
«`html
Улучшение качества и безопасности с помощью обучения с подкреплением от обратной связи человека (RLHF)
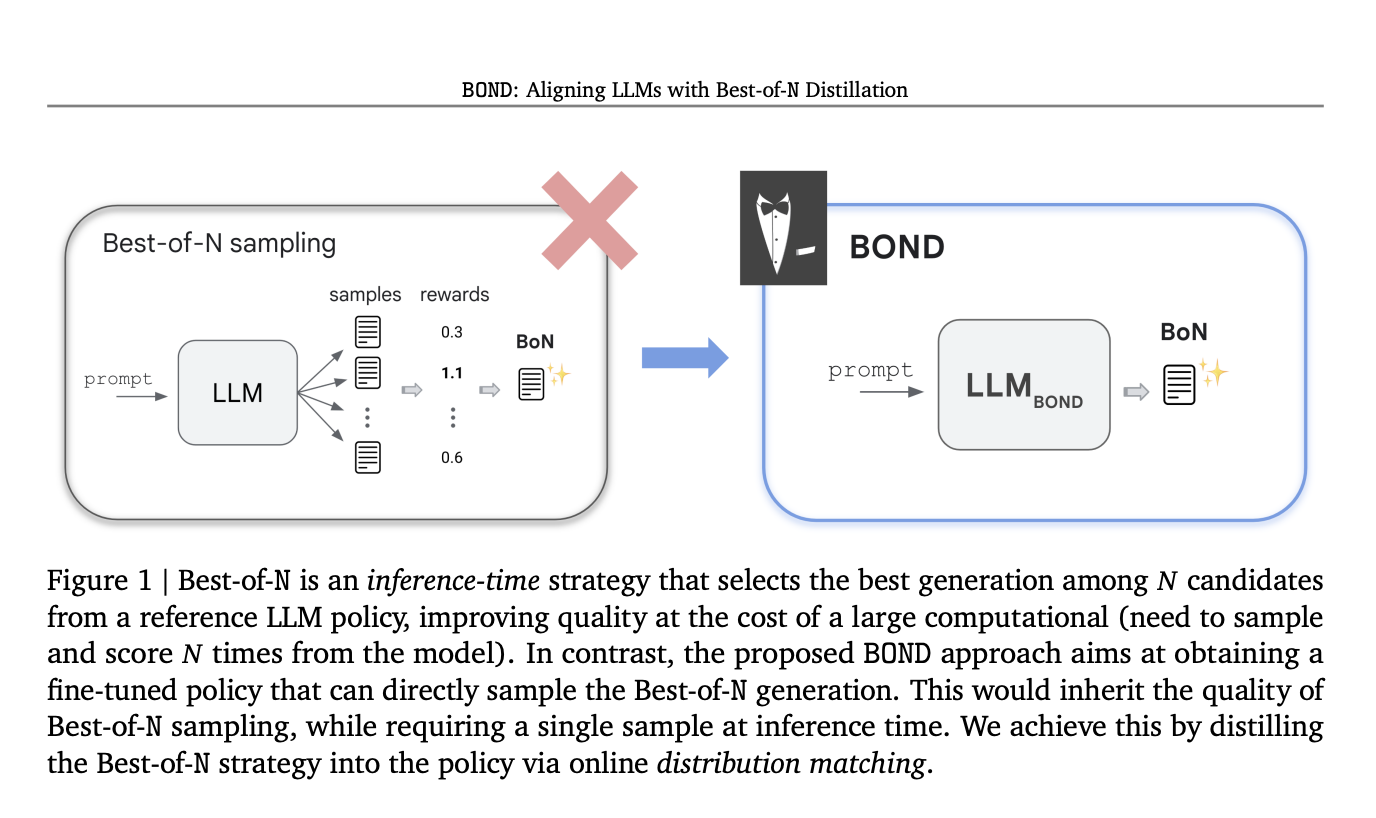
Обучение с подкреплением от обратной связи человека (RLHF) является ключевым элементом обеспечения качества и безопасности в языковых моделях с ограниченной памятью (LLM). Современные LLM, такие как Gemini и GPT-4, проходят три этапа обучения: предварительное обучение на больших корпусах, SFT и RLHF для улучшения качества генерации. RLHF включает в себя обучение модели вознаграждения (RM) на основе предпочтений людей и оптимизацию LLM для максимизации предсказанных вознаграждений. Этот процесс сложен из-за забывания предварительно обученных знаний и взлома вознаграждения. Практический подход для улучшения качества генерации — это Best-of-N выбор, который выбирает лучший результат из N сгенерированных кандидатов, эффективно балансируя вознаграждение и вычислительные затраты.
Инновационный алгоритм RLHF BOND от Google DeepMind
Исследователи из Google DeepMind представили Best-of-N Distillation (BOND), инновационный алгоритм RLHF, разработанный для воспроизведения производительности Best-of-N выбора без его высоких вычислительных затрат. BOND — это алгоритм сопоставления распределений, который выравнивает вывод политики с распределением Best-of-N. Используя дивергенцию Джеффриса, который балансирует покрытие моды и поиск моды, BOND итеративно улучшает политику через подход с двигающейся якорной точкой. Эксперименты по абстрактному резюмированию и моделям Gemma показывают, что BOND, особенно его вариант J-BOND, превосходит другие алгоритмы RLHF, улучшая компромисс между KL-вознаграждением и производительностью.
Практическая реализация алгоритма J-BOND
J-BOND — это практическая реализация алгоритма BOND, разработанная для тонкой настройки политик с минимальной сложностью выборки. Он итеративно улучшает политику, чтобы выравняться с лучшими из 2 выборок, используя дивергенцию Джеффриса. Процесс включает генерацию выборок, расчет градиентов для прямой и обратной KL-компонент, и обновление весов политики. Политика якоря обновляется с использованием экспоненциального скользящего среднего (EMA), что улучшает стабильность обучения и улучшает компромисс между вознаграждением и KL. Эксперименты показывают, что J-BOND превосходит традиционные методы RLHF, демонстрируя эффективность и лучшую производительность без необходимости фиксированного уровня регуляризации.
Применение метода BOND в практике
Метод BOND включает два основных этапа. Во-первых, он выводит аналитическое выражение для распределения Best-of-N (BoN). Во-вторых, он формулирует задачу как проблему сопоставления распределений с целью выравнивания политики с распределением BoN. Аналитическое выражение показывает, что BoN перевзвешивает опорное распределение, отклоняя плохие генерации при увеличении N. Цель BOND заключается в минимизации расхождения между политикой и распределением BoN. Для надежного сопоставления распределений предлагается использовать дивергенцию Джеффриса, балансирующую прямые и обратные KL-дивергенции. Итеративный BOND улучшает политику путем многократного применения дистилляции BoN с небольшим N, улучшая производительность и стабильность.
Посетите ссылку на статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подразделению ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Опубликовано на MarkTechPost