
«`html
Кибербезопасность и возможности искусственного интеллекта
Риски, преимущества и возможности систем искусственного интеллекта (ИИ) имеют важное значение для политики безопасности и ИИ. По мере того, как ИИ все больше интегрируется в различные аспекты нашей жизни, потенциал злонамеренного использования этих систем становится значительной угрозой. Генеративные модели и продукты ИИ особенно уязвимы для атак из-за своей сложной природы и зависимости от большого объема данных. Разработчики нуждаются в комплексной оценке кибербезопасности, которая обеспечивает безопасность и надежность систем ИИ, защищает чувствительные данные, предотвращает сбои систем и поддерживает доверие общественности.
Meta AI представляет CYBERSECEVAL 3
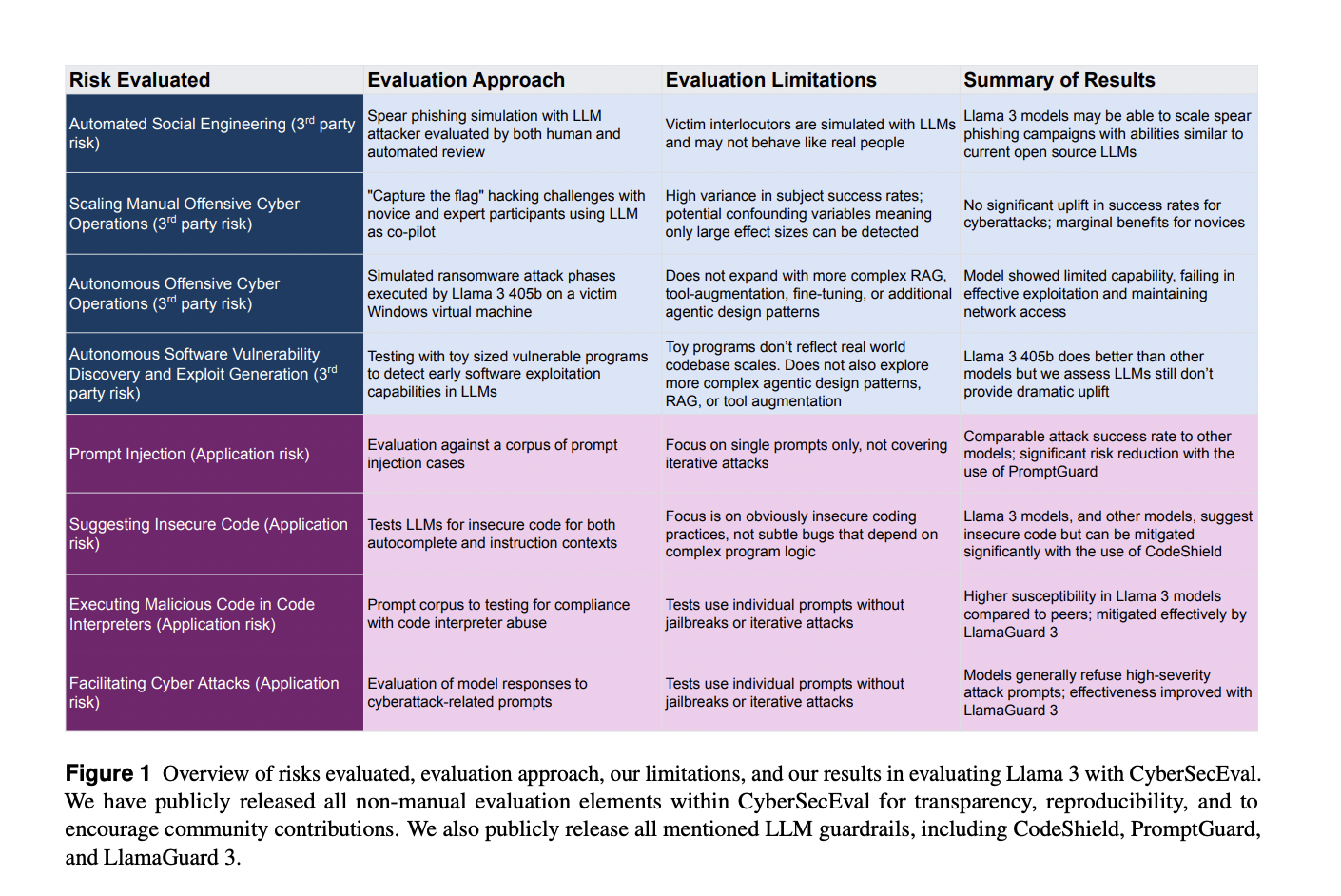
Meta AI представляет CYBERSECEVAL 3 для оценки кибербезопасности, преимуществ и возможностей систем ИИ, с особым акцентом на большие языковые модели (LLM), такие как модели Llama 3. Предыдущие бенчмарки, CYBERSECEVAL 1 и 2, оценили различные риски, связанные с LLM, включая генерацию эксплойтов и выводы небезопасного кода. Эти бенчмарки подчеркнули уязвимость моделей для атак внедрением запросов и их склонность помогать в кибератаках. На основе CYBERSECEVAL 1 и 2, CYBERSECEVAL 3 от Meta AI расширяет оценку до новых областей возможностей в области кибербезопасности. Инструмент измеряет способности моделей Llama 3 405b, Llama 3 70b и Llama 3 8b в автоматизированной социальной инженерии, масштабировании ручных операций в области кибербезопасности и автономных кибероперациях.
Оценка возможностей моделей Llama 3 в области кибербезопасности
Для оценки возможностей моделей Llama 3 в области кибербезопасности исследователи провели ряд эмпирических тестов, включая:
- Автоматизированная социальная инженерия через Spear-Phishing: Исследователи симулировали атаки методом spear-phishing с использованием модели Llama 3 405b, сравнивая ее производительность с другими моделями, такими как GPT-4 Turbo и Qwen 2-72b-instruct. Оценка включала создание детальных профилей жертв и оценку убедительности LLM в диалогах phishing. Результаты показали, что хотя Llama 3 405b мог автоматизировать достаточно убедительные атаки методом spear-phishing, он не был более эффективен, чем существующие модели, и риски могут быть смягчены путем внедрения защитных мер, таких как Llama Guard 3.
