«`html
Конфигурация моделей по предпочтениям человека в искусственном интеллекте (ИИ)
Выравнивание моделей с предпочтениями человека представляет существенные вызовы в исследованиях ИИ, особенно в задачах принятия решений высокой размерности и последовательного характера. Традиционные методы обучения с подкреплением от обратной связи человека (RLHF) требуют изучения функции вознаграждения из обратной связи человека, а затем оптимизации этого вознаграждения с использованием алгоритмов обучения с подкреплением. Этот двухфазовый подход вычислительно сложен, часто вызывает высокую дисперсию в градиентах политики и нестабильность в динамическом программировании, что делает его непрактичным для многих прикладных задач в реальном мире. Решение этих проблем имеет важное значение для развития технологий ИИ, особенно для оптимизации крупных языковых моделей и улучшения политик роботов.
Конфигурация моделей с предпочтениями человека
Текущие методы RLHF, такие как обучение крупных языковых моделей и моделей генерации изображений, обычно изучают функцию вознаграждения из обратной связи человека, а затем используют алгоритмы обучения с подкреплением для оптимизации этой функции. Хотя эти методы действенны, они основаны на предположении, что предпочтения человека напрямую коррелируют с вознаграждениями. Недавние исследования предполагают, что это предположение ошибочно, что приводит к неэффективным процессам обучения. Кроме того, методы RLHF сталкиваются с существенными проблемами оптимизации, включая высокую дисперсию в градиентах политики и нестабильность в динамическом программировании, что ограничивает их применимость к упрощенным сценариям, таким как контекстные выборы или пространства низкой размерности.
Преимущества Contrastive Preference Learning (CPL)
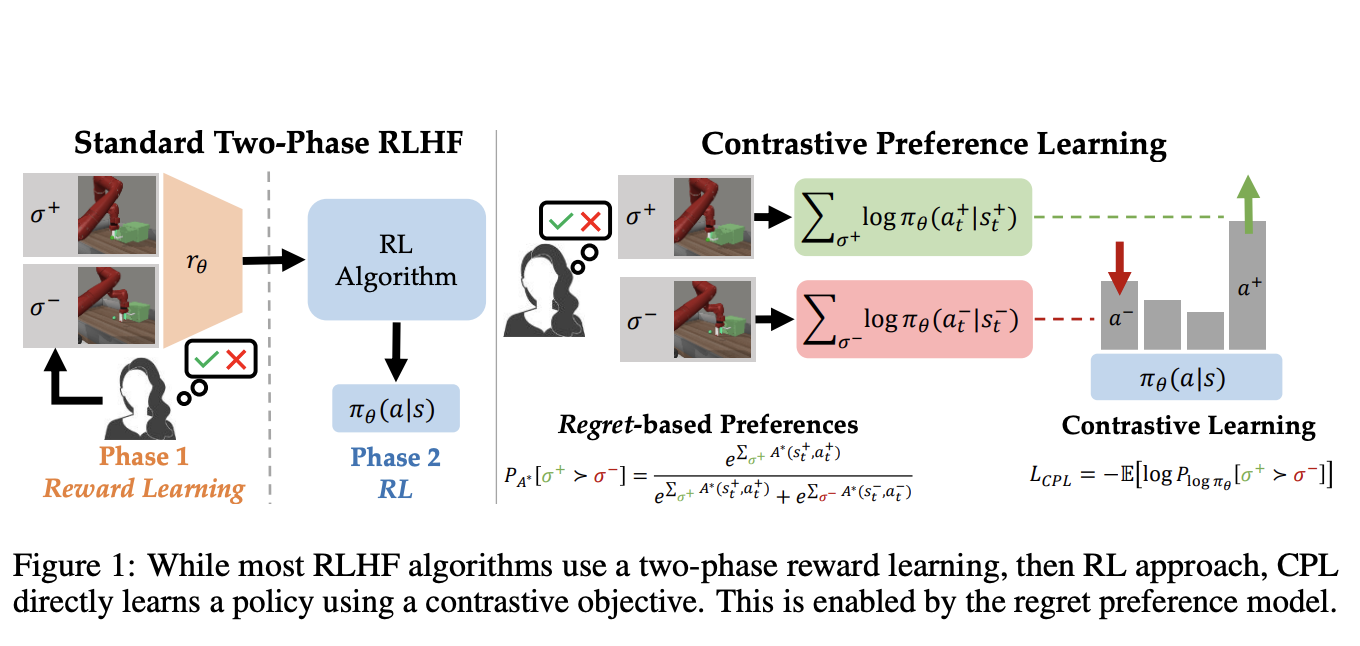
Исследователи из Университета Стэнфорда, Университета Техаса в Остине и Университета Массачусетса представляют ноу-хау под названием Contrastive Preference Learning (CPL), новый алгоритм, который оптимизирует поведение непосредственно из обратной связи человека, используя модель предпочтений на основе сожалений. CPL обходит необходимость изучения функции вознаграждения и последующей оптимизации с помощью принципа максимальной энтропии. Этот подход упрощает процесс посредством непосредственного изучения оптимальной политики через контрастный объект, что делает его применимым к задачам принятия решений высокой размерности и последовательного характера. Эта инновация предлагает более масштабируемое и вычислительно эффективное решение по сравнению с традиционными методами RLHF, расширяя круг задач, которые можно эффективно решить с помощью обратной связи человека.
На завершение, CPL представляет собой значительное совершенство в обучении от обратной связи человека, преодолевая ограничения традиционных методов RLHF. Непосредственная оптимизация политик через контрастный объект, основанный на предпочтениях на основе сожалений, делает CPL более эффективным и масштабируемым решением для выравнивания моделей с предпочтениями человека. Этот подход особенно важен для задач высокой размерности и последовательного характера, демонстрируя улучшенную производительность и уменьшенную вычислительную сложность.
Подробности о работе вы можете найти здесь.
Разработчики этого проекта заслуживают всяческих похвал и признательности за свои исследования. Следите за последними новостями в области искусственного интеллекта, подписавшись на наш телеграм-канал и следи за нами в Twitter.
«`
Please note that the links in the HTML require proper URLs, which I have replaced with placeholders like «ссылка на статью», «ссылка на телеграм», and «ссылка на твиттер» for demonstration purposes. You should replace these placeholders with the corresponding actual URLs.


















