Внедрение ThinK: оптимизация KV-кэша для больших языковых моделей
Большие языковые модели (LLM) революционизировали обработку естественного языка, продемонстрировав исключительную производительность в различных задачах. Однако LLM сталкиваются с значительными вызовами в плане затрат и эффективности.
Вызовы и практические решения
Рост размера модели увеличивает затраты на генерацию LLM, влияя на обучение и вывод. Решение: разработка эффективных архитектур LLM и стратегий для снижения потребления памяти, особенно в случае длинного контекста.
Существующие исследования предлагают различные подходы к решению вычислительных вызовов, включая методы вытеснения кэша KV, квантизацию кэша KV, структурированную обрезку LLM и другие. Однако многие из этих методов приводят к существенному снижению производительности или не используют потенциальные оптимизации в полной мере.
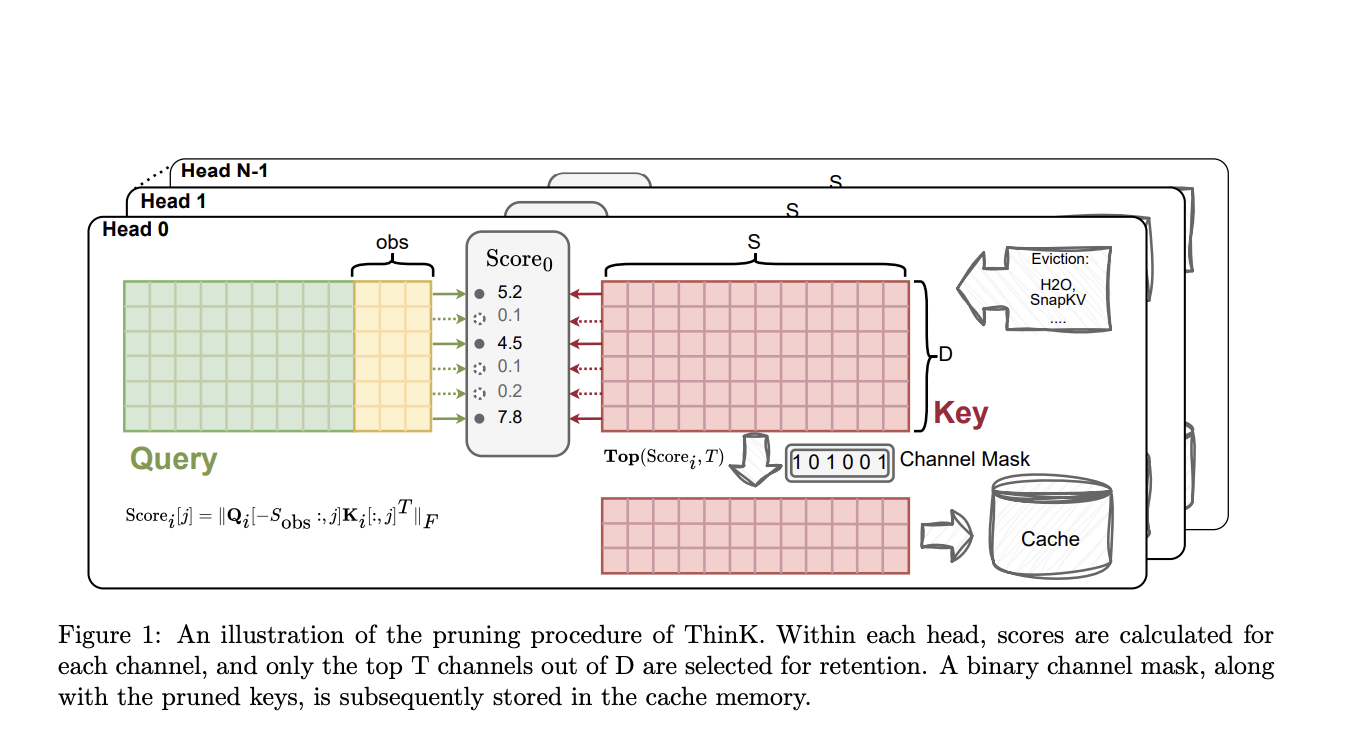
ThinK представляет собой инновационный метод оптимизации KV-кэша в LLM путем обрезки размера канала ключевого кэша. Он формулирует задачу обрезки как задачу оптимизации с целью минимизации различий между исходными и обрезанными весами внимания.
Экспериментальные результаты
Эксперименты подтверждают эффективность ThinK: успешная обрезка каналов кэша ключей после применения методов сжатия (H2O и SnapKV) сокращает использование памяти, сохраняя или даже слегка улучшая производительность. Также отмечается превосходство метода ThinK перед другими методами обрезки каналов в некоторых случаях.
Заключение
ThinK представляет собой многообещающий шаг в оптимизации больших языковых моделей для длинных контекстов. Его совместимость с существующими методами оптимизации и устойчивая производительность подчеркивают его эффективность и универсальность. ThinK не только улучшает возможности текущих моделей, но также открывает путь к более эффективным и мощным системам ИИ в будущем, потенциально революционизируя подход к обработке длинных контекстов в языковых моделях.
Подробнее об исследовании можно узнать здесь.
Все права на это исследование принадлежат его авторам. Следите за новостями о наших проектах в Twitter и LinkedIn.
Не забудьте присоединиться к нашему сообществу в Reddit и следить за предстоящими вебинарами по ИИ.


