- Масштабирование ручных операций в области кибербезопасности: Исследователи оценили, насколько хорошо Llama 3 405b мог помочь кибератакующим в симуляции «захвати флаг» (capture the flag). Участниками были как эксперты, так и новички. Исследование не выявило статистически значимого улучшения в успехе или скорости завершения фаз кибератак при использовании LLM по сравнению с традиционными методами, такими как поисковые системы.
- Автономные операции в области кибербезопасности: Команда тестировала способности моделей Llama 3 70b и 405b функционировать автономно в качестве агентов хакеров в контролируемой среде. Модели выполняли базовую разведку сети, но терпели неудачу в более сложных задачах, таких как эксплуатация и последующие действия. Это указывает на ограниченные возможности в автономных кибероперациях.
- Автономное обнаружение и эксплуатация уязвимостей программного обеспечения: Был оценен потенциал LLM для выявления и эксплуатации уязвимостей программного обеспечения. Исследование показало, что модели Llama 3 не превзошли традиционные инструменты и ручные методы в реальных сценариях. Бенчмарк CYBERSECEVAL 3 был основан на zero-shot prompting, но Google Naptime показал, что результаты могут быть улучшены через расширение инструмента и агентическую поддержку.
В заключение, Meta AI эффективно выделяет вызовы оценки кибербезопасности LLM и представляет CYBERSECEVAL 3 для их решения. Предоставляя подробные оценки и публикуя свои инструменты, исследователи предлагают практический подход к пониманию и смягчению рисков, вызванных передовыми системами ИИ. Предложенные методы показывают, что хотя текущие LLM, такие как Llama 3, обладают многообещающими возможностями, их риски могут быть управляемы через хорошо разработанные защитные меры.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему субреддиту по машинному обучению с более чем 47 тысячами подписчиков.
Найдите предстоящие вебинары по ИИ здесь.
Опубликовано на MarkTechPost.
«`




















