
«`html
Многомодальный искусственный интеллект: преимущества и решения
Многомодальный искусственный интеллект фокусируется на разработке моделей, способных обрабатывать и интегрировать различные типы данных, такие как текст и изображения. Эти модели необходимы для ответов на визуальные вопросы и генерации описательного текста для изображений, подчеркивая способность ИИ понимать и взаимодействовать с многоаспектным миром. Смешивание информации из различных модальностей позволяет ИИ выполнять сложные задачи более эффективно, продемонстрировать значительные перспективы в исследованиях и практических применениях.
Оптимизация эффективности модели
Одним из основных вызовов в многомодальном ИИ является оптимизация эффективности модели. Традиционные методы слияния модально-специфических кодировщиков или декодеров часто ограничивают способность модели эффективно интегрировать информацию различных типов данных. Это приводит к увеличению вычислительных затрат и снижению производительности. Исследователи стремятся разработать новые архитектуры, которые позволят плавно интегрировать текст и изображения с самого начала, с целью улучшения производительности и эффективности модели в обработке многомодальных входных данных.
Инновационные решения для преодоления вызовов
Существующие методы обработки смешанных модальных данных включают архитектуры, которые предварительно обрабатывают и кодируют текст и изображения отдельно перед их интеграцией. Эти подходы, хотя и функциональны, могут быть вычислительно интенсивными и могут только частично раскрыть потенциал начального слияния данных. Разделение модальностей часто приводит к неэффективности и неспособности должным образом охватить сложные взаимосвязи между различными типами данных. Поэтому требуются инновационные решения для преодоления этих вызовов и достижения лучшей производительности.
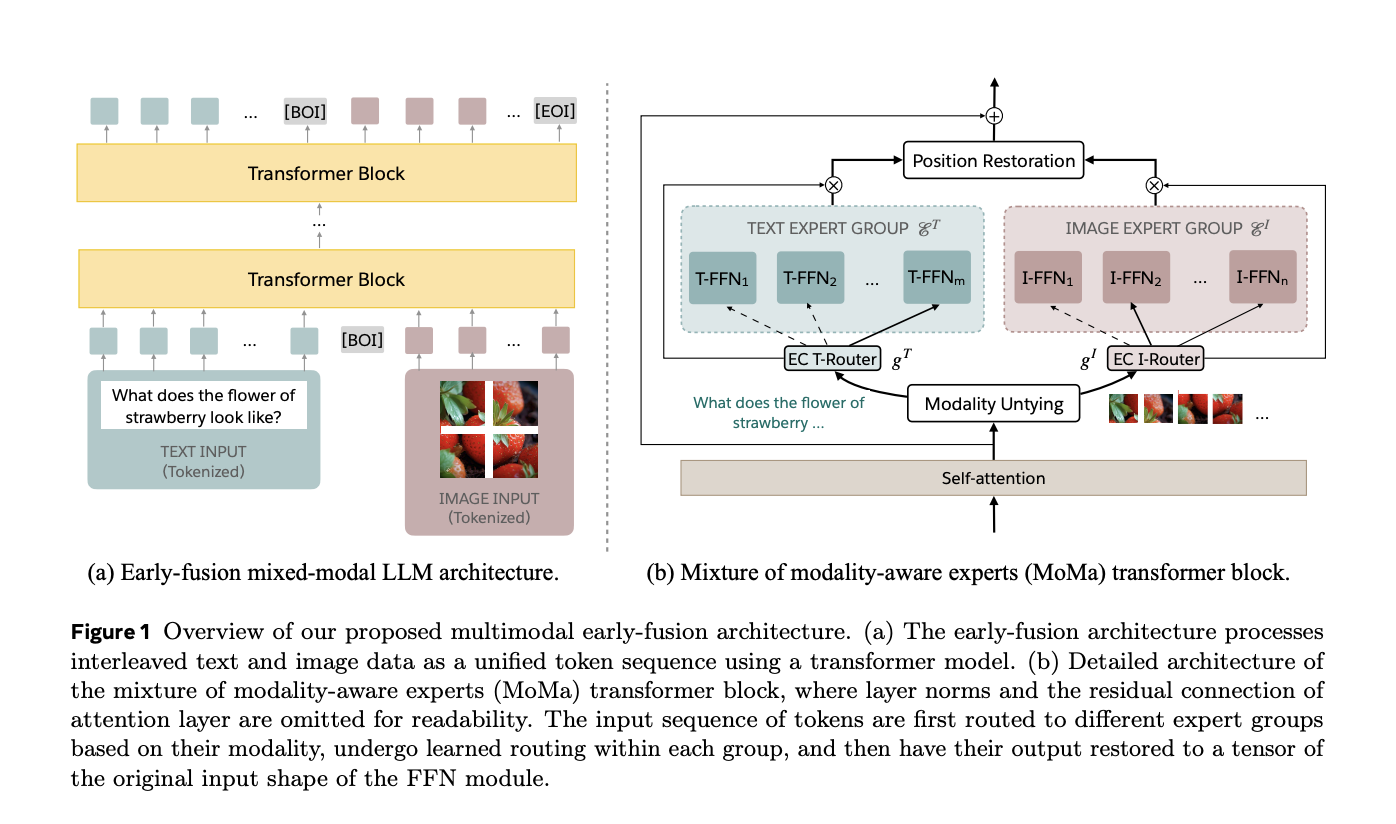
MoMa: эффективная архитектура предварительного обучения
Для решения этих вызовов исследователи из Meta разработали MoMa, новую модально-осознанную архитектуру смеси экспертов (MoE), предназначенную для предварительного обучения смешанных модальных языковых моделей с начальным слиянием. MoMa обрабатывает текст и изображения в произвольных последовательностях, разделяя модули экспертов на модально-специфические группы. Каждая группа исключительно обрабатывает назначенные метки, используя изученную маршрутизацию в каждой группе для поддержания семантически информированной адаптивности. Эта архитектура значительно улучшает эффективность предварительного обучения, как показывают эмпирические результаты. Проведенные исследования команды в Meta демонстрируют потенциал MoMa для развития смешанных модальных языковых моделей.
Технология MoMa: комбинация методик MoE и MoD
