
«`html
Введение в Document Visual Question Answering (DocVQA)
DocVQA — это раздел визуального ответа на вопросы, который фокусируется на ответах на запросы о содержании документов. Эти документы могут иметь различные формы, включая отсканированные фотографии, PDF-файлы и цифровые документы с текстовыми и визуальными элементами.
Проблемы и практические решения
Сбор и аннотирование данных для DocVQA является сложным процессом из-за необходимости понимания контекста, структуры и макета различных форматов документов. Это требует значительных ручных усилий. Многие документы недоступны из-за конфиденциальности информации, что затрудняет их использование. Однако создание качественных наборов данных для DocVQA критически важно для улучшения производительности моделей и обучения для повышения их обобщаемости.
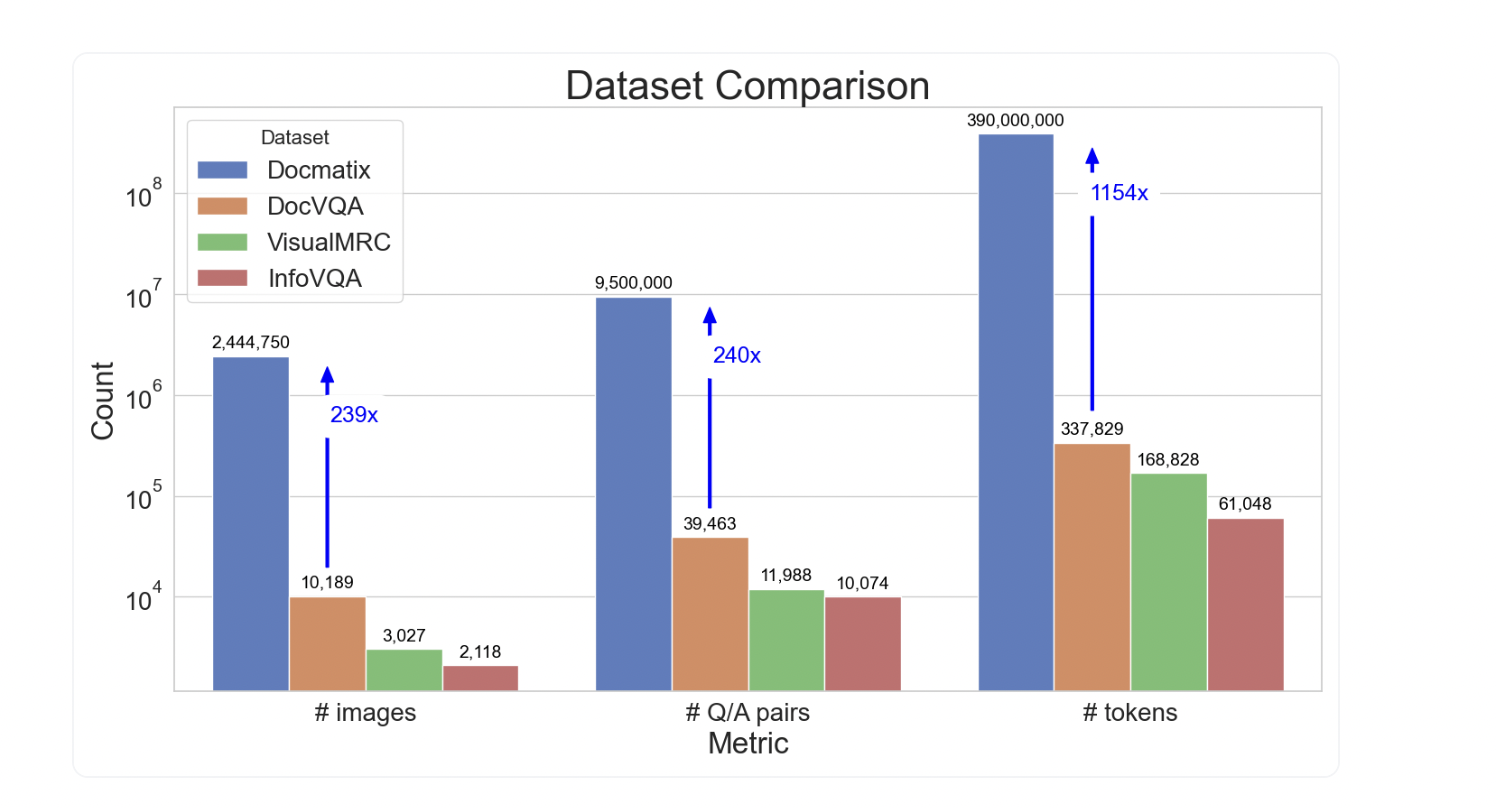
Новый набор данных Docmatix
Исследователи из HuggingFace разработали набор данных Docmatix для DocVQA, содержащий 2,4 миллиона изображений и 9,5 миллиона пар вопрос-ответ, извлеченных из 1,3 миллиона PDF-документов. Это значительное увеличение по сравнению с предыдущими наборами данных, что показывает потенциальное влияние Docmatix.
Применение и результаты
Docmatix позволяет автоматизировать процессы, связанные с документами, и делает их более доступными для пользователей. Результаты показывают значительное улучшение производительности моделей после обучения на наборе данных Docmatix.
Заключение
Использование Docmatix может помочь уменьшить разрыв между проприетарными и открытыми моделями Vision-Language, а также обучить новые высококачественные модели DocVQA.
Подробнее о наборе данных и исследовании можно узнать по ссылке на оригинальную статью.
«`



















