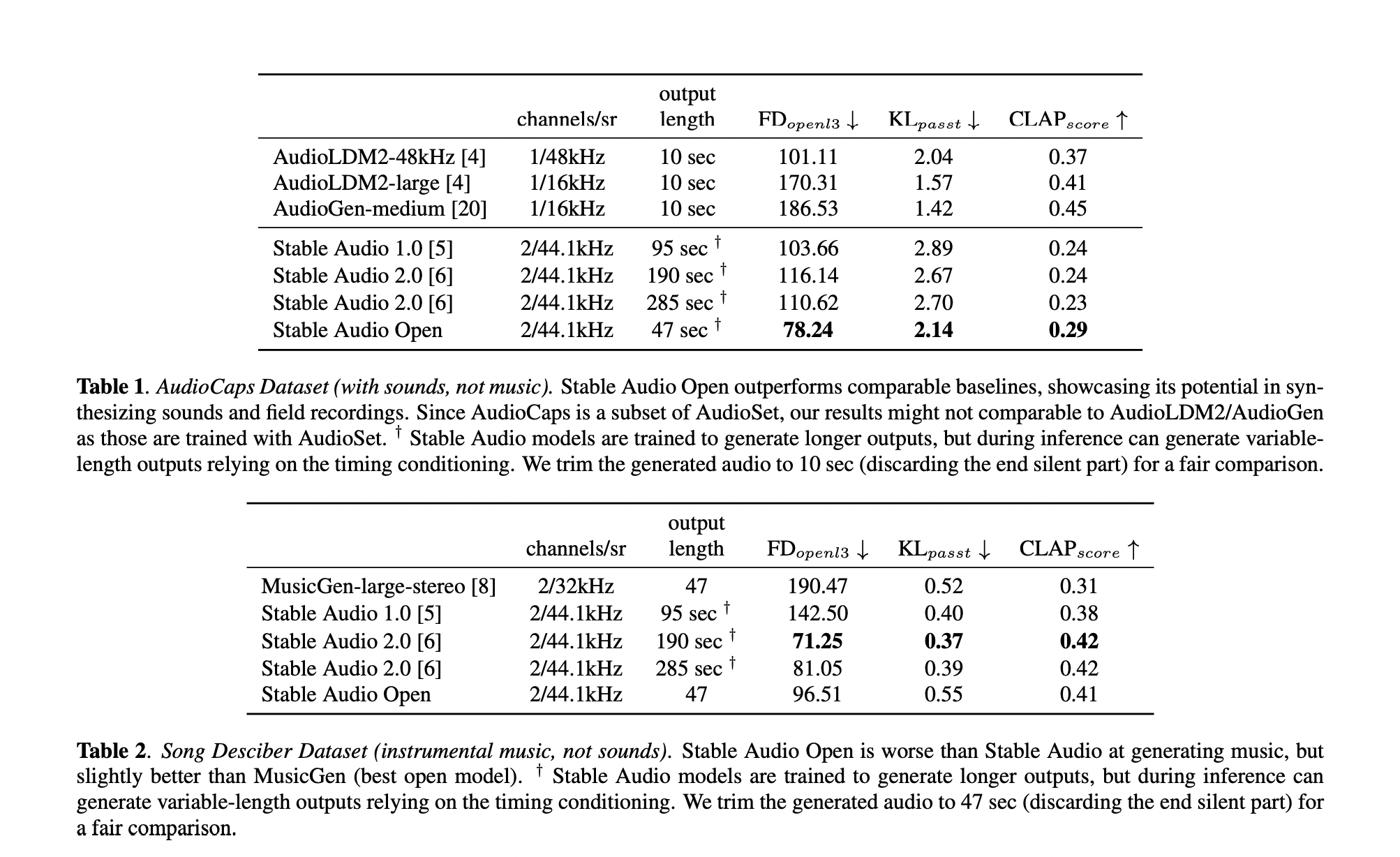
Производительность модели была тщательно оценена, и результаты показали, что она способна генерировать высококачественное аудио, не уступая лучшим моделям отрасли. Сравнительное исследование подтвердило превосходство новой модели по качеству и удобству использования.
Заключение
Развитие технологии генерации аудио значительно продвинулось благодаря выпуску этой открытой модели текст-в-аудио. Она решает множество существующих проблем в отрасли, подчеркивая открытость, этичное использование данных и высококачественный синтез аудио. Эта модель устанавливает новые стандарты для производства текст-в-аудио и является значительным ресурсом для ученых, художников и разработчиков.
Источник: MarkTechPost
Бумага, модель и GitHub: Stability AI
Следите за нами в Twitter и присоединяйтесь к нашим группам в Telegram и LinkedIn. Подписывайтесь на нашу рассылку.
Присоединяйтесь к нашему SubReddit.
Найдите предстоящие вебинары по искусственному интеллекту здесь.
«`


















