
«`html
Введение в Long-form RobustQA Dataset и RAG-QA Arena для оценки кросс-доменной работы систем генерации ответов на запросы
Вопросно-ответная система (QA) является важной областью обработки естественного языка (NLP), фокусирующейся на разработке систем, способных точно извлекать и генерировать ответы на запросы пользователей из обширных источников данных. Retrieval-augmented generation (RAG) улучшает качество и актуальность ответов, комбинируя информационный поиск с генерацией текста. Этот подход фильтрует неактуальную информацию и представляет только наиболее подходящие отрывки для генерации ответов с использованием больших языковых моделей.
Ограничения и инновации в области QA
Одним из основных вызовов в QA является ограниченный объем существующих наборов данных, которые часто используют корпуса из одного источника или фокусируются на кратких, извлекаемых ответах. Текущие методы, такие как Natural Questions и TriviaQA, сильно полагаются на Википедию или веб-документы, что недостаточно для оценки обобщения работы LLM между различными областями. В результате существует значительная необходимость в более полных оценочных каркасах, способных тестировать устойчивость QA систем в различных областях.
Новый подход к оценке QA систем
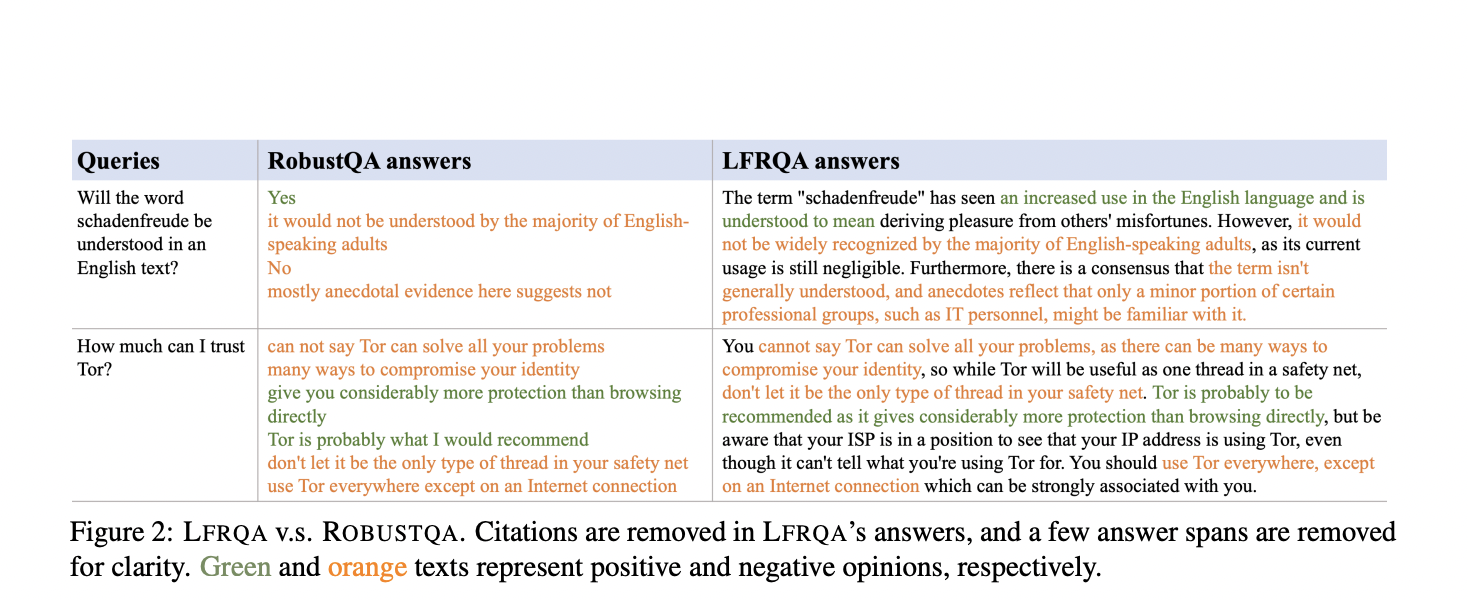
Исследователи из AWS AI Labs, Google, Samaya.ai, Orby.ai и Университета Калифорнии в Санта-Барбаре представили Long-form RobustQA (LFRQA) для решения этих ограничений. Этот новый набор данных включает в себя длинные ответы, написанные людьми, интегрирующие информацию из нескольких документов в последовательные повествования. Охватывая 26 000 запросов по семи областям, LFRQA направлен на оценку способности LLM-основанных RAG-QA систем к обобщению работы между областями.
Преимущества LFRQA и RAG-QA Arena
LFRQA отличается от предыдущих наборов данных тем, что предлагает длинные ответы, основанные на корпусе, обеспечивая последовательность и охватывая несколько областей. Набор включает аннотации из различных источников, что делает его ценным инструментом для оценки QA систем. Этот подход решает недостатки извлекаемых наборов данных, которые часто не улавливают всесторонний и детальный характер современных ответов LLM.
Команда исследователей представила фреймворк RAG-QA Arena для использования LFRQA при оценке QA систем. Этот фреймворк использует модельных оценщиков для прямого сравнения ответов, сгенерированных LLM, с длинными ответами, написанными людьми в LFRQA. Фокусируясь на длинные, последовательные ответы, RAG-QA Arena предоставляет более точную и сложную оценку для QA систем. Обширные эксперименты продемонстрировали высокую корреляцию между модельными и человеческими оценками, подтверждая эффективность фреймворка.
Результаты и перспективы
Результаты работы фреймворка RAG-QA Arena показывают значительные выводы. Только 41,3% ответов, сгенерированных самыми конкурентоспособными LLM, предпочтительнее длинных ответов, написанных людьми в LFRQA. Кроме того, оценка показала, что ответы LFRQA, интегрирующие информацию из до 80 документов, предпочтительны в 59,1% случаев по сравнению с ведущими ответами LLM. Фреймворк также выявил разрыв в 25,1% в производительности между внутриобластными и междуобластными данными, подчеркивая важность кросс-доменной оценки для развития устойчивых QA систем.
Кроме своего всестороннего характера, LFRQA включает подробные метрики производительности, предоставляющие ценные исследовательские данные об эффективности QA систем. Например, набор данных содержит информацию о количестве документов, использованных для генерации ответов, их последовательности и плавности. Эти метрики помогают исследователям понять сильные и слабые стороны различных подходов к QA, указывая на будущие улучшения.
Заключение
Исследование, проведенное AWS AI Labs, Google, Samaya.ai, Orby.ai и Университетом Калифорнии в Санта-Барбаре, подчеркивает ограничения существующих методов оценки QA и представляет LFRQA и RAG-QA Arena как инновационные решения. Эти инструменты предлагают более полную и сложную оценку для оценки кросс-доменной устойчивости QA систем, значительно способствуя развитию исследований в области NLP и QA.
Ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 47k+ ML SubReddit
Найдите предстоящие вебинары по ИИ здесь
Опубликовано на сайте MarkTechPost.
«`


