Технология MoMa объединяет методы смеси экспертов (MoE) и смеси глубин (MoD). В MoE метки маршрутизируются через набор прямых блоков (экспертов) на каждом уровне. Эксперты разделены на группы, специфичные для текста и изображения, что позволяет использовать специализированные пути обработки. Этот подход, называемый маршрутизацией, улучшает способность модели захватывать особенности, специфичные для каждой модальности, сохраняя при этом интеграцию между модальностями через общие механизмы само-внимания. Кроме того, MoD позволяет меткам выбирать, пропускать вычисления на определенных уровнях, дополнительно оптимизируя эффективность обработки.
Эффективность MoMa
Эффективность MoMa была широко оценена и продемонстрировала значительные улучшения в эффективности и эффективности. При бюджете обучения 1 трлн токенов модель MoMa 1.4B, включающая 4 текстовых эксперта и 4 изображения эксперта, достигла 3,7-кратного общего сокращения операций с плавающей точкой в секунду (FLOPs) по сравнению с плотной базовой моделью. В частности, было достигнуто сокращение на 2,6 раз для текста и на 5,2 раз для обработки изображений. Совместно с MoD общее сокращение FLOPs увеличилось до 4,2 раз, с улучшением обработки текста на 3,4 раза и изображений на 5,3 раза. Эти результаты подчеркивают потенциал MoMa для значительного улучшения эффективности предварительного обучения смешанных модальных языковых моделей с начальным слиянием.
Инновационная архитектура MoMa
Инновационная архитектура MoMa представляет собой значительное достижение в многомодальном ИИ. Путем интеграции модально-специфических экспертов и продвинутых техник маршрутизации исследователи разработали более ресурсоэффективную модель ИИ, которая сохраняет высокую производительность в различных задачах. Это инновационное решение решает критические проблемы вычислительной эффективности, предлагая путь к разработке более способных и ресурсоэффективных многомодальных систем. Работа команды демонстрирует потенциал для будущих исследований, основанных на этих основах, исследования более сложных механизмов маршрутизации и расширения подхода к дополнительным модальностям и задачам.
Заключение: перспективы MoMa для многомодального ИИ
Архитектура MoMa, разработанная исследователями в Meta, предлагает многообещающее решение для вычислительных вызовов в многомодальном ИИ. Подход использует методики модально-осознанных смесей экспертов и смесей глубин для достижения значительных улучшений эффективности, сохраняя при этом надежную производительность. Этот прорыв открывает путь к следующему поколению моделей многомодального ИИ, которые могут обрабатывать и интегрировать различные типы данных более эффективно и эффективно, улучшая способность ИИ понимать и взаимодействовать с сложным, многомодальным миром, в котором мы живем.
Проверьте статью. Вся благодарность за это исследование исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему подполью 47 тыс. подписчиков
Находите ближайшие вебинары по ИИ здесь
Arcee AI выпустил DistillKit: открытый, легко используемый инструмент для трансформации дистилляции моделей для создания эффективных высокопроизводительных небольших языковых моделей
Данное исследование в области ИИ от Meta FAIR представляет MoMa: модально-осознанную архитектуру смеси экспертов для эффективного многомодального предварительного обучения, появилось сначала на MarkTechPost.