
«`html
Датасет MINT-1T: мультимодальный датасет с одним триллионом токенов для создания крупных мультимодальных моделей
Искусственный интеллект, особенно при обучении больших мультимодальных моделей (LMM), тесно связан с обширными наборами данных, включающими последовательности изображений и текста. Эти наборы данных позволяют разрабатывать сложные модели, способные понимать и генерировать мультимодальный контент. По мере усовершенствования возможностей ИИ-моделей становится еще более критической потребность в обширных и высококачественных наборах данных, что побуждает исследователей искать новые методы сбора и курирования данных.
Практические решения и ценность
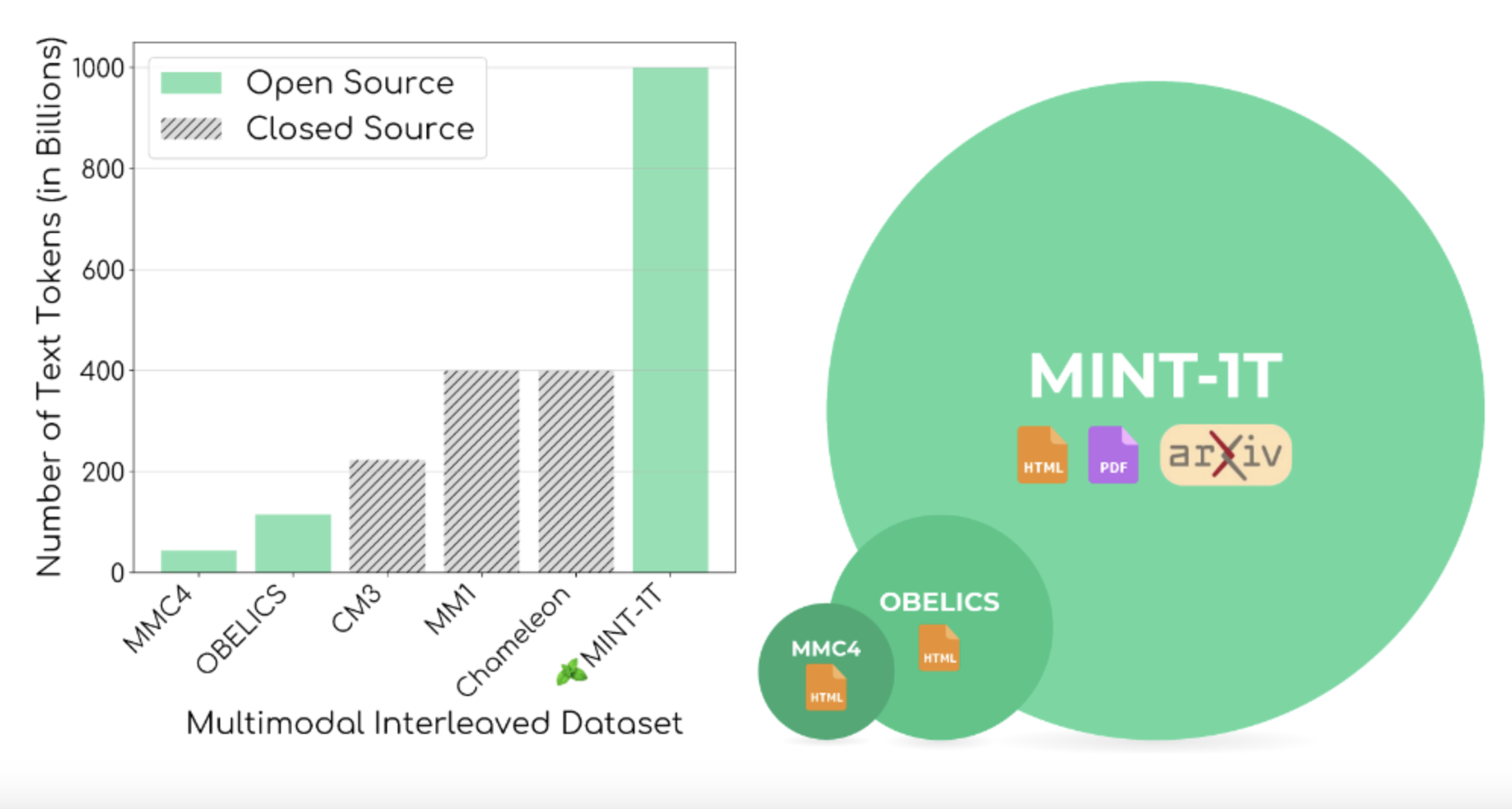
Создание датасета MINT-1T включало в себя сложный процесс сбора, фильтрации и удаления дубликатов данных. Датасет MINT-1T представляет собой один триллион текстовых токенов и 3,4 миллиарда изображений из HTML, PDF и научных статей ArXiv. Этот датасет обеспечивает прочную основу для развития возможностей ИИ.
Эксперименты показали, что модели LMM, обученные на датасете MINT-1T, соответствуют и часто превосходят производительность моделей, обученных на предыдущих ведущих датасетах, таких как OBELICS. Включение более разнообразных источников в MINT-1T привело к лучшей обобщенности и производительности по различным бенчмаркам.
В заключение, датасет MINT-1T решает проблему недостатка и разнообразия датасетов. Представляя более крупный и разнообразный датасет, исследователи создали основу для развития более надежных и высокопроизводительных мультимодальных моделей с открытым исходным кодом.
Подробнее о датасете, исследовании и GitHub можно узнать здесь.
Источник: https://t.co/FHKhkAURdN
«`




















